Московский государственный открытый университет им. В.С. Черномырдина
Опубликован: 22.08.2012 | Доступ: свободный | Студентов: 9051 / 5039 | Оценка: 4.20 / 3.40 | Длительность: 26:36:00
Темы: Экономика, Менеджмент
Специальности: Администратор информационных систем
Лекция 7:
Технология баз информации. Информационное обеспечение процессов управления в экономике
7.3. Внутримашинное информационное обеспечение. Базы данных и их применение для решения экономических задач
Внутримашинное информационное обеспечение АРМ — это внемашинное ИО, которое размещается в памяти компьютера в соответствии с определённой моделью. Оно может быть организовано в форме файлов, баз данных, хранилищ данных, баз знаний (рис.7.4).
Поскольку внутримашинное ИО — это внемашинное ИО, перенесённое в память компьютера, содержательно элементы этих видов ИО соответствуют друг другу. Исторически первой среди перечисленных форм появилась файловая организация данных, ориентированная на обработку с помощью языков программирования под управлением какой-либо операционной системы.
Файл — это последовательное отображение однородных управленческих документов на машинном носителе в виде записей. Запись отражает один документ либо его строку, если документ многострочный. Запись состоит из полей, в которых находятся реквизиты документа (коды поставщиков, даты, суммы и т.д.).

Для обработки файл должен характеризоваться структурой, т.е. именем для его поиска, количеством полей в записи, последовательностью фиксации полей в записи, типом записи (постоянная или переменная длина записи), типом поля (символьное или числовое), длиной поля (количество разрядов), ключом доступа.
Ключи доступа, используемые для поиска нужных записей, могут быть первичными и вторичными. Ключ называется первичным, если с его помощью отыскивается одна запись, и вторичным, если больше одной.
Для обращения каждый файл должен иметь имя (не более 8 символов) и расширение, уточняющее его назначение: ЕХЕ, СОМ— программные файлы, готовые к использованию; DBF— файлы базы данных; DOC, TXT— текстовые файлы и т.д. По содержанию выделяют файлы данных и программные файлы.
Структура файла соответствует структуре управленческого документа из внемашинного ИО. Поэтому они группируются следующим образом:
- входные оперативные — содержат переменную информацию, отражающую текущие производственно-хозяйственные факты;
- условно-постоянные — содержат нормативно-справочные данные;
- результирующие — содержат результаты расчётов;
- корректирующие — содержат данные для корректировки условно-постоянных данных.
Однако файловая система обладает рядом серьёзных недостатков: во-первых, чрезмерная избыточность данных, являющаяся причиной возрастания затрат на их корректировку; во-вторых, высокая зависимость прикладных программ от изменения структуры файлов. Эти недостатки предопределили появление баз данных.
База данных — это множество данных, структурированных в памяти компьютера таким образом, что достигаются их минимальная избыточность и максимальная независимость от прикладных программ. Данные в базе находятся в памяти в соответствии с некоторой моделью.
В процессе управления предприятиями и организациями широко используются таблицы, поэтому наиболее распространённой моделью баз данных в настоящее время является реляционная модель.
Реляционная модель — это множество нормализованных взаимосвязанных таблиц. Связи между таблицами поддерживаются с помощью либо первичных ключей этих таблиц, либо первичного ключа одной таблицы и неключевых реквизитов другой таблицы. Нормализация таблиц позволяет производить над ними операции реляционной алгебры, т.е. операции выбора, соединения, объединения, разности, пересечения и т.д. Примером реляционной базы данных могут служить нормализованные таблицы, приведенные на рис.7.7.
Для того чтобы над таблицами реляционной базы данных можно было производить перечисленные операции, они должны удовлетворять ряду правил их построения:
- таблица должна иметь имя (например, "ДЕТАЛЬ", "ПОСТАВЩИК", "ПОСТАВКИ");
- таблица должна быть простой, т.е. не содержать составных столбцов: например, у поставщика должен быть только один номер телефона; если таковых несколько, то заполняется несколько строк;
- в таблице не должно быть одинаковых строк;
- должен быть известен первичный ключ, используемый для поиска или выполнения других логических операций.
Тогда операцию выбора в базе данных "ПОСТАВКИ" можно продемонстрировать следующим образом: требуется найти поставщиков, которые поставляли деталь с кодом 101. Формально такую команду можно записать так (табл. 7.1).
Выбрать из базы данных ПОСТАВКИ [код детали = 101].
В результате будет получено (табл. 7.1).
Согласно приведённому определению, базы данных должны создаваться таким образом, чтобы достигался минимум затрат на корректировку данных и на перепрограммирование, необходимое в результате изменения структуры базы данных. Поэтому базы данных создаются на основе двух принципов: 1) неизбыточность и 2) независимость.

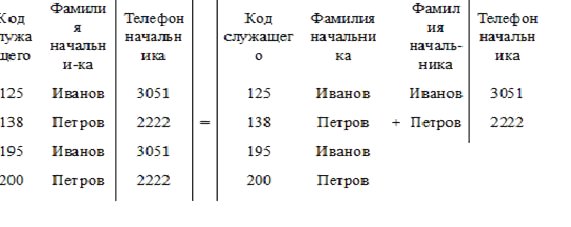
Требование первого принципа означает сокращение до минимума объёма дублируемых данных. Для этого над таблицами выполняют процедуру нормализации. Пусть имеется ненормализованная таблица "СЛУЖАЩИЙ-НАЧАЛЬНИК—ТЕЛЕФОН", в которой имеются излишне дублируемые данные (рис.7.5). Чтобы их ликвидировать, требуется деление исходной таблицы на более простые.
В результате нормализации избыточные данные, отражающие номера телефонов (3051, 2222), из таблицы "НАЧАЛЬНИК" исчезли.
Реализация второго принципа, требующего от структуры базы данных максимальной независимости прикладных программ, достигается за счёт отделения её описания от прикладной программы.
Отделение происходит с помощью системы управления базами данных (СУБД). СУБД — это комплекс программ, предназначенный для создания и хранения базы данных, обеспечения логической и физической целостности данных, предоставления к ней санкционированного доступа конечных пользователей. Отделение описания базы данных от прикладной программы представлено на рис.7.6.
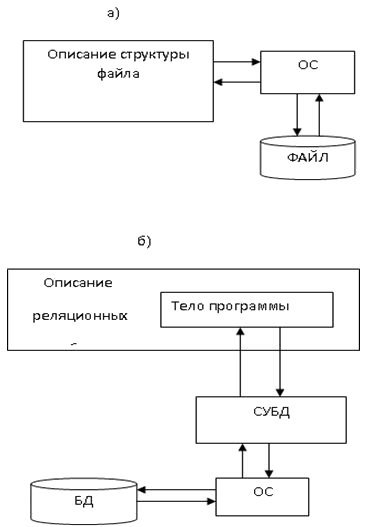
Рис. 7.6. Иллюстрация реализации второго принципа создания баз данных: а - программа на языке Pascal; б - программа в среде Access
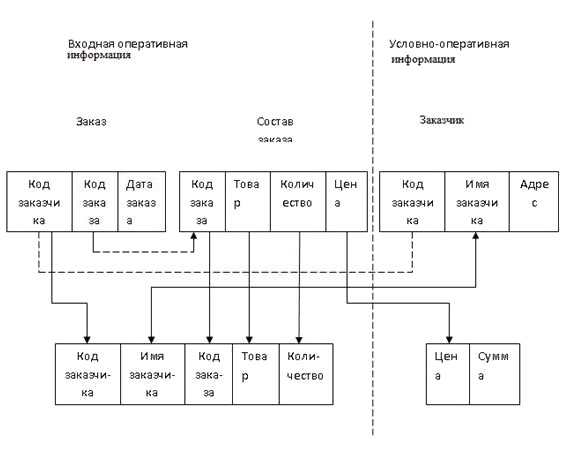
Для решения задач с помощью реляционных баз данных, прежде всего, необходимо множество документов, используемых для решения задачи, разделить на входные оперативные, отражающие текущие финансово-хозяйственные операции, и условно-постоянные (нормативно-справочные). Затем следует определить модель БД, нормализовав, если нужно, используемые таблицы, описать их структуру и указать связи между таблицами с помощью средств СУБД. В результате получают реляционную модель БД.
Согласно полученному описанию, базу данных наполняют входной информацией, после чего она готова для решения задач: получения ведомостей, сводок, диаграмм и т.д. Пример БД приведён на рис.7.7, где пунктирными стрелками показаны связи между ключевыми полями БД, устанавливаемые для поиска нужной информации, а сплошными стрелками — направления передачи информации для получения сводки.
Решение задач с помощью СУБД может осуществляться в двух режимах:
- режим конечного пользователя с применением конструктора баз данных и запросов;
- программный режим, предполагающий знание пользователем языка СУБД и позволяющий создавать прикладные программы.
Конечный пользователь, как правило, применяет конструктор, с помощью которого задаются структура БД, формулы для расчётов и структура отчёта. Программный режим предполагает создание программ с помощью программистов - профессионалов.
Актуальное направление в развитии БД — разработка методов и средств интеграции их с информационными ресурсами Интернета и создание на этой основе Интранета. Как известно, с помощью Интернета можно получить неструктурированную текстовую информацию, представленную в виде HTML-страниц. Эти страницы хранятся на Web - серверах.
Применение этой информации сводится к разработке соответствующих методов построения Web - интерфейсов для взаимодействия информационных ресурсов Интернета и БД. Под таким взаимодействием понимается: 1) публикация информации из БД в сети Интернет, т.е. преобразование формата БД в формат HTML-страниц; 2) получение информации из Интернета, т.е. преобразование формата HTML - страниц в формат, воспринимаемый СУБД.
7.4. Централизованные и распределённые базы данных и их применение для решения экономических задач
С появлением и развитием корпоративных и иных сетей появилась возможность организации доступа к одним и тем же данным из различных структурных подразделений предприятия или из других регионов. При этом разработаны два вида баз данных — централизованные и распределённые.
Централизованная БД характеризуется тем, что полностью находится на центральном компьютере, к которому пользователи (клиенты) обращаются за информацией с помощью своих компьютеров. Управление базой данных (её корректировка и прочие процедуры, поддерживающие её целостность, безопасность и др.) осуществляется централизованно (рис.7.8).
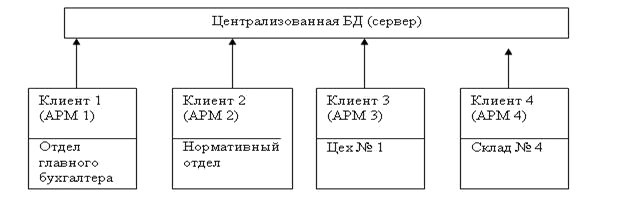
Один компьютер, располагающий ресурсами, называется сервером. Компьютер, который обращается к серверу за данными или за требованиями решения задачи, называется клиентом.
Недостатки централизованной БД: необходимость передачи большого потока данных, низкая надёжность и низкая производительность.
Преимущества: минимальные затраты на корректировку.
Для снижения остроты перечисленных недостатков создают распределённые базы данных, т.е. БД, части которых находятся в различных узлах сети. Предприятия сами по себе имеют распределённую структуру, поэтому данные фактически распределены по структурным подразделениям. Отсюда ИС должны содержать распределённую базу данных, которая должна отражать структуру предприятия. Фактически распределенная БД есть виртуальный объект, составные части которого хранятся в разных узлах сети. Для пользователя они находятся в одной логической модели базы данных.
На рис.7.9 представлена полностью распределенная БД. Стрелки указывают направление передачи данных, необходимых для решения задач в конкретном узле:
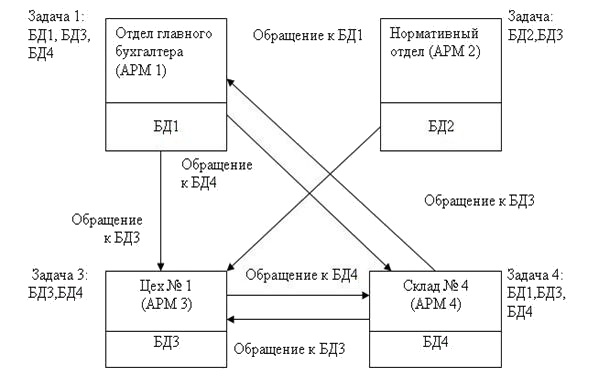
- для решения задачи 1 в отделе главного бухгалтера требуются базы данных БД 1, БД З, БД 4;
- для решения задачи 2 в нормативном отделе требуются базы данных БД 2, БД З;
- для решения задачи 3 в цехе № 1 требуются базы данных БД З, БД 4;
- для решения задачи 4 на складе № 4 требуются базы данных БД 1, БД З, БД 4.
Полностью распределённая БД создается в тех случаях, когда частота решения всех задач и объёмы передаваемых данных для их решения примерно одинаковы.
Однако если частота решения одних задач очень отличается от частоты решения других и при этом объёмы передаваемых данных остаются прежними, то можно пойти на дублирование некоторых данных, тем самым сократив затраты на их передачу. Тогда получают частично распределённую базу данных.
Например, пусть задачи 1 и 4 существенно чаще решаются по сравнению с задачами 2 и 3. Такое положение дел требует создания частично распределённой БД (рис.7.10). Дублирование данных позволяет резко сократить объёмы передаваемых данных, но увеличить затраты на их корректировку.
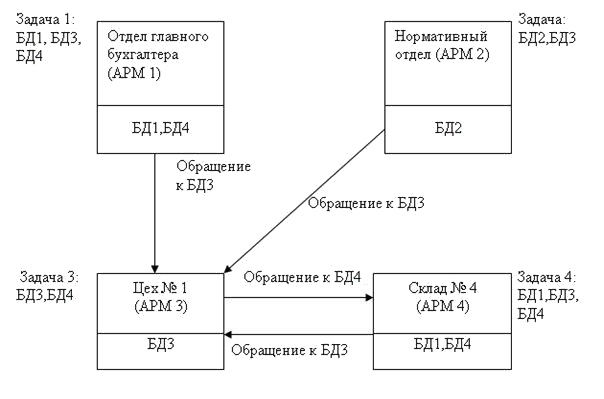
Главный критерий распределения данных в сети состоит в следующем: данные должны находиться там, где существует наибольшая частота обращения к ним.
Для решения экономических задач в среде централизованной или распределённой базы данных можно воспользоваться одним из следующих методов: доступ на основе архитектуры сети видов "файл — сервер" и "клиент — сервер".
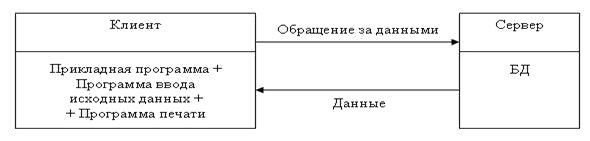
Доступ на основе архитектуры сети вида "файл — сервер". Схематично такой метод доступа представлен на рис.7.11.

В процессе решения задач пользователя, который использует доступ вида "файл — сервер", будет передаваться, кроме необходимых данных, и сопутствующая информация.
Пример. Пусть общая база данных (БД) БУИС хранится на сетевом сервере. Тогда согласно данной технологии для запуска программы печати журнала-ордера к счету "Касса" будут передаваться все проводки, среди которых нужно будет выбрать те, что касаются счёта "Касса". Если потребуются сведения о каком-либо основном средстве, то с сервера будет передан весь файл инвентарных карточек, среди которых следует отыскать нужную информацию. Если поступит запрос о начисленной заработной плате какого-либо сотрудника, то с сервера будет передан файл со всеми сотрудниками, в котором необходимо отыскать нужную запись.
Таким образом, файл-серверная обработка — это обработка данных преимущественно на рабочих местах клиентов. Сетевое программное обеспечение занято лишь передачей данных на рабочую станцию.
Доступ на основе архитектуры сети вида "клиент — сервер". В данной архитектуре возможны следующие варианты доступа:
- доступ к удаленным данным (ДУД);
- доступ с помощью сервера баз данных (СБД);
- доступ с помощью сервера приложений (СП).
- Согласно модели ДУД на компьютере клиента располагаются программа ввода исходных данных, программа, осуществляющая решение задачи на основе дополнительно поступивших с сервера данных, и программа печати результатов. Если запущена программа "Касса", то будут переданы лишь те проводки, которые необходимы для обработки и печати журнала-ордера (рис.7.12).
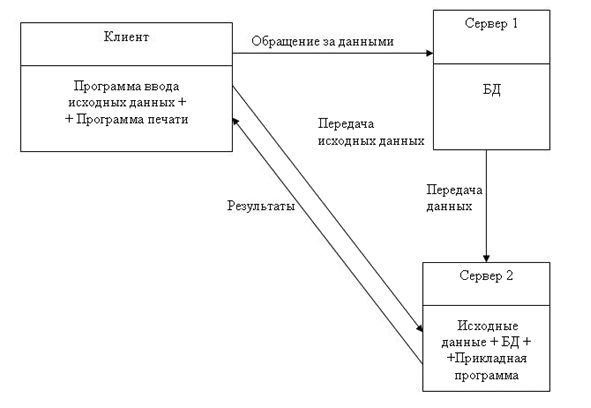
- Согласно модели СБД на компьютере клиента находятся программы ввода исходных данных и печати. Программа решения задачи находится на сервере, где, собственно, и происходит её запуск. На компьютере клиента осуществляется лишь ввод исходных данных и печать результатов (рис.7.13).
- Согласно модели СП ввод, передача, обработка и печать результатов выполняются так же, как и в модели СБД, за исключением того, что прикладная программа и исходные данные находятся на одном сервере, а БД — на другом (рис.7.14).

Виталий Елин
|
Здравствуйте! Здесь вначале говориться что выдается диплом, а внизу страницы сказано что нет |
{kind=link}
{kind=link}