Опубликован: 12.11.2012 | Доступ: свободный | Студентов: 2257 / 527 | Длительность: 18:29:00
Тема: Менеджмент
Специальности: Администратор информационных систем, Менеджер
Лекция 13:
Домен "Эксплуатация и сопровождение": управление конфигурацией и проблемами
DS 10. Управление проблемами
Эффективное управление проблемами требует выявления и классификации всех проблем, анализа их первопричин и последующего их решения. Проблема (Problem) – в ИТ неизвестная причина, лежащая в основе одного или многих инцидентов[1].Процесс управления проблемами также включает в себя формулирование рекомендаций по совершенствованию, поддержке учета проблем и изучение статуса корректирующих действий. Эффективный процесс управления проблемами максимизирует доступность систем, ведёт к повышению уровней обслуживания, сокращению затрат и повышению комфорта и удовлетворенности пользователей. Процесс Управления проблемами тесно связан с процессом Управления инцидентами, так как возникновение инцидентов происходит вследствие наличия проблем. Эти процессы часто используют одни инструменты, системы категорирования и расстановки приоритетов и т.п. Также как и процессы Управления инцидентами и Управления изменениями, Управление проблемами предоставляет ценность для бизнеса тем, что повышает доступность и качество услуг. Если проблема, порождающая инцидент, решена, бизнес выиграет от уменьшения времени простоя услуг и уменьшения негативного влияния на бизнес-системы. Управление проблемами также уменьшает издержки бизнеса на разрешение инцидентов, так как непосредственно уменьшает их количество[5].
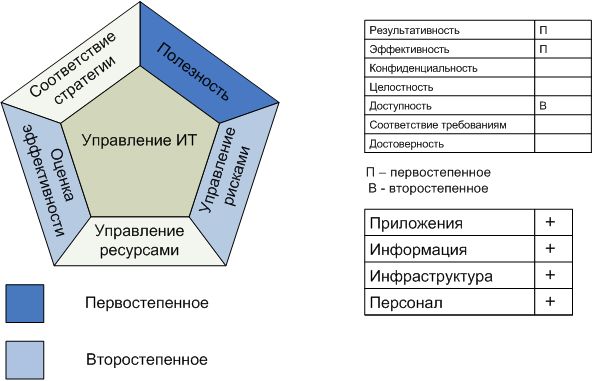
Управление проблемами.
удовлетворяет следующим бизнес требованиям к ИТ
обеспечение удовлетворенности конечных пользователей предложением услуг и уровнями обслуживания, сокращение дефектов и переделок в предлагаемых услугах.
сосредоточено на
Учёте, отслеживании и разрешении проблем в среде промышленной эксплуатации; анализе первопричин всех существенных проблем и определении путей решения выявленных эксплуатационных проблем.
достигается с помощью
- Проведения анализа первопричин выявленных проблем.
- Анализа тенденций.
- Назначения владельцев проблем и интенсификации их решения.
результаты оцениваются с помощью следующих показателей
- Число повторяющихся проблем, имеющих последствия для бизнеса.
- Доля проблем, решенных в течение определенного периода времени.
- Регулярность отчетов или обновлений, касающихся текущих проблем, ранжированных по их серьезности.
Процесс Управления проблемами схематически изображен на рис.13.4. Порядок действий взят из публикаций ITIL, которые также рассматривают этот процесс.
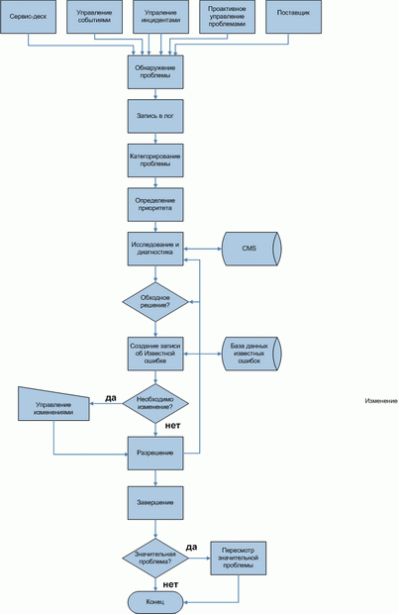
Первый этап - обнаружение проблемы. Существует множество путей обнаружения проблем, в частности:
- обнаружение или "подозрение" причины возникновения одного или более инцидентов от сервис-деска. Сервис-деск может разрешить инцидент, но не выявить его первопричину, что увеличивает вероятность возникновения аналогичных инцидентов в дальнейшем. В этом случае формируется запись о проблеме для поиска основной причины инцидента;
- анализ инцидента технической группой поддержки, в результате которого будет выявлено существование проблемы или вероятность ее существования;
- автоматическое обнаружение сбоев приложений или компонентов инфраструктуры, которое выявит необходимость создания записи о проблеме;
- уведомление о существовании проблемы от поставщика или подрядчика;
- анализ инцидентов как часть проактивного управления инцидентами.
После обнаружения проблемы, информацию о ней необходимо занести в лог, то есть сформировать запись о проблеме. Запись о проблеме должна отражать детальное описание проблемы и весь ее жизненный цикл, в частности:
- информация о пользователе;
- информация об услуге;
- информация об оборудовании;
- время и дата начала формирования записи;
- описание инцидента, который стал результатом существования проблемы;
- детальное описание всех деятельностей в рамках решения проблемы.
Для определения приоритета проблемы необходимо также оценить ее "тяжесть" или то, насколько она серьезна для инфраструктуры:
- систему можно восстановить или она должна быть заменена?
- сколько это будет стоить?
- сколько людей и какой квалификации необходимо для решения проблемы?
- сколько времени займет решение проблемы?
- насколько велик охват проблемы? ( например, сколько конфигурационных единиц она затрагивает)
На следующем этапе проводятся исследование и диагностика проблемы. Целью исследования является поиск первопричины проблемы. Для оценки точки сбоя и определения уровня негативного влияния может использоваться CMDB. База известных ошибок может быть использована для поиска случаев возникновения проблемы в прошлом, и, возможно, ее решения.
Иногда полезным может быть попытка воссоздания сбоя в тестовой среде для выяснения его причины и поиска наиболее эффективного пути ее устранения. Существует множество стандартных техник для анализа, диагностики и решения проблем. Приведем техники, рассматриваемые в публикации ITIL:
- хронологический анализ. Когда возникает сложная проблема, могут появиться противоречивые отчеты и сообщения относительно того, что действительно случилось. Для восстановления картины документально фиксируют хронологию всех событий, связанных с проблемой. Это помогает также выяснить зависимости и устранить из цепочки события, которые не относятся к рассматриваемой проблеме.
- Анализ потерь (Pain Value Analysis) - методика, используемая для идентификации влияния на бизнес одной или нескольких проблем. Формула расчета потерь основана на количестве затронутых пользователей, продолжительности простоя, влияния на каждого пользователя, и стоимости для бизнеса (если известно).
- Анализ Кепнера и Трего - системный подход к разрешению проблем. Проблема анализируется в терминах Что, Где, Когда и Сколько. Определяются возможные причины. Наиболее вероятная причина подвергается проверке. Таким образом определяется истинная причина.
- "Мозговой штурм" - методика, которая помогает команде генерировать идеи. При этом идеи не должны критиковаться и анализироваться во время проведения самого Мозгового штурма, это происходит после.
- Диаграмма Ишикавы - методика, помогающая команде определить все возможные причины проблемы. Первоначально была разработана Каору Ишикавой (Kaoru Ishikawa), результатом работы этой методики является диаграмма[5]. Основная проблема изображается в виде ствола диаграммы, главные факторы - как ветки, вторичные факторы - как соплодие и т.д. Создание диаграммы стимулирует обсуждение проблемы и более глубокое понимание ее сложности.
- анализ Парето - методика отделения значимых причин возникновения проблемы от незначимых. Должны быть предприняты следующие действия:
- сформировать таблицу, содержащую причины проблемы и их частоту в процентном соотношении от общего количества случаев возникновения проблемы;
- упорядочить строки таблицы в порядке увеличения важности причин;
- добавить столбец совокупного процента.
Более понятным анализ Парето будет на примере из публикации ITIL. В таблице 13.5 приведены 10 причин отказа сетевых взаимодействий, то есть "падения сети".
Далее необходимо сделать следующие шаги:Таблица 13.5. "Падение сети" Причины Процент от общего количества (%) Расчет Совокупный процент (%) Сетевой контроллер 35 0+35 35 Порча файлов 26 35+26 61 Конфликт адресации 19 61+19 80 ОС Сервера 6 80+6 86 Ошибки скриптов 5 86+5 91 Непротестированное изменение 3 91+3 94 Ошибки оператора 2 94+2 96 Сбой резервного копирования 2 96+2 98 Попытки вторжения 1 98+1 99 Сбой дисков 1 99+1 100 - создать столбиковую диаграмму причин, расположенных в соответствии с их Процентом от общего количества ( 2 столбец);
- наложить линию суммарного процента (4 столбец).
- нарисовать линию от 80 % совокупного процента к оси y, параллельно оси x. В точке пересечения с линией суммарного процента "уронить" ее на ось x. Точка оси x, на которую "упадет" линия отделит значимые причины от незначимых.
Александр Медов
|
Здравствуйте, прошел курс МБА Управление ИТ-проектами и направил документы на получение диплома почтой. Подскажите, сроки получения оного в бумажной форме? : |