
|
Вроде легкие вопросы и ответы знаю правильные, но система считает иначе и правильные ответысчитает неправильными. Приходится выполнть по несколько раз. Это я не правильно делаю или тест так составлен? |
Российский Новый Университет
Опубликован: 25.01.2016 | Доступ: свободный | Студентов: 2266 / 175 | Длительность: 16:40:00
Лекция 15:
Перспективы использования Django
Поиск Django с помощью Elasticsearch
Поиск стал неотъемлемой частью большинства приложений, с которыми мы имеем дело сегодня. От Facebook для поиска друга, до Google, где вы ищете по всему Вебу, все от блога до журнала требует возможностей поиска для разблокировки скрытой информации на веб-сайте.
Веб развивается с экспоненциальной скоростью. Мерить данные гигабайтами теперь уже устарело и сотни терабайт структурированных и неструктурированных данных генерируется каждый день.
Elasticsearch (ES) лучше, чем другие альтернативы, потому что, помимо полнотекстового поиска, он обеспечивает полноценную аналитику данных в реальном времени и масштабируемость, с мощной поддержкой инфраструктуры данных кластеров.
Elasticsearch (ES) также дает вам простой REST API, который можно легко интегрировать с любым пользовательским приложением и окружение разработки Django (в более широком смысле, Python) дает много крутых, из коробки, инструментов для имплементации Elasticsearch (ES).
Веб-сайт Elasticsearch (ES) (http://www.elasticsearch.org/) содержит подробную документацию и там есть много замечательных онлайн-примеров, которые помогут вам построить любые виды поиска, которые вам нужны. Путем полного использования Elasticsearch, вы, вероятно, сможете построить свой собственный "Google" с его помощью.
Установка сервера Elasticsearch
Во-первых, установите Java. Затем скачайте и распакуйте Elasticsearch. Вы можете либо запустить ES как службу или вы можете стартовать ES сервер, используя следующие команды оболочки (измените пути в соответствии с вашей системой):
Set JAVA_HOME = \absolute\path\to\Java \absolute\path\to\ES\bin\elasticsearch
Если все сделано правильно, можно набрать следующий URL-адрес в вашем браузере:
Это даст вам ответ следующим образом, но с различным параметром build_hash:
{
"status" : 200,
"name" : "MN-E (Ultraverse)",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.4.1",
"build_hash" : "89d3241d670db65f994242c8e8383bl69779e2d4",
"build_timestamp" : "2014-11-26T15:49:29Z",
"build_snapshot" : false,
"lucene_version" : "4.10.2"
},
"tagline" : "Вы знаете, это все для поиска"
}
Elasticsearch поставляется с базовой конфигурации для базового развертывания. Однако если вы хотите настроить конфигурацию, обратитесь к онлайн документации и измените конфигурацию Elasticsearch в файле elasticsearch.yml.
Взаимодействие между Elasticsearch и Django
Django может быть интегрирован с Elasticsearch с помощью базового программирования Python. В этом примере мы будем использовать библиотеку запросов Python для того, чтобы сделать запрос от Django к Elasticsearch. Мы можем установить запросы, введя следующий код:
pip install requests
Для функции поиска, есть главным образом три операции, которые мы должны выполнить:
- Создать индекс Elasticsearch.
- Наполнить индекс данными.
- Получить результаты поиска.
Создание индекса Elasticsearch
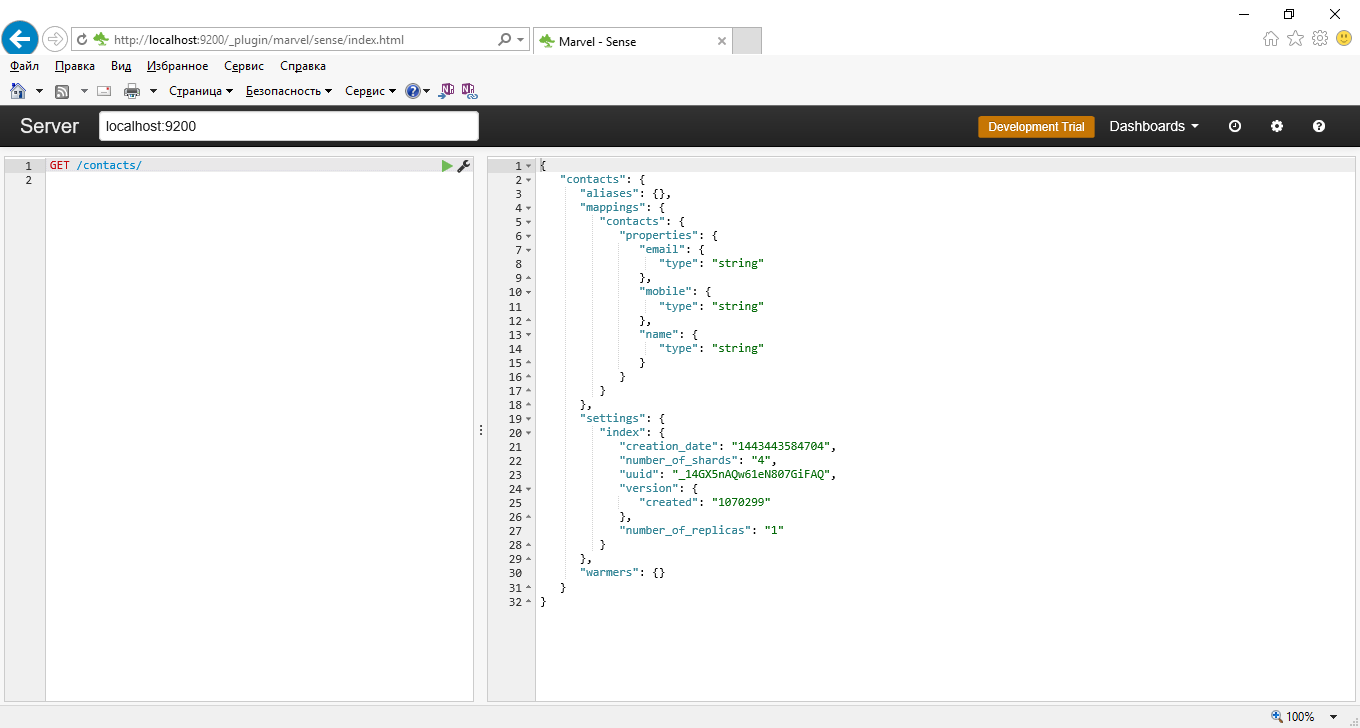
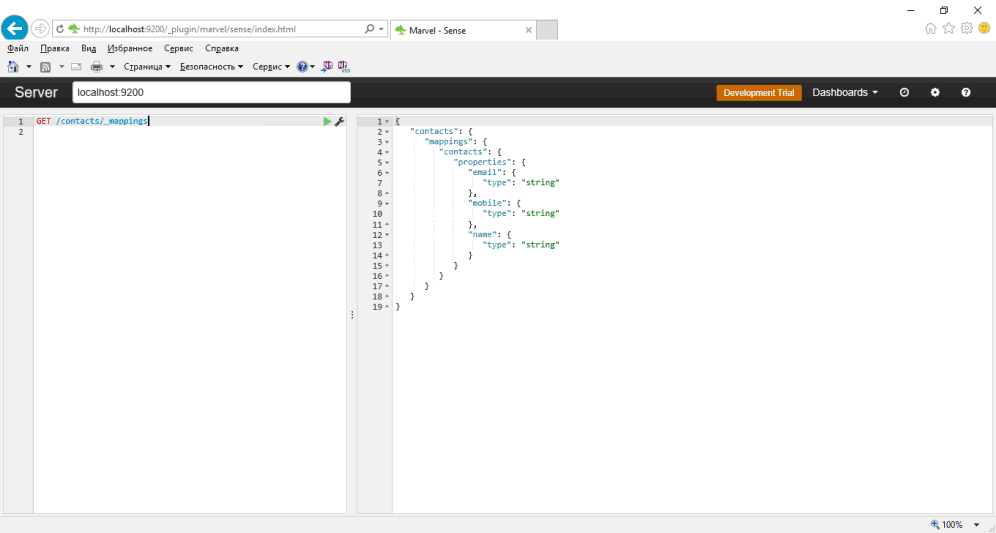
Перед загрузкой индекса Elasticsearch с текстом и получением результатов поиска, Elasticsearch должен знать некоторые детали о вашем содержимом и то,как следует рассматривать данные. Таким образом, мы создаем индекс ES, который состоит из параметров и отображений. Отображения в ES являются эквивалентом моделей Django — поля данных определяются для вашего содержимого.
Хотя отображения совершенно необязательны, так как Elasticsearch динамически создает отображение для информации, которую он получил для индексации, но рекомендуется заранее определить отображение данных для индексирования.
Примером Python для создания индекса ES является следующий код:
data = {
"settings": {
"number_of_shards" : 4,
"number_of_replicas": 1
},
"mappings": {
"contacts" : {
"properties" : {
"name": { "type": "string" },
"email": { "type": "string" },
"mobile": { "type": "string" }},
"_source": {
"enabled": "true"
}
}
}
}
}
import json, requests
response = requests.put('http://127.0.0.1:9200/contacts/', data=json.
dumps(data))
print response.text
Вывод приведенного выше кода показан на следующем скриншоте:
После того, как мы создали наш первый индекс Elasticsearch, мы создали в JSON словарь с информацией и поместили дамп этой информации в Elasticsearch через запросы Python. Параметр "contacts" — это имя индекса, которое мы выбрали, и мы будем использовать это имя для накопления и извлечения данных от сервера Elasticsearch. Ключ "mappings" описывает, какие данные ваш индекс будет содержать. Мы можем иметь столько различные отображений, сколько хотим. Каждое отображение содержит поле, в котором хранятся данные, точно так же, как модели в Django. Некоторыми из основных полей являются строка, число, данные, Boolean и так далее. Полный список приводится в документации Elasticsearch. Параметры "shards" и "replicas" разъясняются в глоссарии ES. Без ключа "settings", ES будет просто использовать значения по умолчанию — в большинстве случаев это идеально подходит.
Наполнение индекса данными
Теперь, когда вы создали индекс, давайте сохраним содержимое внутри него. Пример кода Python для воображаемой модели BlogPost, которая содержит заголовок, описание и содержание как текстовые поля является следующим:
import json, requests
data = json.dumps (
{"name": "SERGEY KOBZEV",
"email": "tilllindemann85@outlook.com",
"mobile": "8892572775"})
response = requests.put(‘ http://127.0.0.1:9200/contacts/contact/1’, data=data)
print response.text
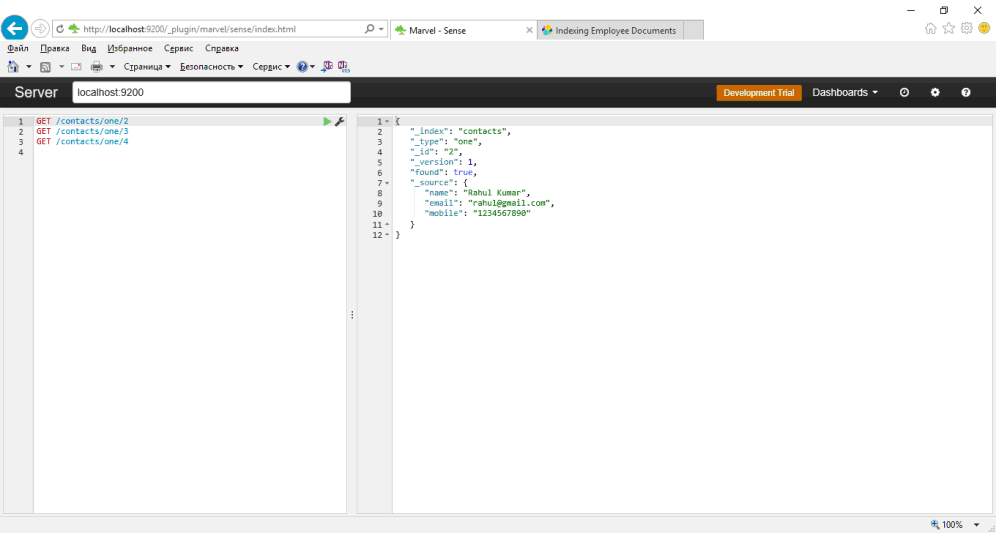
Давайте взглянем на следующий скриншот:
Это показывает, что наши контактные данные были проиндексированы. Конечно в индексации данных и поиска не так много смысла, поэтому мы проиндексируем больше контактов, прежде чем мы сделаем запрос поиска.
Elasticsearch также предоставляет основную индексацию, которая может быть использована следующим образом:
import json, requests
contacts = [
{"name": "Rahul Kumar",
"email": "rahul@gmail.com",
"mobile": "1234567890"},
{"name": "Sanjeev Jaiswal",
"email": "jassics@gmail.com"
"mobile" : : "1122334455"},
{"name": "Raj" ,
"email": "raj ©gmai1.com",
"mobile": : "0071122334"},
{"name": "Shamitabh",
"email": "shabth@gmail.com",
"mobile": : "9988776655"}
for idx, contact in enumerate(contacts): data += '{"index": {"_id": "%s"}}\n' % idx data += json.dumps({
"name": contact["name"],
"email": contact["email"],
"mobile": contact ["mobile"]
})+'\n'
Как вы можете видеть на предыдущем снимке экрана, параметр "status": 201, который в статусе HTTP означает, что запись успешно создана. Elasticsearch считывает данные построчно, поэтому мы использовали "\n" в конце каждого набора данных. Массовые операции гораздо быстрее, чем выполнение несколько раз одного запроса.
Этот пример представляет собой простой пример JSON. Когда мы используем Elasticsearch с нашим приложением Django, один и тот же объект JSON может быть заменен моделью Django и индексировав модель, вы можете получить все объекты модели Django от запроса ModelName.objects.all(), а затем распарсить и сохранить его. Кроме того, в случае ручного идентификатора, как мы использовали в предыдущем примере, которым является индекс счетчика, будет гораздо удобнее, если вы используете первичный ключ для индексации его в качестве идентификатора Elasticsearch. Это поможет нам непосредственно запросить результат объекта, если мы не передаем информацию объекта как полезные данные.
Константин Боталов
Владимир Филипенко
|
Листинг показывает в 4-ой лекции, что установлен Django 1.8.4. Тут же далее в этой лекции указаны настройки, которые воспринимает Django 1.7 и младше. |