Лексический анализ
Lex
Существует целый ряд инструментов для создания лексических анализаторов; большинство этих инструментов основывается на регулярных выражениях. Одним из традиционных средств подобного рода является Lex, состоящий из Lex-языка и Lex-компилятора. На самом деле запись спецификаций на языке Lex полезна даже тогда, когда Lex компилятор не доступен, поскольку эти спецификации могут быть без особого труда преобразованы в программу вручную. На данный момент, компиляторы Lex существуют на многих платформах и, несомненно, в ближайшее время появятся и на платформе .NET.
Процесс использования Lex'а выглядит следующим образом: cпецификации лексического анализатора на языке Lex подготавливаются в виде программы lex.l. Затем этот файл обрабатывается Lex компилятором, в результате чего создается программа на языке программирования. Большинство существующих реализаций генерируют программы на С и потому в дальнейшем рассмотрении средства Lex мы будем подразумевать использование С, хотя с тем же успехом можно было бы использовать и любой другой язык, например, C#.
Сгенерированная программа состоит из табличного представления диаграмм переходов, построенных по регулярным выражениям, и стандартных подпрограмм, которые используют эти таблицы для разбора лексем. Действия, связанные с реакцией на встреченные регулярные выражения, пишутся непосредственно на С и обычно помещаются сразу же за самими правилами. Затем эта программа обрабатывается компилятором С, в результате чего создается объектная программа, которая и является лексическим анализатором.

Структура Lex-программы
Lex-программа состоит из трех частей: описаний, правил трансляции и процедур. Каждая часть отделяется от следующей строкой, содержащей два символа %%.
Секция описаний включает описания переменных, констант и регулярных определений. Раздел описаний содержит определения макросимволов (метасимволов) в виде:
ИМЯ ВЫРАЖЕНИЕ
Если в последующем тексте в регулярном выражении встречается {ИМЯ}, то оно заменяется на ВЫРАЖЕНИЕ. Если строка описаний начинается с пробелов или заключена в скобки %{ ... }%, то она просто копируется в выходной файл.
Регулярные определения - это последовательность определений вида
d1 r1 … dn rn,
где каждое di - некоторое имя, а каждое ri - регулярное выражение над алфавитом
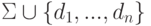
Правила трансляции - это операторы вида
p1 {action1}
…
pn{actionn}где pi - регулярное выражение, actioni - фрагмент программы, описывающий, какие действия должен выполнять лексический анализатор для лексемы, определяемой pi.
Третья секция содержит процедуры, выполняемые при разборе. В частности, здесь описывается функция yywrap(), которая определяет, что делать при достижении автоматом конца входного файла. Ненулевое возвращаемое значение приводит к завершению разбора, нулевое - к продолжению (перед продолжением, естественно, надо открыть какой-нибудь файл как yyin ). Вообще говоря, эти процедуры могут быть скомпилированы отдельно.
Способы записи регулярных выражений в Lex-программе
Рассмотрим способы записи регулярных выражений во входном языке Lex'а. Символ из входного алфавита, естественно, представляет регулярное выражение из одного символа. Специальные символы (в том числе +-*?()[]{}|/\^$.<> ) записываются после префикса \. Символы и цепочки можно брать в кавычки, например допустимы следующие три способа кодирования символа а: а, "а" и \а.
Имеется возможность задания класса символов:
[0-9] или [0123456789] - любая цифра
[A-Za-z] - любая буква
[^0-7] - любая литера, кроме цифр от 0 до 7
. - любая литера, кроме \nГрамматика для записи регулярных выражений (в порядке убывания приоритета):
<р>* - повторение 0 или более раз
<р>+ - повторение 1 или более раз
<р>? - необязательный фрагмент
<р><р> - конкатенация
<р>{m,n} - повторение от m до n раз
<р>{m} - повторение m раз
<р>{m,} - повторение m или более раз
^<р> - фрагмент в начале строки
<р>$ - фрагмент в конце строки
<р>|<р> - любое из выражений
<р>/<р> - первое выражение, если за ним следует второе
(р) - скобки, используются для группировкиПример. Регулярное выражение ^[^aeiou]*$ означает любую строку, не содержащую букв a, e, i, o .