На основе графового представления
Покрытие ациклических графов (DAGов)
Если ослабить ограничение, что у одного узла дерева --- максимум один родитель, то вместо деревьев мы получим представление с помощью направленных ациклических графов (англ. Directed Acyclic Graph). За счет наличия нескольких родителей можно представлять значения, которые являются аргументами нескольких других выражений одновременно. Шаблонам теперь также разрешено иметь несколько корней, что позволяет осуществить поддержку инструкций со множественными результатами.
Так как DAGи менее ограничительны чем деревья, то для них можно применять новые подходы для порождения кода. Основных два
- Разделить DAG на деревья, породить код и объединить получившиеся результаты.
- Сопоставлять с образцам непосредственно граф, используя алгоритмы изоморфизма графов. В общем случае алгоритмы экспоненциально сложны, но зачастую они работают за линейное время.
Сложность
Задача оптимального порождения кода по представлению в форме DAG NP-полна :cite:`Koes2008`. Доказать это можно сведя (за полиномиальное время) задачу SAT к задаче выбора шаблона в DAG.
Жадные подходы
Порождение кода на основе DAG применяется в компиляторе LLVM, но исследование деталей затруднено тем, что основная документация --- исходный код. Согласно :cite:`Bendersky2013`, порождение кода состоит из последовательного переписываться DAG, где инструкции промежуточного представления заменяются на машинные инструкции.
В LLVM шаблоны-деревья записываются на специальном языке, который компилируются в специальный предметно-ориентированные языки (bytecode), который осуществляет анализ представления программы. Все шаблоны перед компиляцией сортируются:
- по убыванию сложности, на которую влияет размер паттерна, и специальные константы, которые эвристически дают приоритет некоторым паттернам;
- по возрастанию стоимости порожденного кода;
- по возрастанию размера подграфа, который покрывается шаблоном.
Так как в шаблонах участвуют только деревья, то инструкции с множественными выходами генерировать не получится, для них нужен отдельный ad hoc алгоритм порождения. Также, за счет особенностей жадных алгоритмов, они не могут претендовать на оптимальность.
Также в LLVM присутствуют два других подхода к выбору инструкций: FastISel и GlobalISel, который позволяет порождать также и межблоковые инструкции.
Методы выбора инструкций для DAGов
Методы можно условно разделить на те, которые адаптируют подходы для деревьев, и на все остальные. Можно придумывать эвристики, которые преобразуют граф без циклов в деревья так, чтобы затраты на копирование узлов были незначительны или отсутствовали. Также можно адаптировать методы на основе динамического программирования.
Также существуют методы, специфические для задачи оптимального выбора инструкций для графов без циклов. Они могут быть основаны на сведение задачи выбора к задаче оптимизации какой-либо предметной области. Были попытки сведения к задаче линейного программирования, MWIS (англ. maximum weighted independent set) проблемам, а также задаче программирования в ограничениях (англ. constraint programming), и др. Исследовалось :cite:`Beg2013` введение глобальных ограничений для решения задачи оптимального порождения кода с помощью программирования в ограничениях, и пришли к выводу, что для простых архитектур (MIPS и ARM) оптимальные решения примерно так же эффективны как и полуоптимальные на основе LLVM. Скорее всего для RISC-V можно ожидать таких же результатов.
Ограничения покрытия DAGов
Графы без циклов являются обобщением деревьев. С помощью них можно непосредственно моделировать общие подвыражения, и большее разнообразие инструкций, а именно с множественными выходами и непересекающимися выходами, что существенно улучшает производительность и размеры кода. Подходы на основе покрытия DAGов сейчас наиболее распространенные.
Цена этому заключается в том, что оптимальный результат больше не получить за линейное время, так как задача становится NP-полной. В то же время, DAGи недостаточно выразительны, чтобы промоделировать все аспекты программ. Например, циклы for не представимы как ациклические графы, что не позволяет моделировать инструкции, затрагивающие сразу несколько блоков графа потока управления программ.
Покрытие графов
Некоторые конструкции языков программирования, например циклы, не ложатся в представление с помощью DAGов. Поэтому существует наиболее общая форма представления программ с помощью графов, где присутствует информация и о данных, и о потоке управления программы. Порождение инструкций для таких графов называется глобальным порождением инструкций (англ. global instruction selection), потому что учитывается информация не только в одном базовом блоке программы, а в нескольких блоках сразу. К тому же, появляются возможности передвигать инструкции из одного блока в другой (англ. global code motion), и выбирать межблоковые инструкции. Это делает графы наиболее мощным инструментом для порождения кода для архитектур, где много специализированных инструкций (например, различные DSP).
int i = 0;
while (i < N) {
int a = A[i];
int b = B[i];
int c = a + b;
if (MAX < c)
c = MAX;
C[i] = c;
i++;
}
Граф потока управления для вычисления насыщенной суммы двух массивов.
% !TEX TS-program = xelatex
% !TeX spellcheck = ru_RU
% !TEX root = cfg1satsum.tex
\documentclass[tikz,border=3.14mm]{standalone}
\usepackage{amssymb}
%\xdefinecolor{mycolor}{RGB}{62,96,111} % Neutral Blue
%\colorlet{bancolor}{mycolor}
\newcommand{\assn}[2]{\ensuremath{#1\leftarrow#2}}
\newcommand{\load}{\ensuremath{\texttt{load\ }}}
\newcommand{\cbr}{\ensuremath{c\texttt{\textbf{.br\ }}}}
\newcommand{\br}{\ensuremath{\texttt{\textbf{br\ }}}}
\newcommand{\store}{\texttt{\textbf{store\ }}}
%\usetikzlibrary{shadows.blur}
\def\lab#1 {
\node [right%,inner xsep=.5em
, outer sep=0pt
, text height=1ex
, text depth=.0ex] (caption#1)
at ([shift={(-1.5em,0pt)}]b#1.north west) {b#1};
}
%\newcommand{\FixedLengthArrow}{2,0}
\begin{document}
\begin{tikzpicture}[
%, node distance = 5mm
% start chain = going below,
, box/.style = {draw
%,rounded corners
%, blur shadow
, fill=white
%, on chain
, align=left
}]
\node[box] at (0, 3) (b1) {
$\assn{i}{0}$\\
\textbf{br }b2
};
\node[box] at (0, 1) (b2) {
$\assn{t_1}{i\leqslant N}$\\
\cbr $t_1$, b3, end
};
\node[box] at (0, -2) (b3) {
$\assn{t_2}{i\times 8}$\\
$\assn{A}{t_2}$\\
$\assn{a}{\load t_3}$\\
$\assn{t_4}{B + t_2}$\\
$\assn{b}{\load t_4}$\\
$\assn{c}{a+b}$\\
$\assn{t_5}{\texttt{MAX}\leqslant c}$\\
\cbr $t_5$, b4, b5
};
\node[box] at (-0.5, -5) (b4) {
$\assn{c}{\texttt{MAX}}$\\
\br$b5$
};
\node[box] at (2, -5.5) (b5) {
$\assn{t_6}{C+t_2}$\\
\store$t_6,\ c$\\
$\assn{i}{i+1}$\\
\br b
};
\lab{1} \lab{2} \lab{3} \lab{4} \lab{5}
% \mynode{4}{$\assn{c}{\texttt{MAX}}$\\\br$b5$}
% {at (3,-20)}
% \mynode{5}{$a<N$\\
% \store$t_6, c$\\
% $\assn{i}{i+1}$\\
% \br b2}
% {at (0,-10)}
\begin{scope}[rounded corners,-latex]
\path %(b3.-40) edge[bend right=50] (b4.40)
(b1) edge (b2) ;
\path (b2) edge (b3);
\path (b3) edge (b4);
\path (b3) edge (b5);
\path (b4) edge (b5);
%\path (b5) edge (b6);
\draw (b5.230) -- ++(-.3,-0.3) -| ([xshift=-7mm]b2.west) --
(b2);
\end{scope}
\end{tikzpicture}
\end{document}
Пример выше посвящен использованию межблоковых инструкций, а именно операции взятия максимума двух чисел, доступной в том числе для RISC-V. Одна такая инструкция могла бы заменить сравнение с максимумом, ветвление и полностью убрать блок b4, что сократило бы размер кода с 16 до 13 инструкций (почти 25%).
В программе выше также присутствуют четыре сложения, которые не зависят друг от друга. Если начать передвигать инструкции между блоками, можно добиться применения векторных (или SIMD) инструкции, которая сделает четыре сложения одновременно. Если затраты на копирование и подготовку данных (англ. data copying) для векторных инструкций незначительны, то автовекторизация ещё больше сократит затрачиваемые такты.
Решение задачи поиска проверки через изоморфизм графов
Методы для DAG не масштабируются для графов, поэтому для графов нужны свои алгоритмы поиска подходящих шаблонов. Для выбора оптимального шаблона можно использовать алгоритмы, подходящие для DAGов. Задача изоморфизма графов проверяет, можно ли исходный грaф поворачивать, перекручивать или зеркально отображать так, чтобы в нём нашелся искомый подграф. Эта задача является обобщением поиска шаблонов для DAG при наличии разумных ограничений. Например, шаблоны для коммутативных операций (сложение или умножение) можно зеркально отображать, чтобы операнды поменялись местами, а для вычитания или деления --- нет.
В литературе задача изоморфизма графов встречается в различных областях и известны методы её решения. Например, алгоритм Ульмана :cite:`Ullmann1976` имеет сложность в худшем случае O(n!n^2), а алгоритм VF2 :cite:`Cordella2001` --- O(n!n).
Промежуточные представления на основе Sea-of-Nodes
Функции, так как в них используется граф потока управления, мы вынуждены представлять с помощью графов. По соглашению, представления для них называются sea-of-nodes.
Static Single Assignment
Если каждая переменная присваивается только один раз, то можно говорить, что программа находится в SSA-форме :cite:`Cytron1991`. Проведение оптимизаций в такой форме более удобно, чем без неё. Например, в программе можно исследовать промежутки активности переменных (англ. live range), которые неформально обозначают места для в программе, где значения переменных нужны и их нельзя удалять. Для SSA формы эти промежутки непрерывны и по сути упрощаются до одного промежутка (за счет размножения количества переменных).
В примере ниже приведена реализация и SSA-форма факториала на языке Си. В ней используются так называемые ?-функции, которые присваивают значение переменной в зависимости от того, из какого блока к данной точке программы пришло исполнение. На основе SSA-представления функций можно строит SSA-графы :cite:`Gerlek1995`, которые напоминают графы потока данных. Каждой операции соответствует узел графа, а рёбра обозначают поток данных, игнорируя факты того, что данные могут быть в разных базовых блоках графа потока управления. Такие SSA-графы не являются самостоятельными объектами в компиляторах, их используют вместе с графами потока управления для представления программ.
int factorial (int n) {
entry:
int f = 1;
head:
if (n <= 1) goto end;
body:
f = f * n;
n = n - 1;
goto head;
end:
return f;
}
int factorial (int n1 ) {
entry:
int f1 = 1;
head:
int f2 =  (f1: entry, f3: body);
int n2 = (n1: entry, n3: body);
if (n2 <= 1) goto end;
body:
int f3 = f2 * n2;
int n3 = n2 - 1;
goto head;
end:
return f2;
}
(f1: entry, f3: body);
int n2 = (n1: entry, n3: body);
if (n2 <= 1) goto end;
body:
int f3 = f2 * n2;
int n3 = n2 - 1;
goto head;
end:
return f2;
}
Пример SSA-графа для факториала
% !TEX TS-program = xelatex
% !TeX spellcheck = ru_RU
% !TEX root = ssa_graph1.tex
\documentclass[tikz,border=3.14mm]{standalone}
\pgfdeclarelayer{background}
\pgfsetlayers{background,main}
\usepackage{tikz, amssymb, comment}
\usetikzlibrary {graphs,shapes.geometric}
\usetikzlibrary{positioning}
\def\mynode#1#2 {
\node[box] (b#1) {#2};
\node [right,inner xsep=.5em
, outer sep=0pt,text height=1ex,text depth=.0ex] (caption#1)
at ([shift={(-1em,0pt)}]b#1.north west) {#1};
}
\begin{document}
%\begin{comment}
\newcommand\mytikzcontents{
\node[leaf] at ( 0, 0) (M1) {$n_1$};
\node[leaf] at ( 1,-1) (M2) {$\varphi$};
\node[leaf] at ( 0,-2) (M3) {$\leqslant$};
\node[leaf] at (-1,-1) (M4) {$1$};
\node[leaf] at ( 2,-3) (M5) {$-$};
\node[leaf] at ( 3,-2) (M6) {$1$};
\node[leaf] at ( 5,-2.5) (M7) {$\times$};
\node[leaf] at ( 6,-1) (M8) {$\varphi$};
\node[leaf] at ( 5, 0) (M9) {$1$};
\node[leaf] at ( 7,-2) (M10) {$ret$};
\draw[->,thick] (M1) -- (M2);
\draw[->,thick] (M4) -- (M3);
\draw[->,thick] (M2) -- (M3);
\draw[->,thick] (M2) -- (M5);
\draw[->,thick] (M5) .. controls ++(1:-1) and ++(-90: 1) .. (M2);
\draw[->,thick] (M6) -- (M5);
\draw[->,thick] (M9) -- (M8);
\draw[->,thick] (M8) -- (M7);
% \draw[->,thick] (M7.south) -- (8,-3) -- (8,-1) to (M8.east);
\draw[->,thick] (M7.east) to [bend right=90] (M8.south);
\draw[->,thick] (M2.east) -- (3.5,-1) to [out=0,in=135] (M7);
\draw[->,thick] (M8) -- (M10);
}
\begin{tikzpicture}
[ every tree node/.style={draw,circle}
, sibling distance=25pt
, level distance=30pt
, leaf/.style={circle,fill=blue,fill opacity=0.3,text opacity=1}
, dot/.default = 6pt % size of the circle diameter
]
\mytikzcontents
\end{tikzpicture}
\newcommand \mytikzcfgpart{
\node[draw] at (-3, 0) (bE) {\textbf{\texttt{entry}}};
\node[draw] at (-3, -1) (bH) {\textbf{\texttt{head}}};
\node[draw] at (-3, -3) (bIf) {\textbf{\texttt{if}}};
\node[draw] at (-4, -4) (bBody){\textbf{\texttt{body}}};
\node[draw] at (-2, -4) (bFin) {\textbf{\texttt{fin}}};
\draw[->, line width=.45mm] (bE) -- (bH);
\draw[->, line width=.45mm] (bH) -- (bIf);
\draw[->, line width=.45mm] (bIf) -- (bBody);
\draw[->, line width=.45mm] (bIf)-- (bFin);
\draw[->, line width=.45mm] (bBody) to [bend left =60] (bH);
\draw[thick, ->, dashed] (bFin) to [bend right=20] (M10);
\draw[thick, ->, dashed] (bH) to [bend left=40] (M8);
\draw[thick, ->, dashed] (bH) to [bend left=20] (M2);
\draw[thick, ->] (M3) to [bend left =20] (bIf);
}
\begin{tikzpicture}
[ every tree node/.style={draw,circle}
, sibling distance=25pt
, level distance=30pt
, leaf/.style={circle,fill=blue,fill opacity=0.3,text opacity=1}
, dot/.default = 6pt % size of the circle diameter
]
\mytikzcontents;
\mytikzcfgpart
\end{tikzpicture}
%\end{comment}
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
\newcommand \UniDataFlow{
\node[draw] at ( 0.5, -1.5) (DFmaxL) {\texttt{MAX}};
\node[leaf, circle] at ( 1.2, -2.2) (DFless) {<};
\node[draw] at ( 2, -1.5) (DFd1) {$d_1$};
\node[leaf, circle] at ( 2.8, -2.2) (DFphi) {$\varphi$};
\node[draw] at ( 3.6, -1.5) (DFmaxR) {\texttt{MAX}};
\node[draw] at ( 1.2, -3) (DFempty) {\phantom{$d_3$}};
\node[draw] at ( 2.8, -3) (DFd3) {$d_3$};
\node[draw, circle] at ( 2, -.5) (DFplus) {$+$};
\node[draw] at ( 1.2, 0.2) (DFs) {$s$};
\node[draw] at ( 2.8, 0.2) (DFt) {$t$};
\draw[->] (DFs) -- (DFplus);
\draw[->] (DFt) -- (DFplus);
\draw[->] (DFplus) -- (DFd1);
\draw[->] (DFmaxL) -- (DFless);
\draw[->] (DFmaxR) -- (DFphi);
\draw[->] (DFd1) -- (DFless);
\draw[->] (DFd1) -- (DFphi);
\draw[->] (DFless) -- (DFempty);
\draw[->] (DFphi) -- (DFd3);
}
\newcommand \UniCFG{
\node[draw] at (-3, 0.5) (bE) {\textbf{\texttt{entry}}};
\node[draw, diamond] at (-3, -1) (bCBR) {\textbf{\texttt{c.br}}};
\node[draw] at (-1, -1) (bClamp) {\textbf{\texttt{clamp}}};
\node[draw, diamond] at (-1, -2) (bBR) {\textbf{\texttt{br}}};
\node[draw] at (-1, -3) (bFin) {\textbf{\texttt{fin}}};
\draw[->, line width=.45mm] (bE) -- (bCBR);
\draw[->, line width=.45mm] (bCBR) -- (bClamp);
\draw[->, line width=.45mm] (bClamp) -- (bBR);
\draw[->, line width=.45mm] (bBR)-- (bFin);
\draw[->, line width=.45mm] (bCBR) to [bend right=40] (bFin);
\draw[->, dotted] (bE) to [bend left=30] (DFd1);
\draw[->, dotted] (bFin) to [bend right=40] (DFd3);
\draw[->] (DFempty) -- (0,-3) -- (0,-.5) to (bCBR.north east);
}
\begin{tikzpicture}
[ every tree node/.style={draw,circle}
, sibling distance=25pt
, level distance=30pt
, leaf/.style={circle,fill=blue,fill opacity=0.3,text opacity=1}
, dot/.default = 6pt % size of the circle diameter
]
\UniDataFlow
\UniCFG
\end{tikzpicture}
\end{document}
Также существует представление :cite:`Click1995`, объединяющее SSA граф и граф потока управления. Такое представление используется в Java Hotspot Server Compiler (JHSC), где граф разбивается на, возможно, пересекающиеся деревья выражений. Корни деревьев выбираются так, чтобы они представляли собой общие подвыражения, или операции у которых есть побочный эффект, который не может быть раскопирован. А сами деревья выбираются так, чтобы попытаться их представить одной машинной инструкцией. Учитывая, что операции всё ещё представлены деревьями, инструкции с множественными результатами так породить не получится.

Пример графа Клика-Палечны, соответствующий факториалу. Тонкие линии объединяют операции над данными и поток данных. Толстые линии обозначают рёбра графа потока управления. Пунктирные линии обозначают принадлежность операций блокам.
Универсальное представление
Одной из последних работ по выбору инструкций является подход :cite:`Blindell2018` на основе универсального порождения инструкций (англ. Universal Instruction Selection). Оно является дальнейшим усложнением графов Клика-Палечны, что делает его достаточно полным, чтобы на нём проводить выбор инструкций. В частности, туда добавляются:
- Операции для явного изменения потока управления в графе потока управления.
- В граф потока данных добавляются узлы для конкретных значений (англ. value nodes), к уже имеющимся узлам для вычислений (англ. computation nodes)
- Операции над данными соединяются с блоками, где они происходят.
- Объявления новых переменных с помощью
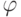 -функций также соединяются с блоками, где они происходят.
-функций также соединяются с блоками, где они происходят. - Узлы для конкретных констант, используемых в операциях. Такие узлы раскопируются, если они используются в разных блоках, потому что присутствует ограничение, что одно и то же значение не может быть использовано одновременно в разных блоках.
- Так называемые state nodes, которые запрещают переставлять некоторые операции с неявными зависимостями, например, вызовы функций с побочными эффектами
- Номера ребер, чтобы упростить задачу поиска шаблонов в графе, так как при упорядоченных рёбрах она решается эффективнее.
По сравнению с графами Клика-Палечны, в универсальном представлении все операции надо потоком данных и управления представлены в виде узлов, что дает больше информации. Поиск шаблонов осуществляется с помощью изоморфизма графов. Если для конкретного шаблона находятся несколько подходящих подграфов, то это возможность использования инструкций с дизъюнктными результатами (SIMD или векторные), при условии, что подграфы не пересекаются и нет циклических зависимостей по данным. В предыдущих подходах такое было неосуществимо.
Данный подход был реализован, как дополнение к LLVM 3.8, и протестирован на DSP процессорах Hexagon. К сожалению, дело не дошло до реальной практической апробации, по видимому, вместо процессора используется его эмулятор, а оценка качества кода дается только статическим вычислением стоимости. Апробация подхода для RISC-V --- это задача будущего.

Пример универсального представления для функции сложения с насыщением.
int satadd (int s, int t) {
entry:
int d1 = s + t;
if (d1 > MAX) goto clamp;
clamp:
int d2 = MAX;
end:
int d3 = (d3: entry, d2: clamp);
return d3;
}