|
Здравствуйте,при покупке печатной формы сертификата,будут ли выданы обе печатные сторны? |
Московский физико-технический институт
Опубликован: 24.09.2008 | Доступ: свободный | Студентов: 4823 / 2475 | Оценка: 4.52 / 4.48 | Длительность: 25:15:00
Темы: Программирование, Менеджмент
Специальности: Системный архитектор
Лекция 7: Формальные спецификации, доказательство и верификация программ
Разработка спецификации проводится по следующей схеме:
- Определение терминов, которыми будет специфицироваться программа.
- Описание понятий и объектов, для обозначения которых используется денотат, идентифицируемый с помощью некоторого имени (или фразы).
- Описание инвариантных свойств программы.
- Определение операций над структурами программы (например, ввести объект, удалить и др.), изменяющие ее состояние и сохранение инвариантных свойств.
При переходе от одного шага детализации к другому модель программы детализируется и постепенно становится ближе к конечному описанию. Функции - это операции, которые уточняются при детализации структуры программы на каждом шаге спецификации и описания поведения модели.
При реальном выполнении спецификация исполняется итерационно. На первом уровне проверяется только свойства модели программы при заданных ограничениях независимо от среды. Затем используется уточненная и расширенная спецификация с набором формальных утверждений. И так до тех пор, пока окончательно не будет завершен процесс пошагового доказательства спецификации.
Для демонстрации возможностей VDM языка рассмотрим задачу поиска ("Поиск") в каталоге
( 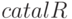 ) репозитария компонентов имени компонента
) репозитария компонентов имени компонента  и сравнения его с заданным в запросе пользователя.
В случае совпадения имен проверяются параметры, и при их совпадении из каталога извлекается код компонента и передается пользователю.
и сравнения его с заданным в запросе пользователя.
В случае совпадения имен проверяются параметры, и при их совпадении из каталога извлекается код компонента и передается пользователю.
Спецификация переменных программы "Поиск"

где  - cведения о разработчике компонента ;
- cведения о разработчике компонента ; 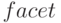 - переменная, в которую посылается код компонента, выбранного из каталога репозитария
- переменная, в которую посылается код компонента, выбранного из каталога репозитария  при совпадении имен в каталоге и запросе;
при совпадении имен в каталоге и запросе; 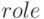 - переменная, в которой хранится текущий элемент из репозитария, найденный по
фасете компонента с номером
- переменная, в которой хранится текущий элемент из репозитария, найденный по
фасете компонента с номером  для
для 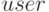 ;
;  - имя разработчика компонента;
- имя разработчика компонента; 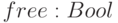 - переменная, которая используется для задания признака -
компонент не найден или к нему никто не обращался.
- переменная, которая используется для задания признака -
компонент не найден или к нему никто не обращался.
Описание инвариантных свойств программы
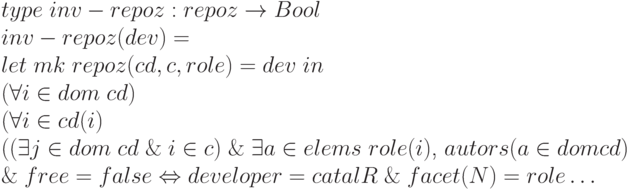
Операторы программы проверяют список имен компонентов в каталоге, который содержит элементов типа 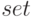 .
Если они совпадают с именем в запросе, результат сохраняется в .
.
Если они совпадают с именем в запросе, результат сохраняется в .
Доказательство инвариантных свойств программ должно проводиться автоматизированным способом с помощью специально созданных инструментальных средств поддержки VDM языка.
6.1.2. Спецификация программ средствами RAISE
RAISE-метод и RSL-спецификация (RAISE Specification Language) [6.9, 6.10] были разработаны в 80-х годах как результат предварительного исследования формальных методов и их пополнения новыми возможностями. Метод содержит нотации, техники и инструменты для конструирования программ и доказательстве их правильности. Он имеет программную поддержку в виде набора инструментов и методик, которые постоянно развиваются и используются при доказательстве правильности программ, описанных в RSL и ЯП (С++ и Паскаль). Язык RSL содержит абстрактные параметрические типы данных (алгебраические спецификации) и конкретные типы данных (модельноориентированные), подтипы, операции для задания последовательных и параллельных программ. Он предоставляет аппликативный и императивный стиль спецификации абстрактных программ, а также формальное конструирование программ в других ЯП и доказательство их правильности. Синтаксис этого языка близок к синтаксису языков С++ и Паскаль.
В RSL-языке имеются предопределенные абстрактные типы данных и конструкторы сложных типов данных, такие как произведение ( 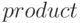 ),
множества (
),
множества ( 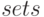 ), списки (
), списки (  ), отображения (
), отображения ( 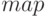 ), записи (
), записи ( 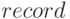 ) и т.п.
Далее рассмотрим некоторые конструкторы сложных типов данных.
) и т.п.
Далее рассмотрим некоторые конструкторы сложных типов данных.
Произведение типов - это упорядоченная конечная последовательность типов  произведения ( )
произведения ( ) 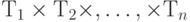 .
Представитель типа имеет вид (
.
Представитель типа имеет вид ( 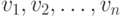 ),
где каждое
),
где каждое 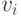 -это значение типа
-это значение типа 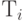 .
Компонент произведения можно получить операцией
.
Компонент произведения можно получить операцией  и переслать , т.е.
и переслать , т.е.
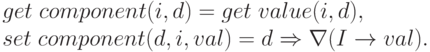
Количество компонентов произведения d находится таким образом:
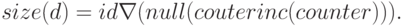
Конструктор произведения 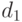 и
и 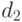 строит произведение
строит произведение  вида:
вида:

Для каждого конкретного типа 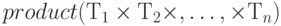 можно построить конструктор значения этого типа из отдельных компонентов произведения таким образом:
можно построить конструктор значения этого типа из отдельных компонентов произведения таким образом:

где каждое значение  имеет тип , а результирующее значение - тип произведения
имеет тип , а результирующее значение - тип произведения 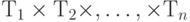
Списки типов - это последовательность значений одного типа 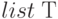 , могут быть конечным списком типов
, могут быть конечным списком типов 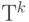 и неконечными списком типов
и неконечными списком типов 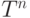 .
В качестве структур данных типа списка может быть бинарное дерево,
в котором есть голова (
.
В качестве структур данных типа списка может быть бинарное дерево,
в котором есть голова (  ) и сын (
) и сын ( 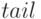 ),
который следует за ним в списке, и хвост.
К операциям списка относится операция
),
который следует за ним в списке, и хвост.
К операциям списка относится операция  - взятия первого элемента списка,
т.е. головы, и операция
- взятия первого элемента списка,
т.е. головы, и операция 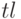 - хвоста остальных элементов (аналогично как в VDM).
- хвоста остальных элементов (аналогично как в VDM).
Функция  выбирает из списка
выбирает из списка 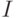 -элемент.
Индекс элемента помогает выбрать нужный элемент списка:
-элемент.
Индекс элемента помогает выбрать нужный элемент списка:
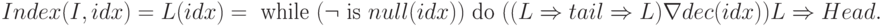
Для определения количества элементов в списке выполняется функция:
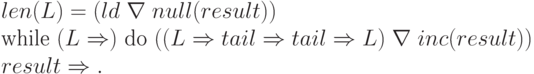
Элемент списка находится так:
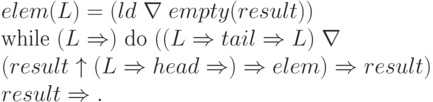
Аналогично можно представить функции конкатенации, преобразование типов данных, добавления элемента в голову и хвост списка и др.
Отображение - это структура ( ),
которая ставит в соответствие значениям одного типа значение другого типа.
Вместе с тем отображение - это бинарное отношение декартова произведения двух множеств как совокупности двухкомпонентных пар,
в которых первый компонент -  содержит элементы аргументов отображения,
а второй компонент
содержит элементы аргументов отображения,
а второй компонент  - соответствующие элементы значений этого отображения.
- соответствующие элементы значений этого отображения.
В языке имеются разные допустимые операции над отображениями: наложение, объединение, композиция, срез и др. Среди этих видов отношений рассмотрим,
например, композицию отображений (  ,
,  ):
):
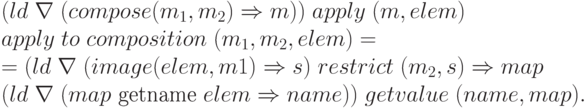
При этом используются функции:

Запись - это совокупность именованных полей.
Этот тип соответствует типу в языке Паскаль и 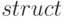 в языке С++.
В языке RAISE для записи определено два конструктора - ,
в языке С++.
В языке RAISE для записи определено два конструктора - ,  ,
описание которых имеет вид
,
описание которых имеет вид
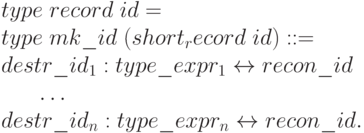
Идентификатор 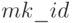 - это конструктор типа , для которого задается деструктор
- это конструктор типа , для которого задается деструктор 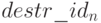 как функции получения значения компонентов записи.
как функции получения значения компонентов записи.
Объединение - это конструктор 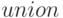 для объединения типов
для объединения типов 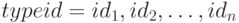 ,
при котором тип
,
при котором тип 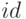 получает одно из значений
в списке элементов.
получает одно из значений
в списке элементов.
Конструктор типа имеет вид
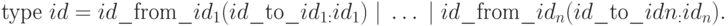
Операции над самим типом не определены в языке RAISE.
Рассмотренные формальные структуры данных языков VDM и RAISE предназначены для математического описания программ с помощью утверждений и конструирования новых структур данных, необходимых для проектируемых программ. Средства этих языков фактически - элементы спецификации программ, по которым проще проверять правильность программ методами верификации или доказательства, составляя при этом, как и в случае VDM, пред, постусловия и утверждения для проведения доказательства программы по ее спецификациям.
Александр Медов
Александр Медов
|
Здравствуйте, прошел курс МБА Управление ИТ-проектами и направил документы на получение диплома почтой. Подскажите, сроки получения оного в бумажной форме? : |