Инспектор

Вы можете этот курс.
Опубликован: 12.02.2014 | Доступ: платный | Студентов: 21 / 1 | Длительность: 11:22:00
Тема: Программирование
Специальности: Программист
Лекция 2:
Машина вывода Пролога
Аннотация: Изучается устройство вычислений в языке Пролог. Дается представление о машине вывода Пролога. Рассматривается конструкция сложных термов и понятие отрицания в языке Пролог. Показывается, как использовать трассировку в PIE и отладчик системы Visual Prolog.
Данная глава посвящена устройству вычислений в Прологе. Дается представление о машине вывода Пролога. Рассматривается конструкция сложных термов и понятие отрицания в языке Пролог. Показывается, как использовать трассировку в PIE и отладчик системы Visual Prolog.
Основными механизмами машины вывода Пролога являются унификация и откат. При унификации термов и атомарных формул находится наибольший общий унификатор. Откат используется для поиска всех решений.
2.1. Унификация
Формулы  и
и 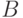 называются унифицируемыми, если существует такая подстановка
называются унифицируемыми, если существует такая подстановка 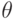 термов вместо переменных, что
термов вместо переменных, что 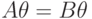 . Подстановка ? называется при этом унификатором формул и .
. Подстановка ? называется при этом унификатором формул и .
Например, формулы 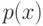 и
и  унифицирует любая из подстановок
унифицирует любая из подстановок  и
и 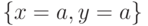 .
.
Композицией подстановок  и
и 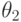 называется подстановка
называется подстановка  , которая получается из подстановки применением к ее равенствам подстановки , так что равенства
, которая получается из подстановки применением к ее равенствам подстановки , так что равенства 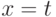 преобразуются в равенства
преобразуются в равенства 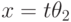 , с последующим удалением равенств вида
, с последующим удалением равенств вида  , и добавлением равенств
, и добавлением равенств 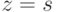 из для переменных
из для переменных 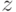 , не встречающихся в левых частях равенств
, не встречающихся в левых частях равенств 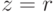 в подстановке .
в подстановке .
Например, композицией подстановок и 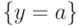 является подстановка .
является подстановка .
Унификатор формул и называется наибольшим общим унификатором, если для любого другого унификатора этих формул найдется такая подстановка 2, что  .
.
Например, наибольшим общим унификатором формул и является подстановка  . Если, в частности,
. Если, в частности, 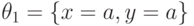 , то, взяв
, то, взяв 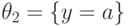 , получим:
, получим:  .
.
Построение наибольшего общего унификатора двух формул сводится к последовательному выявлению и устранению их различий.
Множество рассогласований формул и — это самая левая пара несовпадающих термов, стоящих в этих формулах на одинаковых позициях.
Например, множество рассогласований формул 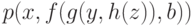 и
и 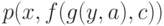 равно
равно 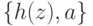 .
.
Алгоритм поиска наибольшего общего унификатора формул и заключается в следующем. На нулевой итерации полагается  ,
,  и
и 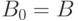 . На итерации
. На итерации  , начиная с
, начиная с 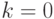 , выполняются следующие действия:
, выполняются следующие действия:
- если
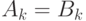 , то алгоритм завершает свою работу, и наибольший общий унификатор полагается равным
, то алгоритм завершает свою работу, и наибольший общий унификатор полагается равным 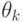 , иначе находится множество рассогласований
, иначе находится множество рассогласований 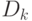 формул
формул 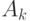 и
и 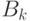 и выполняется переход к шагу 2;
и выполняется переход к шагу 2; - если содержит переменную
 и терм
и терм 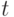 , в который не входит переменная , то строится подстановка
, в который не входит переменная , то строится подстановка 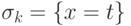 и выполняется переход к шагу 3, иначе алгоритм завершает свою работу — формулы и не унифицируемы;
и выполняется переход к шагу 3, иначе алгоритм завершает свою работу — формулы и не унифицируемы; - вычисляются формулы
 и
и  и подстановка
и подстановка  и выполняется переход к итерации
и выполняется переход к итерации  .
.
Например, найдем наибольший общий унификатор формул  и
и 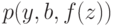 с переменными ,
с переменными ,  и
и 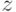 и константами
и константами  и
и  . Множество рассогласований имеет вид:
. Множество рассогласований имеет вид: 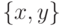 . Применим к формулам подстановку и получим формулы
. Применим к формулам подстановку и получим формулы  и . Множество рассогласований этих формул равно
и . Множество рассогласований этих формул равно 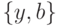 . Соответственно, применим к этой паре формул подстановку
. Соответственно, применим к этой паре формул подстановку  и получим формулы
и получим формулы 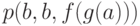 и
и 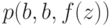 . Множество рассогласований последних формул выглядит следующим образом:
. Множество рассогласований последних формул выглядит следующим образом: 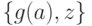 . Применим к данным формулам подстановку
. Применим к данным формулам подстановку 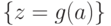 и получим полностью совпадающие формулы, равные . Наибольший общий унификатор равен композиции подстановок:
и получим полностью совпадающие формулы, равные . Наибольший общий унификатор равен композиции подстановок:
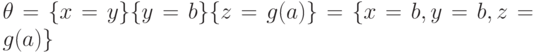 .
.
2.2. Процедурная семантика логической программы
Процедурная семантика программы отвечает на вопрос, как устроены вычисления. Вычисления в классическом случае проводятся в соответствии с методом SLD-резолюции (Selected Linear Defined Resolution) [7, 9].
Пусть 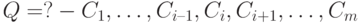 — запрос к логической программе,
— запрос к логической программе, 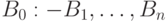 — вариант
— вариант 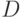 правила
правила 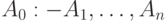 , такой что в нем и в запросе нет совпадающих переменных, и — наибольший общий унификатор формул
, такой что в нем и в запросе нет совпадающих переменных, и — наибольший общий унификатор формул 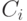 и
и 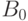 .
.
SLD-резольвентой запроса 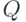 и правила с подстановкой называется запрос
и правила с подстановкой называется запрос 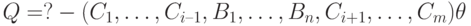 .
.
Положим  . Частичным SLD-резолютивным вычислением называется последовательность троек
. Частичным SLD-резолютивным вычислением называется последовательность троек  , в которой
, в которой 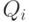 является SLD-резольвентой запроса
является SLD-резольвентой запроса  и правила
и правила  с подстановкой
с подстановкой 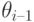 . Такое вычисление называется успешным, если на некотором шаге
. Такое вычисление называется успешным, если на некотором шаге  получается пустой дизъюнкт:
получается пустой дизъюнкт: 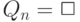 . Ответом на запрос, в случае успешного вычисления, является композиция подстановок
. Ответом на запрос, в случае успешного вычисления, является композиция подстановок 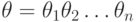 , ограниченная переменными запроса .
, ограниченная переменными запроса .
Процедурным значением программы является множество простых замкнутых целей из эрбранова базиса, которые выводятся из программы с помощью SLD-резолютивного вывода. Вернемся к программе (см. п. 1.1):
млекопитающее("слон").
млекопитающее("зебра").
животное("страус").
животное("уж").
животное(X):- млекопитающее(X).
Рассмотрим цель  . SLD-резольвентой этого запроса и правила
. SLD-резольвентой этого запроса и правила 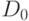 вида
вида  с подстановкой
с подстановкой 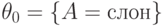 является запрос
является запрос  . SLD-резольвентной этого запроса и правила с пустым телом
. SLD-резольвентной этого запроса и правила с пустым телом  с пустой подстановкой является пустой запрос. Таким образом, цель
с пустой подстановкой является пустой запрос. Таким образом, цель  выводится из программы. Легко проверить, что все цели из минимальной модели
выводится из программы. Легко проверить, что все цели из минимальной модели  выводятся из программы, а остальные цели из эрбранова базиса не выводятся. Это верно и в общем случае: декларативное и процедурное значения классической логической программы совпадают.
выводятся из программы, а остальные цели из эрбранова базиса не выводятся. Это верно и в общем случае: декларативное и процедурное значения классической логической программы совпадают.
Пространство вычислений в классическом Прологе представляется в виде дерева, вершинами которого являются SLD-резольвенты родителя и одного из правил, а ребра соответствуют унифицирующим постановкам. Корень дерева — это цель программы. Листьями являются пустые запросы, которые завершают успешные вычисления, и запросы, не имеющие SLD-резольвент, которые завершают тупиковые вычисления (рис. 2.1). Это дерево называется деревом SLD-резолютивных вычислений.
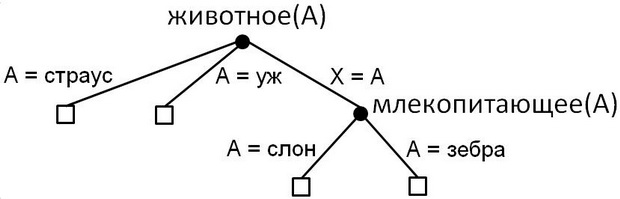
Вычисления в языке Пролог соответствуют обходу дерева в глубину. Правила программы упорядочиваются сверху вниз. Выделяется самая левая подцель запроса, затем на каждом шаге вычисления к нему применяется первое еще неиспользованное правило программы для данного предикатного символа, при этом в стеке запоминается возможное разветвление — следующее правило. Когда вычисление заходит в тупик или успешно завершается, происходит возврат в точку последнего разветвления, при этом результаты всех предыдущих подстановок отменяются. Вычисления заканчиваются, когда стек разветвлений становится пустым. Недостатком такой стратегии является существование возможности попасть на бесконечную ветвь дерева вычислений, с которой программа не может выбраться, теряется полнота вычислений. Полнотой обладает обход дерева в ширину, он обнаруживает все успешные вычисления произвольного запроса. Но обход в ширину требует слишком большого расхода памяти, поэтому стандартной стратегией вычислений в Прологе является поиск в глубину.