Опубликован: 11.03.2009 | Доступ: свободный | Студентов: 2891 / 769 | Оценка: 4.22 / 4.22 | Длительность: 11:41:00
Тема: Базы данных
Специальности: Администратор баз данных
Лекция 8:
Репликация данных. Виды и свойства репликации. Сравнение механизмов репликации в MS SQL Server 2005 и ORACLE Server 10g
Аннотация: Лекция посвящена теме репликации данных. В теоретической части рассказывается о видах и свойствах репликации, приводится сравнение механизмов репликации в MS SQL Server 2005 и ORACLE Server 10g. А также, рассматриваются практические задания по теме.
Ключевые слова: хранилище данных, непротиворечивость, причинность, FIFO, сериализуемость, операции, переменная, synchronize, элемент данных, X-протокол, кэш, координация, запись, производительность, СУБД, Oracle, репликация, конфликт, dynamic, token passing, динамическая, имя узла, owner, строка данных, ключ, алгоритм, активная, секвенсор, идентификатор, разделяемый ресурс, распределенное хранилище данных, копирование, приостановка выполнения, локальная очередь, состояние системы, протоколирование, распределенные транзакции, архивирование, удаление записей, БД, информационные системы, механизм, сеанс, транзакция, целостность, primaries, UNIQUE, селекция, проекция, workflow, кортеж, префикс, множество, разрешение конфликтов, идентификация, ограничение целостности, ущерб, priority, group, издатель, publishing, column, level, track, row, h-формула, over-current, destination, site, originate, целочисленный тип, тип данных, сложение, имя группы, собственный метод
Одной из основных характеристик хранилища данных является модель его непротиворечивости, в которой определяются какие правила необходимо соблюдать, чтобы хранилище возвращало разным процессам правильные результаты. Выделяют следующие модели непротиворечивости [1]: строгая, линеаризуемая, последовательная, причинная, FIFO, слабая, свободная и поэлементная. Рассматривается репликативный аспект последовательной, слабой и FIFO моделей непротиворечивости. Этот выбор обусловлен тем, что первые две модели обеспечивают глобальную сериализуемость операций, а последняя - довольно легко реализуема и является менее жесткой, чем первые две. В [1] приведены определения всех вышеперечисленных моделей непротиворечивости, здесь же приводятся определения только рассматриваемых моделей, необходимые для дальнейшего изложения.
Последовательная непротиворечивость определяется следующим правилом:
Результат любого действия такой же, как если бы операции (чтения и записи) всех процессов в хранилище данных выполнялись бы в некотором последовательном порядке, причем операции каждого отдельного процесса выполнялись бы в некотором последовательном порядке, определяемом его программой.
Непротиворечивость FIFO определяется следующим правилом:
Операции записи, осуществляемые единичным процессом, наблюдаются всеми остальными процессами в том порядке, в котором они осуществляются, но операции записи, происходящие в различных процессах, могут наблюдаться разными процессами в разном порядке.
Для определения слабой непротиворечивости вводится понятие переменной синхронизации. Переменная синхронизации (S) имеет ассоциированный с ней набор реплицируемых данных и позволяет выполнять над собой единственную операцию synchronize(S). В ходе выполнения этой операции изменения сделанные процессом в локальной копии данных распространяются на все остальные копии данных, ассоциированные с переменной синхронизации. Также в ходе этой операции локальная копия обновляется данными из остальных копий.
Модель слабой непротиворечивости имеет три свойства:
- Доступ к переменным синхронизации, ассоциированными с хранилищем данных, осуществляется на условиях последовательной непротиворечивости.
- С переменной синхронизации не может быть произведена ни одна операция до полного и повсеместного завершения предшествующих ей операций чтения и записи над элементами данных.
- С элементами данных не может быть произведена ни одна операция до полного завершения всех операций с переменными синхронизации.
Протокол непротиворечивости представляет собой конкретную реализацию соответствующей модели. Принято выделять следующие группы протоколов непротиворечивости [1]: на базе первичной копии, реплицируемой записи, согласования кэшей.
Протоколы на базе первичной копии, подразумевающие репликацию данных
Все протоколы на базе первичной копии подразумевают наличии для каждого элемента данных Х, ассоциированного с ним первичного элемента данных, который отвечает за координацию операций записи. В [1] выделяется два протокола поддерживающих репликацию:
Протокол первичного архивирования с удаленной записью
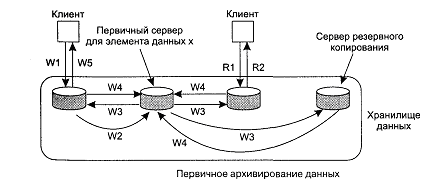
Расшифровка обозначений:
- W1 - запрос на запись
- W2 - пересылка запроса на сервер
- W3 - сигнал на обновление резервных копий
- W4 - подтверждение выполнения обновления
- W5 - подтверждение выполнения записи
- R1 - запрос на чтение
- R2 - ответ для чтения
При реализации этого протокола необходимо гарантировать, что в каждый момент времени только один узел имеет доступ к первичной копии, тем самым, имея возможность изменять данные. Существует асинхронный вариант, при котором подтверждение о выполнение записи посылается сразу после обновления первичной копии (не дожидаясь обновления всех копий). Это повышает производительность операции записи, однако требует дополнительных действий для обеспечения: гарантированного обновления всех реплик (защита от сбоев при распространении) и согласованного чтения для узла, инициировавшего обновление (он не должен иметь возможность считать значение, который имел элемент данных до записи). В случае если все первичные копии находятся на одном узле, имеем реализацию последовательной непротиворечивости, иначе не предпринимая дополнительных мер можно говорить только о непротиворечивости FIFO.
Протокол первичного архивирования с локальной записью

Расшифровка обозначений:
- W1 - запрос на запись
- W2 - перемещение элемента данных х на новый первичный сервер
- W3 - подтверждение завершения записи
- W4 - сигнал на обновление резервных копий
- W5 - подтверждение обновления
- R1 - запрос на чтение
- R2 - ответ для чтения
В протоколе подразумевается асинхронное обновление остальных копий. Здесь также необходимо предпринимать дополнительные меры, чтобы гарантировать обновление остальных реплик, однако проблемы согласованного чтения для узла, инициировавшего обновление, здесь не возникает. Без дополнительных мер протокол реализует FIFO непротиворечивость, реализовав полностью упорядоченную групповую рассылку (с помощью отметок времени Лампорта)[1], можно получить реализацию последовательной непротиворечивости. Поскольку в протоколе допускается перемещение первичной копии то необходимо решить задачи поиска узла, содержащего первичную копию и смены владельца.
Пример решения задач поиска и смены владельца первичной копии
В СУБД Oracle существует метод репликации данных, предотвращающий возникновение конфликтов[2,3], и который содержит решения двух рассматриваемых задач. В [2] он определяется как dynamic ownership with token passing (динамическое владение с переходящим маркером). В этом методе подразумевается наличие нескольких реплик табличных данных, расположенных на разных узлах, на каждом из которых установлена СУБД Oracle. К реплицируемой таблице добавляется два столбца, первый из которых содержит имя узла (owner), который владеет строкой данных, а второй номер версии строки данных (epoch). Столбец epoch используется для предотвращения конфликтов упорядочивания при асинхронной рассылке изменений.
Алгоритм поиска первичной копии
Поиск начинается с локально узла. Считывается значение столбца owner для заданной строки данных, идентифицируемой своим ключом. Если значение owner совпадает с именем локального узла (того на котором осуществляется чтение), то узел является владельцем первичной копии и поиск заканчивается. Если не совпадает, то считывается значение из строки, находящейся на узле, имя которого было считано на предыдущем этапе. Этот процесс продолжается до тех пора не будет найден узел владелец.
Алгоритм смены владельца первичной копии
Предполагается, что владелец был найден с помощью предыдущего алгоритма. Строка, владелец которой изменяется, блокируется на узле текущего владельца. На обоих узлах изменяются значения owner и epoch. Owner меняется на имя узла, инициировавшего смену владельца, а epoch увеличивается на единицу. После этого остальным узлам асинхронно рассылаются новые значения owner и epoch. Такой алгоритм гарантирует, что в каждый момент времени только один узел считает себя владельцем строки.
Протоколы реплицируемой записи
В протоколах реплицируемой записи операции записи могут осуществляться на нескольких репликах, а не на одной, как в случае протоколов на базе первичной копии. Существуют две основные разновидности, рассматриваемые ниже.
Активная репликация
Активная репликация подразумевает возможность обновления произвольной реплики с последующей рассылкой обновлений другим репликам (с помощью команд обновления или самих обновленных данных). Для того чтобы с помощью активной репликации можно было реализовать модель последовательной непротиворечивости, необходимо гарантировать одинаковую последовательность выполнения всех операций записи на всех машинах. Это можно обеспечить с помощью упорядоченной групповой рассылки, построенной с помощью отметок времени Лапорта, либо с помощью выделения специального узла (секвенсора), который будет упорядочивать все операции записи, за счет присвоения им последовательного уникального идентификатора. Последнее решение, однако, приближает активную репликацию к протоколам на базе первичной копии. Также возможно предстоит решить проблему реплицированных обращений, смысл которой состоит в следующем: если объект А обращается к реплицированному объекту В, который при этом обращается к объекту С, то объект С получит несколько обращений вместо одного.
Протоколы кворума
Основная идея, лежащая в основе протоколов кворума состоит в том, чтобы запрашивать разрешение на проведение операций чтения и записи у нескольких серверов, образующих кворум. Существуют кворум записи и кворум чтения. Эти кворумы надо собрать перед выполнением соответствующих операций. При этом с каждой операцией записи одних и тех же данных сопоставляется последовательно возрастающий номер версии. Пусть разделяемый ресурс имеет N реплик, тогда кворум чтения Nr (количество реплик, к которым выполняется запрос на чтение) и кворум записи Nw (количество реплик, в которое осуществляется запись) определяются из следующих двух условий:
- Nr + Nw > N
- Nw > N/2
Смысл этих ограничений состоит в следующем: первое ограничение гарантирует, что при опросе Nr серверов, хотя бы один из них содержит последнюю версию запрашиваемых данных, второе ограничение устраняет конфликт двойной записи, т.е. делает невозможных существование различающихся копий одних и тех же данных, имеющих одинаковую версию. В предельном случае, когда Nr = 1 Nw = N, все операции чтения могут быть осуществлены локально, однако операция обновления должна быть произведена на всех репликах.
Замечания по поводу реализации свободной непротиворечивости
Протоколы на базе первичной копии плохо подходят для реализации свободной непротиворечивости. Это объясняется тем, что в них операция записи, автоматически порождает выполнение синхронизации реплик, тогда как при свободной непротиворечивости подразумевается независимое выполнение операций синхронизации. Протоколы реплицируемой записи (активная репликация) куда лучше подходят для реализации данной модели. Для реализации активной репликации нужна полностью упорядоченная групповая рассылка. Поскольку в модели слабой непротиворечивости подразумевается доступ к переменным синхронизации согласно последовательной непротиворечивости, то упорядоченная групповая рассылка может быть использована для организации доступа к переменным синхронизации.
Задача получения новой непротиворечивой реплики
Рассматривается распределенное хранилище данных (РХД), состоящие из N узлов, каждый их которых содержит реплики данных. Стоит задача получения непротиворечивой реплики для нового N+1 узла.
Существует два различных подхода к решению этой задачи:
- Перевод распределенного хранилища данных в состояние, в котором выполнение операций изменения данных запрещено, с последующим копированием всех необходимых данных в новую реплику
- Получение новой реплики без приостановки выполнения операций изменения, при этом распределенное хранилище данных продолжает функционировать в обычном режиме
Алгоритм, иллюстрирующий 1-ый подход
Узел, инициирующий операцию по переводу хранилища данных в особое состояние, посылает всем остальным узлам сообщение о запрете инициировать новые изменения. В ответ на это сообщение каждый из узлов, помечает все сообщения, инициатором которых он является, и которые уже находятся в его локальной очереди, но еще не обработаны. Далее каждый узел продолжает обрабатывать все поступающие от других узлов сообщения и свои помеченные сообщения. После того как будет обработано последнее помеченное сообщение, каждый узел посылает сообщение узлу инициатору о завершение выполнения своих операций. После того как узел инициатор получит такие сообщения от всех узлов, РХД будет находиться в специальном состоянии и можно начинать операции копирования для получения новой реплики.