|
"Теоретически канал с адресацией EUI 64 может соединить порядка запись вида ее можно заменить например на записи вида 264 или 1,8 * 1019
|
Опубликован: 30.07.2013 | Доступ: свободный | Студентов: 1898 / 161 | Длительность: 24:05:00
Тема: Сетевые технологии
Специальности: Архитектор программного обеспечения
Лекция 10:
Вспомогательные механизмы
На самом деле, это только первый шаг к отказоустойчивому подключению. В обоих вариантах он известен как множественное подключение (multihoming). Но что он дает хосту? Непосредственно хост может обнаружить только сбой канала или маршрутизатора, используя механизм NUD (§5.1). Что ж, и это неплохо, так как хост может переключиться на другого провайдера, используя стандартные механизмы.
Если же сбой будет где-то дальше в сети провайдера, то явного указания на это хост не получит. Что же произойдет в этом случае? Рассмотрим для примера два сценария, в которых хост принимает соединения TCP извне или же устанавливает их с внешними хостами сам.
Допустим, что в первом сценарии все адреса хоста опубликованы в DNS под одним именем. Тогда удаленное приложение, получив на входе имя, станет пробовать эти адреса по очереди, в порядке, предписанном DAS (§6.6). Так как трасса к разным адресам назначения будет проходить через разных провайдеров ввиду самого устройства маршрутизации IP, рано или поздно удаленная сторона выберет доступный адрес назначения, и первый пакет <SYN> дойдет до хоста, скажем, через провайдера №2. Теперь хосту надо позаботиться, чтобы ответный пакет <SYN,ACK> ушел через того же провайдера №2, потому что именно он работоспособен и, вероятно, готов пропустить такой пакет. Эта задача сводится к выбору выходного интерфейса (вариант рис. 9.6) или маршрутизатора (вариант рис. 9.7). В первом случае решение таково: сокет IPv6 должен быть привязан к определенному сетевому интерфейсу хоста. Например, в данном случае пакет <SYN> придет по адресу, который назначен интерфейсу №2, а значит, и ответный пакет <SYN,ACK> надо направить в тот же интерфейс. Во втором случае хосту понадобится дополнительное правило при выборе маршрутизатора, чтобы пакет с адресом источника от провайдера №2 ушел именно через маршрутизатор №2. Благодаря записи в кэше адресатов DC, которая возникнет в результате этого выбора, последующие пакеты данного соединения пойдут через маршрутизатор №2 естественным порядком.
В нормативных документах IPv6 такого правила пока что нет, хотя оно обсуждалось [draft-huitema-multi6-hosts ,7 Kenji Ohira. IPv6 Address Assignment and Route Selection for End-to-End Multihoming. IETF Meeting №57. http://ops.ietf.org/multi6/ietf57/day1/IETF-57-ohira-multi6.ppt .
Если один и тот же удаленный адрес одновременно установит соединения с разными адресами локального хоста через разных провайдеров, эта схема даст сбой. Чтобы восстановить ее работоспособность, запись DC должна включать в себя адрес источника, чтобы разным локальным адресам отвечали разные записи DC даже при одном и том же удаленном адресе назначения.
Перейдем теперь ко второму сценарию, когда хост сам хочет установить соединение TCP с удаленной стороной, послав для начала пакет <SYN>. Конечно, может оказаться, что у удаленного хоста тоже есть несколько адресов и только некоторые из них недоступны через текущего провайдера. Тогда поможет обычный перебор удаленных адресов. Но как быть, если произошел полный сбой текущего провайдера? Как мы уже сказали, хост может обнаружить его только по косвенным признакам. Здесь одна из возможных линий поведения хоста — попробовать все свои выходные интерфейсы (вариантрис. 9.6) или все маршрутизаторы (вариант рис. 9.7) по очереди. В первом случае процедура DAS выберет правильный адрес источника для пакета <SYN>. Во втором случае надо, чтобы выбор маршрутизатора влиял на выбор адреса источника, а это вполне допустимое расширение процедуры DAS [§5 и §7 RFC 6724].
Таким образом, множественное подключение хоста IPv6 можно использовать, практически не выходя за рамки стандартных механизмов. Тем не менее, мы так и не обеспечили одной простой возможности: сохранить уже установленное соединение TCP при переключении хоста между провайдерами. Как нетрудно убедиться, такое переключение по-прежнему вызывает смену локального адреса, и соединение TCP рвется. С этим нельзя ничего поделать, по крайней мере, на уровне IP.
От этой проблемы проще всего отмахнуться, сказав, что прикладные протоколы должны быть устойчивы к сбоям на транспортном уровне. Несомненно, это так. Скажем, протоколы FTP и HTTP поддерживают "докачку", и эта возможность не чувствительна к адресам IP: клиент просто откроет новый сеанс и снова запросит тот же файл или объект, начиная с энного байта.
Однако это скучный подход, который не делает чести нашему воображению. Давайте лучше применим фантазию и в общих чертах набросаем решение поинтереснее. Прийти к нему несложно. Для этого представим себе, что приложение открывает одно соединение TCP сразу с множеством адресов удаленной стороны. Действительно, зачем перебирать их по одному, если можно было бы послать по пакету <SYN> сразу им всем. Тогда и локальный конец соединения мог бы иметь не один адрес, а целое их множество.
"В лоб" такое решение можно сымитировать, открыв M*N соединений TCP, где N — число локальных адресов, а M — число удаленных адресов. Однако это непрактичный подход, так как, во-первых, число таких соединений может быть велико, а во-вторых, ими надо дополнительно управлять, чтобы сохранить порядок байтов в потоке. Ведь получателю надо как-то узнать, в каком порядке были посланы байты, пришедшие по разным соединениям.
Поэтому нам понадобится более целостное решение. Так, TCP можно заменить новым транспортным протоколом, который с самого начала станет поддерживать больше одного адреса на каждом из концов соединения. Конечно, пакет IPv6 по-прежнему содержит только один адрес источника и один адрес назначения, так что вся работа по слежению за доступностью адресов и переключению между ними ляжет на этот новый транспортный протокол. На самом деле, такой протокол уже создан: SCTP. Прелесть этого решения в том, что оно сквозное: хостам безразлично, где именно в сети произошел сбой, и пока существует хотя бы одна пара адресов, межу которой пакеты все еще ходят, транспортное соединение будет жить.
Однако новый транспортный протокол — это довольное радикальное новшество, которое подходит только для новых приложений. Кроме того, с новым транспортным протоколом связана та трудность, что всевозможные межсетевые экраны, системы предотвращения вторжений и прочие "ящики" (middleboxes), ведущие глубокий анализ транзитного трафика, уже хорошо знакомы с TCP, но новый протокол наверняка вызовет проблемы. Поэтому нельзя ли перенести все те же идеи обратно в старый добрый TCP, чтобы и существующие приложения выиграли от новой архитектуры множественных подключений?
В основу такого "многопутевого TCP" (multipath TCP, MPTCP) следует заложить принципы совместимости с приложениями и сетью [RFC 6182]. Что это значит? С одной стороны, сетевой API, например, сокеты Беркли, должен остаться, по возможности, без изменений, чтобы уже существующие приложения не пришлось даже перекомпилировать, не говоря уже о том, чтобы их переписывать. А с другой стороны, для стороннего наблюдателя в сети каждый путь MPTCP (известный как под-поток, sub-flow) должен выглядеть как обычное соединение TCP. Это нужно, чтобы MPTCP беспрепятственно проходил сквозь различные "ящики".
В частности, у каждого под-потока своя, независимая от других под-потоков и непрерывная, как и положено в TCP, нумерация байтов, то есть порядковые номера и номера квитанций. Если бы нумерация байтов была одна на все под-потоки, протокол стал бы проще, но достаточно строгий "ящик" вполне мог бы блокировать под-поток с "прорехами" в нумерации байтов, потому что тот нарушает протокол TCP. Соответствие между номерами байтов в под-потоке и всем соединении MPTCP задает та дополнительная информация, которую несут прозрачные для "ящиков" опции MPTCP.
Фактически мы вернулись к идее множественных соединений TCP между разными парами локальных и удаленных адресов, но под управлением четко заданного механизма. Чтобы работать по-настоящему эффективно, MPTCP должен управлять не только взаимной доступностью разных пар адресов, но и перегрузкой вдоль разных путей, перенося трафик на те пути, где перегрузка меньше [RFC 6356]. Для переноса служебной информации MPTCP вполне подходят опции TCP, которые активно используются и для других целей, а потому без труда преодолевают "ящики" [draft-ietf-mptcp-multiaddressed]. Благодаря дополнительной информации, MPTCP вновь собирает исходный поток байтов из нескольких под-потоков, а потому он способен вести одновременную передачу данных вдоль нескольких путей.
Конечно, MPTCP не зависит от особенностей IPv6. Более того, он позволяет соединению TCP одновременно использовать пути IPv4 и IPv6.
А как насчет других протоколов, уже работающих непосредственно поверх IPv6? В их случае можно испытать иной подход. Представим себе, что между всеми этими протоколами и уровнем IPv6 появляется "прокладка", которая манипулирует адресами в пакетах, так что вышестоящий протокол всегда имеет дело с одной парой адресов (локальный и удаленный), как и раньше. Этой "прокладке", известной как Shim6 (Прокладка №6) [RFC 5533 ,8 A. Garcia-Martinez, M. Bagnulo, I. van Beijnum. The Shim6 architecture for IPv6 multihoming. IEEE Communications Magazine, 2010, v. 48, issue 9, pp. 152–157 http://www.networks.imdea.org/Portals/8/Downloads/Publications/Shim6-Arquitecture-2010-EN.pdf ], тогда придется динамически транслировать неизменные адреса "сверху" в зависящие от текущей обстановки в сети адреса "снизу" и наоборот. Эта трансляция превращает адреса, видные вышестоящим протоколам, в идентификаторы, не зависящие от сетевой топологии, тогда как адреса, действительно попадающие в сеть, становятся локаторами, чувствительными к сетевой обстановке. Поэтому первые из них получили название "идентификаторы вышележащего уровня" (Upper-Layer Identifier, ULID). Конечно, адрес ULID остается обычным адресом IPv6 и может выполнять заодно роль локатора, пока соответствующий сетевой интерфейс доступен. Так как Shim6 тесно соприкасается с IPv6, свою служебную информацию он передает в виде заголовков расширения. Информацию о доступности адресов-локаторов для нужд Shim6 поставляет вспомогательный протокол REAP (Reachability Protocol ) [RFC 5534].
Самостоятельно обсудите, вызовет ли Shim6 те же трудности, что и NAT, у прикладных протоколов, передающих адреса IP внутри своих сообщений. К таким протоколам относятся, например, FTP и SIP.
Мы не станем сейчас разбирать технические детали MPTCP и Shim6, потому что они довольно сложны и выходят за рамки нашего курса. Тем не менее, уже сказанного достаточно, чтобы увидеть, как снова победила сквозная модель: эффективное использование независимых подключений оказалось по силам самим хостам, а IPv6 предлагает почти все необходимые для этого механизмы.
Конечно, передача данных по независимым подключениям создает и новые проблемы. Одна из них состоит в том, как локальный хост убедится, что все завяленные адреса принадлежат одному удаленному хосту. Ведь иначе злоумышленник может перехватить поток данных, выдав себя за один из адресов удаленного хоста. Это в особенности касается протоколов вроде Shim6, в которых стороны не обмениваются информацией обо всех своих адресах заранее.
Связать воедино несколько адресов можно, снова воспользовавшись идентификатором интерфейса как носителем защитной информации. Допустим,
хосту необходимо назначить  адресов, все в разных подсетях. То есть на входе мы получаем список префиксов подсетей
адресов, все в разных подсетях. То есть на входе мы получаем список префиксов подсетей
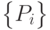 , где
, где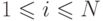 . Тогда идентификатор интерфейса
. Тогда идентификатор интерфейса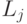 для
префикса
для
префикса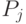 можно вычислить как хэш-функцию всех префиксов, например, так:
можно вычислить как хэш-функцию всех префиксов, например, так:
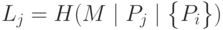 .
.
То есть хэш-функция 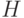 вычисляется от цепочки битов, полученной сцеплением какого-то дополнительного параметра M,
известного обеим сторонам протокола, данного префикса и всего списка префиксов.
В результате мы получаем набор из адресов вида:
вычисляется от цепочки битов, полученной сцеплением какого-то дополнительного параметра M,
известного обеим сторонам протокола, данного префикса и всего списка префиксов.
В результате мы получаем набор из адресов вида:
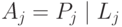 .
.
То есть каждый адрес получен сцеплением префикса подсети и отвечающего ему идентификатора интерфейса, вычисленного по
вышеприведенному рецепту. Составленный таким образом адрес известен как адрес, основанный на хэше (Hash-Based Address
, HBA) [RFC 5535]. Он имеет смысл только в составе всего набора 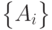 , известного как набор HBA
(HBA-Set). Точнее, вне набора это обычный адрес IPv6 без дополнительных защитных свойств.
, известного как набор HBA
(HBA-Set). Точнее, вне набора это обычный адрес IPv6 без дополнительных защитных свойств.
Параметр M нужен, как минимум, для того, чтобы разные хосты, подключенные к одним и тем же подсетям, могли получить разные наборы HBA. Кроме того, адрес HBA случайный, а значит, есть вероятность конфликта с уже назначенным адресом. В этом случае конфликт обнаружит процедура DAD (§5.4.1). Но, чтобы разрешить конфликт, придется варьировать параметр M и повторить вычисление набора HBA. На практике параметр M составной и содержит в себе несколько полей, отвечающих за разные свойства набора HBA: уникальность, устойчивость к конфликтам, совместимость с CGA (§6.3).
Если хэш-функция надежная, то порядок сцепления отдельных элементов в цепочку-аргумент неважен, пока один и тот же порядок
принят всеми сторонами протокола. На практике одно поле M, а именно счетчик коллизий, возникает между префиксом
и списком префиксов ради совместимости с CGA. Это поле увеличивается на единицу, если процедура DAD обнаружила коллизию. Благодаря
этому повторное вычисление дает другие случайные адреса.
Теперь мысленно перенесемся на другую сторону протокола и подумаем, как с помощью механизма HBA проверить адрес , на
который претендует удаленная сторона. Пусть этот адрес состоит из префикса подсети
, на
который претендует удаленная сторона. Пусть этот адрес состоит из префикса подсети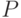 и идентификатора интерфейса
и идентификатора интерфейса
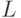 . Суть проверки сводится вот к чему: принадлежит ли данный адрес данному набору HBA? Чтобы провести
такую проверку, проверяющей стороне потребуется параметр
. Суть проверки сводится вот к чему: принадлежит ли данный адрес данному набору HBA? Чтобы провести
такую проверку, проверяющей стороне потребуется параметр  и список префиксов . Именно
эти два элемента и определяют набор HBA, потому что все остальное можно вычислить на месте. Так, проверяющая сторона первым делом
проверяет, содержится ли префикс из адреса в списке . Если это не так,
то налицо подлог или обычный сбой. Если же префикс — в списке, то осталось вычислить его ожидаемый идентификатор интерфейса HBA:
и список префиксов . Именно
эти два элемента и определяют набор HBA, потому что все остальное можно вычислить на месте. Так, проверяющая сторона первым делом
проверяет, содержится ли префикс из адреса в списке . Если это не так,
то налицо подлог или обычный сбой. Если же префикс — в списке, то осталось вычислить его ожидаемый идентификатор интерфейса HBA:
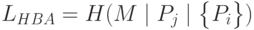 .
.
Если адрес действительно из данного набора HBA, то его идентификатор интерфейса обязан совпасть с
вычисленным значением  , с точностью до битов U/L и I/G.
, с точностью до битов U/L и I/G.
Дело осталось за малым: передать параметр M и список префиксов проверяющей стороне. Оказывается, что
для этого не нужен новый протокол, так как всю необходимую информацию можно поместить в блок параметров CGA (рис. 9.3). Формат этого
блока достаточно гибок и расширяем, чтобы в нем нашлось место для списка префиксов, а модификатор уже в нем содержится. В результате
можно составлять адреса, которые одновременно удовлетворяют нормативам CGA и HBA, потому что их идентификаторы интерфейса стандартным
образом зависят и от открытого ключа хоста, и от его списка префиксов. Это чудесным образом избавляет нас от конфликта между
механизмами CGA и HBA.
В блоке параметров CGA уже есть случайный модификатор, префикс подсети P, и счетчик коллизий — они отвечают подстроке
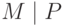 в аргументе хэш-функции. Список префиксов отправится в конец блока как расширение CGA. В результате весь
аргумент хэш-функции будет отформатирован как блок параметров CGA, а HBA превратится в совместимое расширение CGA.
в аргументе хэш-функции. Список префиксов отправится в конец блока как расширение CGA. В результате весь
аргумент хэш-функции будет отформатирован как блок параметров CGA, а HBA превратится в совместимое расширение CGA.
Конечно, простой пакет HBA не пройдет криптографическую проверку CGA, поскольку он не подписан закрытым ключом. Вместо настоящего ключа HBA-без-CGA использует случайную цепочку битов в формате ключа RSA. Тем не менее, адрес HBA содержит в себе годный отпечаток этого случайного ключа.
Как и можно было ожидать, HBA наследует у CGA ограничение на длину префикса подсети P: она обязана равняться 64 битам.
Сергей Субботин
 "
"
Павел Афиногенов
|
Курс IPv6, в тексте имеются ссылки на параграфы. Разбиения курса на параграфы нет. |