Опубликован: 02.08.2007 | Доступ: свободный | Студентов: 3999 / 820 | Оценка: 4.55 / 4.39 | Длительность: 27:09:00
ISBN: 978-5-9556-0111-3
Тема: Базы данных
Специальности: Администратор баз данных
Лекция 11:
Создание физической модели базы данных
Индекс со структурой B-Tree
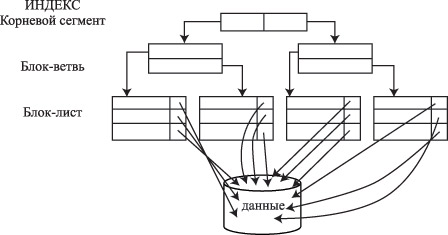
Индекс на основе сбалансированной иерархической структуры, или индекс B-Tree (Balanced Tree structured object), используется как индекс по умолчанию в СУБД Oracle. Эта структура напоминает дерево (если смотреть снизу вверх), в котором сначала считывается самый верхний блок - корневой узел (root), затем блок на следующем уровне - блок-ветвь (branch) и так до тех пор, пока не будет извлечен блок-лист (leaf) с идентификатором строки. Значения ключа сохраняются в индексе (рис. 11.1). Такая структура позволяет сократить до минимума число операций ввода/вывода. Для получения идентификатора строки обычно требуется одно посещение блок-листа, т.е. физической страницы базы данных, отведенной под индекс.
Замечание. Следует отметить два случая, когда после выборки идентификатора строки из индекса может понадобиться несколько посещений физической страницы индекса: 1) когда строка имеет длину более одной физической страницы, так называемая расщепленная строка; 2) когда строка за время своего существования в базе данных увеличилась и была перемещена из исходной страницы в другую, так называемая мигрировавшая строка.
Индекс B-Tree характеризуется количеством уровней в индексе (height). Чем меньше уровней, тем выше производительность.
Индекс B-Tree - это физический объект реляционной базы данных, организованный по принципу сбалансированной иерархической структуры и обладающий набором свойств. Сформулируем некоторые свойства индексов со структурой B-Tree.
- Количество операций ввода/вывода, необходимых для получения идентификатора строки, зависит от числа уровней ветвления дерева. По мере увеличения индекса в результате добавление новых данных, СУБД добавляет в него новые уровни, чтобы обеспечить сбалансированность дерева. Однако в действительности таких уровней редко бывает более четырех.
- Корневой узел и узлы - ветви индекса сжимаются и поэтому содержат ровно столько начальных байтов значения ключа, сколько нужно для того, чтобы отличить его от других значений. Узлы-листья содержат полное значение ключа.
- Значения в индексе упорядочиваются по ключевому значению, а физические страницы индекса организуются в двунаправленный список. Это обеспечивает последовательный доступ к индексу и позволяет использовать индекс для выполнения операции ORDER BY в запросе.
- Индекс можно использовать для поиска и точного соответствия, и для диапазона значений.
- Индексы могут быть построены для нескольких колонок таблицы (так называемый составной индекс). СУБД использует составные индексы для выполнения тех запросов, в которых задана лидирующая часть составного ключа. Например, составной индекс {Ename, Job} для обработки запросаприменяться не будет.
SELECT * FROM EMPLOYEE WHERE Job='Инженер';
- СУБД обычно само принимает решение, использовать индекс или нет.
- Значения колонок NULL не индексируются. Если для таких колонок строится индекс, то СУБД будет отказываться примерять его в некоторых операциях, например ORDER BY.
Индексы создаются командой SQL CREATE INDEX. В предыдущих лекциях мы уже создавали индексы на основе B-Tree. При создании индекса опционально можно задать ряд параметров. Для получения полного списка параметров следует обратиться к документации по СУБД. Применение некоторых параметров будет показано в следующих разделах.
Пример. В нашей учебной базе создадим для таблицы EMPLOYEE составной индекс по колонкам Ename и Job. При этом проектировщик базы данных не уверен, что этот индекс будет использоваться эффективно, поэтому он задал опцию для сбора статистики для этого индекса.
CREATE INDEX emp_ndx2 ON EMPLOYEE (Ename, Job) COMPUTE STATISTICS;
В этом подразделе мы рассмотрели наиболее часто используемый тип индексов. В последующих подразделах и разделах мы рассмотрим другие типы индексов реляционных баз данных.
Исключительно индексные таблицы
Индексы могут создаваться на основе значений одной или нескольких колонок. Если требования к данным в запросе удовлетворяются на основе информации из связанного с этими данными индекса, то доступ к базовой таблице не осуществляется. Это обстоятельство привело к идее создания исключительно индексной таблицы (index-organized table). Исключительно индексная таблица является индексом типа B-Tree базы данных, который одновременно исполняет роль таблицы. Все данные такой таблицы хранятся в индексе. Преимуществом создания полностью индексированных таблиц состоит в экономии места хранения на диске и сокращения объема ввода/вывода, поскольку ключевые колонки нет необходимости сохранять еще раз в таблице. Результат выполнения запроса будет получен на основе данных, сохраненных в индексной таблице. Исключительно индексная таблица создается с помощью команды SQL CREATE TABLE, как показано в примере ниже.
Пример. Предположим, что в нашей учебной базе требуется в отдельной таблице сохранять и отслеживать проблемы, возникающие по выполнении всех проектов, и частоту возникновения проблемы. Создадим исключительно индексную таблицу для этой таблицы, как показано ниже:
CREATE TABLE Proj_Index
( projno char(8) NOT NULL,
t_person char(32) NOT NULL,
t_frequency integer,
t_problem varchar2(512),
CONSTRAINT pk_ndx PRIMARY KEY( projno, t_person) )
ORGANIZATION INDEX
TABLESPACE ts_ndx1
PCTTHRESHOLD 20
INCLUDING t_frequency
OVERFLOW TABLESPACE ts__of_ndx1;Команда CREATE TABLE не отличается ничем от других команд создания таблиц до тех пор, пока не встретится предложение ORGANIZATION INDEX, которое указывает СУБД на создание исключительно индексной таблицы. Для размещения индекса на диске указывается табличное пространство. Параметр PCTTHRESHOLD указывает, что оставшуюся часть строки нужно сохранять в заданном табличном пространстве - сегменте переполнения, если данная строка превышает размер физической страницы базы данных на указанное число процентов. Параметр INCLUDING определяет имя колонки, с которой строка индексной таблицы делится на две части: индексную и переполнения. Эта колонка может быть частью первичного ключа таблицы или неключевой колонкой. Все неключевые колонки, которые следуют за указанной колонкой, размещаются в сегменте переполнения, который определяется ключевым словом OVERFLOW.