Словарные методы сжатия данных
Классические алгоритмы Зива-Лемпела
Алгоритмы словарного сжатия Зива-Лемпела появились во второй половине 1970-х годов. Это были так называемые алгоритмы LZ77 и LZ78, разработанные совместно Зивом (Ziv) и Лемпелом (Lempel). В дальнейшем первоначальные схемы подвергались множественным изменениям, в результате чего мы сегодня имеем десятки достаточно самостоятельных алгоритмов и бессчетное количество модификаций.
LZ77 и LZ78 являются универсальными алгоритмами сжатия, в которых словарь формируется на основании уже обработанной части входного потока, т.е. адаптивно. Принципиальным отличием является лишь способ формирования фраз. В модификациях первоначальных алгоритмов это свойство сохраняется. Поэтому словарные алгоритмы Зива-Лемпела разделяют на два семейства - алгоритмы типа LZ77 и алгоритмы типа LZ78. Иногда также говорят о словарных методах LZ1 и LZ2.
Публикации Зива и Лемпела носили чисто теоретический характер, так как эти исследователи на самом деле занимались проблемой измерения "сложности" строки, и применение выработанных алгоритмов к сжатию данных явилось, скорее, лишь частным результатом. Потребовалось некоторое время, чтобы идея организации словаря, часто в переложении уже других людей, достигла разработчиков программного и аппаратного обеспечения. Поэтому практическое использование алгоритмов началось спустя пару лет.
С тех пор методы данного семейства неизменно являются самыми популярными среди всех методов сжатия данных, хотя в последнее время ситуация начала меняться в пользу BWT и PPM, как обеспечивающих лучшее сжатие. Кроме того, практически все реально используемые словарные алгоритмы относятся к семейству Зива-Лемпела.
Необходимо сказать несколько слов о наименованиях алгоритмов и методов. При обозначении семейства общепринятой является аббревиатура "LZ", но расшифровываться она должна как "Ziv-Lempel", поэтому и алгоритмы "Зива-Лемпела", а не "Лемпела-Зива". Согласно общепринятому объяснению этого курьеза, Якоб Зив внес больший вклад в открытие соответствующих словарных схем и исследование их свойств и таким образом заслужил, чтобы первым стояла его фамилия, что мы и видим в заголовках статей [2.12, 2.13]. Но случайно была допущена ошибка, и прикрепилось сокращение "LZ" (буквы упорядочены в алфавитном порядке). Иногда, кстати, встречается и обозначение "ZL" (порядок букв соответствует порядку фамилий авторов в публикациях [2.12, 2.13]). В дальнейшем, если некий исследователь существенно изменял какой-то алгоритм, относимый к семейству LZ, то в названии полученной модификации к строчке "LZ" обычно дописывалась первая буква его фамилии, например: алгоритм LZB, автор Белл (Bell).
Подчеркнем также наличие большой путаницы с классификацией алгоритмов. Обычно она проявляется в нежелании признавать существование двух самостоятельных семейств LZ, а также в неправильном отнесении алгоритмов к конкретному семейству. Беспорядку часто способствуют сами разработчики: многим невыгодно раскрывать, на основе какого алгоритма создана данная модификация из-за коммерческих, патентных или иных меркантильных соображений. Например, в случае коммерческого программного обеспечения общепринятой является практика классификации используемого алгоритма сжатия как "модификации LZ77". И в этом нет ничего удивительного, ведь алгоритм LZ77 не запатентован.
Алгоритм LZ77
Этот словарный алгоритм сжатия является самым старым среди методов LZ. Описание было опубликовано в 1977 году [2.12], но сам алгоритм разработан не позднее 1975 года.
Алгоритм LZ77 является "родоначальником" целого семейства словарных схем - так называемых алгоритмов со скользящим словарем, или скользящим окном. Действительно, в LZ77 в качестве словаря используется блок уже закодированной последовательности. Как правило, по мере выполнения обработки положение этого блока относительно начала последовательности постоянно меняется, словарь "скользит" по входному потоку данных.
Скользящее окно имеет длину N, т.е. в него помещается N символов, и состоит из 2 частей:
- последовательности длины W = N-n уже закодированных символов, которая и является словарем;
- упреждающего буфера, или буфера предварительного просмотра (lookahead), длины n ; обычно n на порядки меньше W.
Пусть к текущему моменту времени мы уже закодировали t символов  . Тогда словарем будут являться W предшествующих символов
. Тогда словарем будут являться W предшествующих символов 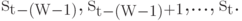 Соответственно, в буфере находятся ожидающие кодирования символы
Соответственно, в буфере находятся ожидающие кодирования символы 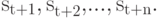 . Очевидно, что если
. Очевидно, что если  , то словарем будет являться вся уже обработанная часть входной последовательности.
, то словарем будет являться вся уже обработанная часть входной последовательности.
Идея алгоритма заключается в поиске самого длинного совпадения между строкой буфера, начинающейся с символа  и всеми фразами словаря. Эти фразы могут начинаться с любого символа
и всеми фразами словаря. Эти фразы могут начинаться с любого символа  и выходить за пределы словаря, вторгаясь в область буфера, но должны лежать в окне. Следовательно, фразы не могут начинаться с поэтому буфер не может сравниваться сам с собой. Длина совпадения не должна превышать размер буфера. Полученная в результате поиска фраза
и выходить за пределы словаря, вторгаясь в область буфера, но должны лежать в окне. Следовательно, фразы не могут начинаться с поэтому буфер не может сравниваться сам с собой. Длина совпадения не должна превышать размер буфера. Полученная в результате поиска фраза  кодируется с помощью двух чисел:
кодируется с помощью двух чисел:
Смещение и длина соответствия играют роль указателя (ссылки), однозначно определяющего фразу. Дополнительно в выходной поток записывается символ s, непосредственно следующий за совпавшей строкой буфера.
Таким образом, на каждом шаге кодер выдает описание трех объектов: смещения и длины соответствия, образующих код фразы, равной обработанной строке буфера, и одного символа s (литерала). Затем окно смещается на j+1 символов вправо и осуществляется переход к новому циклу кодирования. Величина сдвига объясняется тем, что мы реально закодировали именно j+1 символов: j с помощью указателя на фразу в словаре, и 1 с помощью тривиального копирования. Передача одного символа в явном виде позволяет разрешить проблему обработки еще ни разу не виденных символов, но существенно увеличивает размер сжатого блока.