Определения. Аббревиатуры и классификации методов сжатия
Символ - это "атом" некоторого языка (например, буквы, цифры, ноты, символы шахматных фигур, карточных мастей). Во многих случаях под символом имеют в виду R-битный элемент (обычно байт), однако элементы мультимедийных данных все-таки не стоит называть символами: они содержат количественную информацию, а не качественную.
"Качественными" можно называть данные, содержащие элементы-указатели на символы внутри таблиц или указатели на ветви алгоритма (и таким образом "привязанные" к некоторой структуре: таблице, списку, алгоритму и т.п.) А "количественными" - множества элементов, являющиеся записями значений каких-либо величин.
ASCII (American Standard Code for Information Interchange - Американский Стандартный Код для Обмена Информацией) каждому значению байта ставит в соответствие символ. Но чтобы построить однозначное соответствие для всех необходимых символов из множества национальных алфавитов народов мира, требуется больше: по крайней мере 16 битов на символ (что и обеспечивает стандарт Unicode ).
Множество всех различных символов, порождаемых некоторым источником, называется алфавитом, а количество символов в этом множестве - размером алфавита. Источники данных порождают только элементы, но физические источники информации - символы или элементы.
Размер алфавита таблицы ASCII равен 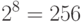 , а Unicode -
, а Unicode -  . Это две самые распространенные таблицы символов.
. Это две самые распространенные таблицы символов.
Источник данных порождает поток либо содержит блок данных. Вероятности порождения элементов определяются состоянием источника. У источника данных без памяти состояние одно, у источника с памятью - множество состояний, и вероятности перехода из одного состояния в другое зависят от совокупности предыдущих и последующих (еще не реализованных, в случае потока) состояний.
Можно говорить, что источник без памяти порождает "элементы", а источник данных с памятью - "слова", поскольку во втором случае
- учет значений соседних элементов ( контекста ) улучшает сжатие, то есть имеет смысл трактовать данные как слова;
- поток данных выглядит как поток слов.
В первом же случае имеем дело с перестановкой элементов, и рассматривать данные как слова нет смысла.
Кавычки показывают, что это условные названия способов интерпретации входных данных: "слова", "элементы", "биты".
По традиции бинарный источник без памяти называют обычно "источник Бернулли", а важнейшим частным случаем источника данных с памятью является "источник Маркова" (N-го порядка): состояние на i-ом шаге зависит от состояний на N предыдущих шагах: i-1, i-2,…, i-N.
Третья важнейшая применяемая при сжатии данных математическая модель - "аналоговый сигнал":
Если использовать модель "аналоговый сигнал" с N > 1, то при малых N эффективность сжатия неизменна или незначительно лучше, но метод существенно сложнее, а при дальнейшем увеличении N эффективность резко уменьшается.
Эффективность сжатия учитывает не только степень сжатия (отношение длины несжатых данных к длине соответствующих им сжатых данных), но и скорости сжатия и разжатия. Часто пользуются обратной к степени сжатия величиной - коэффициентом сжатия, определяемым как отношение длины сжатых данных к длине соответствующих им несжатых.
Еще две важных характеристики алгоритма сжатия - объемы памяти, необходимые для сжатия и для разжатия (для хранения данных, создаваемых и/или используемых алгоритмом).
Названия и аббревиатуры методов
CM (Context Modeling) - Контекстное моделирование
DMC (Dynamic Markov Compression) - Динамическое марковское сжатие (является частным случаем CM)
PPM (Prediction by Partial Match) - Предсказание по частичному совпадению (является частным случаем CM)
LZ-методы - методы Зива-Лемпела, в том числе LZ77, LZ78, LZH и LZW
PBS (Parallel Blocks Sorting) - Сортировка параллельных блоков
ST (Sort Transformation) - Частичное сортирующее преобразование (является частным случаем PBS)
BWT (Burrows-Wheeler Transform) - Преобразование Барроуза-Уилера (является частным случаем ST)
RLE (Run Length Encoding) - Кодирование длин повторов
HUFF (Huffman Coding) - кодирование по методу Хаффмана
SEM (Separate Exponents and Mantissas) - Разделение экспонент и мантисс (Представление целых чисел)
UNIC (Universal Coding) - Универсальное кодирование (является частным случаем SEM)
ARIC (Arithmetic Coding) - Арифметическое кодирование
RC (Range Coding) - Интервальное кодирование (вариант арифметического)
DC (Distance Coding) - Кодирование расстояний
IF (Inverted Frequences) - "Обратные частоты" (вариант DC)
MTF (Move To Front) - "Сдвиг к вершине", "Перемещение стопки книг"
ENUC (Enumerative Coding) - Нумерующее кодирование
FT (Fourier Transform) - Преобразование Фурье
DCT (Discrete Cosine Transform) - Дискретное Косинусное Преобразование, ДКП (является частным случаем FT)
DWT (Discrete Wavelet Transform) - Дискретное Вэйвлетное Преобразование, ДВП
LPC (Linear Prediction Coding) - Линейно-Предсказывающее Кодирование, ЛПК (к нему относятся Дельта-кодирование, ADPCM, CELP и MELP)