Области применения онтологий. Задачи, решаемые с помощью онтологий и тезаурусов
Предпосылки использования онтологий
Как было отмечено, существует множество способов классифицировать онтологии. Предполагаемая область применения и цель могут влиять на масштаб и содержимое онтологии. Существенным является ответ на вопрос, какую пользу может принести использование онтологий при решении той или иной задачи.
В данном разделе описываются проблемные области, в которых можно было бы достичь дополнительных преимуществ при использовании онтологий:
- в вычислительном плане (например, для сокращения времени вычислений);
- в экономическом плане (например, для сокращения затрат на разработку программного обеспечения, интеграцию данных);
по сравнению с уже существующими решениями (основанными на классических подходах).
Но для доказательства преимуществ онтологического подхода необходимо проводить сравнение реально действующих проектов, ставить эксперименты. Такая задача не под силу какой-либо одной организации. Важно привлечение ресурсов многих предприятий в рамках одной инициативы. Наиболее крупной "площадкой" для экспериментов с семантическими технологиями в настоящее время является проект Semantic Web. Хотя за время, прошедшее со старта проекта в 2001 году, в концептуальном виде структура Сети (World Wide Web) не изменилась, появился ряд критически важных средств, технологий и языков описания онтологий, необходимых для дальнейшего развития Semantic Web.
Второй по масштабу задачей можно условно считать область информационного поиска (Information Retrieval).
В современных поисковых системах тексты автоматически индексируются по набору слов, составляющих эти тексты.
Такое представление текстов как простого набора слов ("bag of words") имеет большое количество очевидных недостатков, затрудняющих поиск релевантных текстов, например:
- избыточность - в пословном индексе используются слова-синонимы, выражающие одни и те же понятия;
- слова текста считаются независимыми друг от друга, что не соответствует свойствам связного текста;
- многозначность слов - поскольку многозначные слова могут рассматриваться как дизъюнкция двух или более понятий, выражающих различные значения многозначного слова, то маловероятно, что все элементы этой дизъюнкции интересуют пользователя.
Этих недостатков лишено так называемое концептуальное индексирование, то есть такое индексирование, когда текст индексируется не по словам, а по понятиям, которые обсуждаются в данном тексте. При такой технологии:
- все синонимы сведены к одному и тому же понятию;
- многозначные слова отнесены к разным понятиям;
- связи между понятиями и соответствующими словами описаны и могут быть использованы при анализе текста.
Для того чтобы попытаться реализовать схему автоматического концептуального индексирования и концептуального поиска, необходимо иметь ресурс, описывающий систему понятий данной предметной области, то есть онтологию в данной предметной области.
Нужно отметить, что использование онтологий для информационного поиска в реальных широких предметных областях имеет ряд особенностей:
- эта онтология должна быть очень большой величины;
- понятия онтологии должны иметь аккуратно установленные связи с языковыми единицами - терминами предметной области;
- онтология реальной предметной области не может быть полной, поэтому методы информационного поиска на основе онтологий должны сочетаться с методами информационного поиска на основе пословных методов в едином поисковом механизме;
- задача информационного поиска предполагает использование онтологий для анализа свободных неограниченных связных текстов, для которых не существует хорошо развитых методов автоматической обработки.
Все эти факторы ограничивают внедрение онтологий в поисковые механизмы информационно-поисковых систем. Сложившаяся ситуация означает, что необходимы новые исследования:
- для выяснения, онтологии какого типа могут быть наиболее эффективными при использовании в задачах информационного поиска;
- для разработки комбинированных технологий информационного поиска, сочетающих как методы на базе знаний, описанных в онтологиях, так и пословные методы;
- для разработки методов "быстрого" создания онтологий для широких предметных областей на основе текстовых коллекций и интеграции знаний уже существующих онтологий.
Подобные трудности характерны и в области интеграции разнородных баз данных. Но здесь преимущества от внедрения решений на базе онтологий могут быть более ощутимыми для конкретного предприятия. Поскольку система понятий ограничена предметной областью и объемы данных не настолько впечатляющи, как в Internet, построение соответствующей онтологии вполне возможно, т.к. каждому приложению (или БД) не важно, какую именно онтологию верхнего уровня оно разделяет с другими. Важно использование единой онтологии верхнего уровня или даже онтологии предметной области, которая может способствовать интеграции данных, обеспечить интероперабельность. В трех следующих подразделах описываются области применения онтологий, в которых они оказываются наиболее полезными.
3.1. Semantic Web
Идея Семантической Сети (Semantic Web) впервые была провозглашена в 2001 году Тимом Бернерсом-Ли (создателем World Wide Web). Однако она не является новой ни для автора, ни для web-сообщества в целом. Суть ее состоит в автоматизации "интеллектуальных" задач обработки значения (в семантическом смысле) тех или иных ресурсов, имеющихся в Сети. Обработкой и обменом информации должны заниматься не люди, а специальные интеллектуальные агенты (программы, размещенные в Сети). Но для того, чтобы взаимодействовать между собой, агенты должны иметь общее (разделяемое всеми) формальное представление значения для любого ресурса. Именно для цели представления общей, явной и формальной спецификации значения в Semantic Web используются онтологии.
За пять лет, прошедших с момента первой публикации о Semantic Web, был разработан целый ряд стандартов и рекомендаций, реализовано множество проектов. Но, несмотря на отдельные успехи, до сих пор (и это признает сам Т. Бернерс-Ли) нельзя сказать, что идея Semantic Web реализована на практике. В этом разделе будут изложены предпосылки к созданию Semantic Web, путь, который был проделан исследователями с 2001 по 2006 годы, и препятствия, возникшие на этом пути.
Работа над средствами описания семантики в Сети началась задолго до публикации 2001 года. В 1997 году консорциум W3C определил спецификацию RDF (Resource Description Framework). RDF предоставляет простой, но мощный язык описания ресурсов, основанный на триплетах (triple-based) "Субъект-Предикат-Объект" и спецификации URI. В 1999 году RDF получает статус рекомендации. Этот шаг в направлении улучшения функциональности и обеспечения интероперабельности (т.е. возможности обмениваться данными несмотря на их разнородность) в Сети считается одним из важнейших. Концептуально RDF дает минимальный уровень для представления знаний в Сети. Спецификация RDF опирается на ранние стандарты, лежащие в основе Web:
- Unicode служит для представления символов алфавитов различных языков,
- URI используется для определения уникальных идентификаторов ресурсов,
- XML и XML Schema - для структурирования и обмена информацией и для хранения RDF (XML синтаксис RDF).
Кроме RDF был разработан язык описания структурированных словарей для RDF - RDF Schema (RDFS). Он предоставляет минимальный набор средств для спецификации онтологий. RDFS получил статус рекомендации W3C в 2004 году. Однако препятствием для Semantic Web стало то, что документов, написанных на языке RDF/RDFS, было относительно мало. В период с 2001 по 2004 годы шла интенсивная работа по созданию программных средств для обработки и автоматической генерации RDF-документов.
Результатом в 2004 году стал язык GRDDL (Gleaning Resource Descriptions form Dialects of Languages). Его назначение состоит в предоставлении средств для извлечения RDF-триплетов из XML и XHTML данных (в особенности это относится к документам, автоматически генерируемым из закрытых баз данных). Развивалось и программное обеспечение для Semantic Web. В области создания библиотек классов и построения логических выводов над RDF-графами была создана библиотека Jena Framework, в области создания модулей расширения для браузеров - Simile для Firefox. В области создания визуальных сред редактирования большое число редакторов онтологий стали поддерживать RDF.
В 2004 году статус рекомендации получил язык OWL (Web Ontology Language). Он имеет 3 диалекта (3 множества структурных единиц), используемых в зависимости от требуемой выразительной мощности. OWL фактически является надстройкой над RDF/RDFS и поддерживает эффективное представление онтологий в терминах классов и свойств, обеспечение простых логических проверок целостности онтологии и связывание онтологий друг с другом (импорт внешних определений). Многие формализмы описания знаний могут быть отображены на формализм OWL (два из его диалектов - OWL Lite и OWL DL - соответствуют двум дескриптивным логикам, имеющим разную выразительную силу). Большое число создаваемых в настоящее время онтологий кодируются на OWL; уже существующие онтологии транслируются в него.
На этом работа по обеспечению Semantic Web необходимыми стандартами не остановилась. В 2005 году началась работа над форматом обмена правилами - RIF (Rule Interchange Format). Его назначение - соединить в одном стандарте несколько формализмов для описания правил (по которым может осуществляться нетривиальный логический вывод): логику клауз Хорна, логики высших порядков, продукционные модели и т.п.
Язык SPARQL - язык запросов к RDF-хранилищам - в январе 2008 года приобрел статус официальной рекомендации Консорциума W3C. Синтаксически он очень похож на SQL. Он уже широко используется разработчиками информационных систем.
На рис. 3.1 представлена диаграмма, называемая иногда стеком (или даже "слоеным пирогом") Semantic Web.
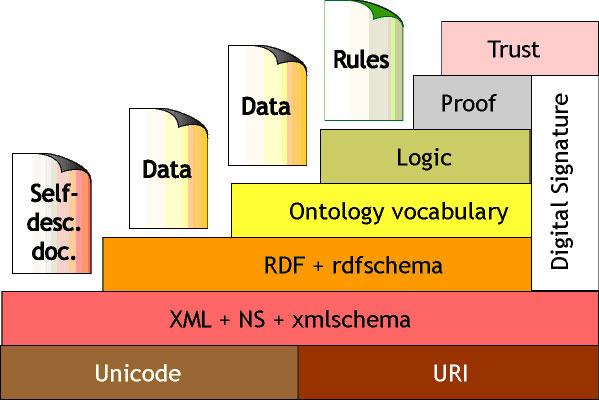
Все основные уровни диаграммы были описаны выше. Уровням "Ontology vocabulary" и "Logic" соответствуют OWL и RIF. Уровень "Trust" на данный момент остается незатронутым никакими стандартами. Здесь и возникает одно из существенных препятствий к реализации всей идеи: поддержка автоматической проверки корректности и правдивости информации. В самом деле, у многих поставщиков семантических описаний может возникнуть соблазн "обмануть" программу-агента, предоставив информацию, не соответствующую действительности, либо навязчивую рекламу, как это в настоящее время проделывается с поисковыми машинами, спам-фильтрами и т.п.
Еще одним камнем преткновения для создания Semantic Web является фактическое отсутствие работающих интеллектуальных агентов. Не всякая программа, обрабатывающая RDF, является агентом Semantic Web, точно так же как и не всякая программа, написанная на ПРОЛОГЕ, является приложением в области искусственного интеллекта.
Завершая раздел, нужно подчеркнуть, что Семантическая Сеть продолжает развиваться - появляются новые стандарты.
Новый шаг - начало разработки формата обмена правилами RIF, построенными над онтологиями, и определение требований и области его применения. Появилось множество свободно распространяемых библиотек для разработки приложений "под Semantic Web". Главными задачами, стоящими перед сообществом Семантической Сети, остаются создание новых онтологий и согласование существующих.

На рис. 3.2 наглядно видна тенденция последних 3-7 лет, которую можно условно назвать "прилив Семантической Сети".