
|
Здравствуйте! Записался на ваш курс, но не понимаю как произвести оплату. Надо ли писать заявление и, если да, то куда отправлять? как я получу диплом о профессиональной переподготовке? |
Инспектор
Вы можете этот курс.
Опубликован: 11.02.2005 | Уровень: специалист | Доступ: платный
Лекция 12:
Переход от данных к конечному автомату
Построение графа автомата, достаточного для решения задачи, но не обязательно оптимального, можно реализовать, используя следующее рекуррентное описание алгоритма.
-
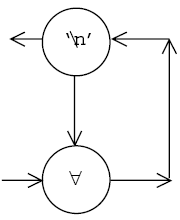
Если множество слов пустое, то граф задается структурой:
Вершина, содержащая \n, объявляется выходной для графа в целом (есть горизонтальная исходящая из нее дуга, которая никуда не ведет). Она обозначается далее E. На данном этапе входной вершиной является та, которая пропускает все символы (по определению у нее нет вертикальной исходящей дуги).
-
Пусть граф G определяет автомат, распознающий некоторое множество слов
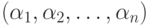 , и пусть есть слово
, и пусть есть слово  , которое нужно добавить к этому множеству. Добавление слова достигается с помощью следующих шагов:
, которое нужно добавить к этому множеству. Добавление слова достигается с помощью следующих шагов:-
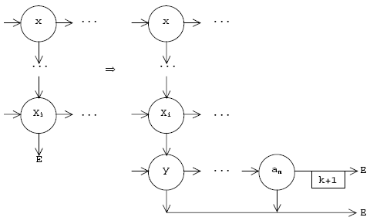
по слову
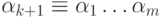 строится список вида
строится список видакоторый рассматривается как заготовка для пополнения графа G
- если есть собственная часть какого-либо слова, то склейка заготовки с графом сводится к добавлению пометки k+1 у соответствующей горизонтальной дуги; в противном случае перейти к следующим пунктам;
-
для каждого слова
 из
из 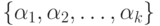 ищутся такие
ищутся такие 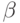 и
и 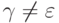 ,
, 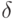 и
и  что
что 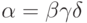 ,
,  и
и 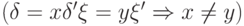 . В графе G есть фрагменты, отвечающие за распознавание
. В графе G есть фрагменты, отвечающие за распознавание 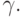 Следовательно, надо склеить заготовку с каждым из таких фрагментов, т. е. вставить вертикальную дугу от последнего вертикального преемника вершины x x1,...,i к остатку заготовки:
Следовательно, надо склеить заготовку с каждым из таких фрагментов, т. е. вставить вертикальную дугу от последнего вертикального преемника вершины x x1,...,i к остатку заготовки: - повторять третий пункт, пока можно найти соответствующие
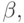
 и
и 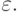
-
- Последовательно выполнить процесс, описанный в пункте 2, для всех слов из набора.
Улучшение данного алгоритма возможно, в частности, за счет стандартного приема оптимизации задач, обрабатывающих сложно структурированную взаимосвязанную информацию. Этот прием состоит в упорядочении данных. Слова можно расположить таким образом, что будет минимизировано число проверок в каждом (вертикальном) состоянии автомата. Другая идея улучшения алгоритма — в некоторых случаях, когда линейные участки распознавания оказываются относительно независимыми, вычислить локально оптимальные последовательности и распознавать сразу их вхождения. Такое агрегирование данных также является стандартным приемом. Наконец, чуть-чуть повысит эффективность размножение выходной вершины графа. Подобные модификации алгоритма предлагается выполнить самостоятельно.