
|
Где проводится профессиональная переподготовка "Системное администрирование Windows"? Что-то я не совсем понял как проводится обучение. |
Инспектор
Вы можете этот курс.
Опубликован: 04.07.2008 | Уровень: специалист | Доступ: платный | ВУЗ: Европейский Университет в Санкт-Петербурге
Лекция 15:
Наблюдение, профилирование и трассировка работы приложений и системы. Концепция DTrace
Лирическое отступление №1. О преимуществах DTrace
Появившись всего несколько лет назад в Solaris, ныне DTrace "перебрался" и на другие Unix системы. Более года назад был сделан порт для FreeBSD, чуть позже – для MacOS X и совсем недавно – для QNX. Таким образом, DTrace претендует на то, чтобы стать стандартным средством трассировки для Unix.
Почему же DTrace оказался настолько привлекательным? Во-первых, подавляющее большинство аналогичных инструментов используют статический код, который, будучи "вживлен" в ключевые места кода системы, позволяет отслеживать ограниченное число событий при минимальном действии на систему. Такой подход (реализованный, к примеру, в KLogger для Linux) позволяет даже довольно точно оценивать накладные расходы, возникающие при использовании данного инструмента, но ограничивает множество системных объектов, доступных для наблюдения. DTrace позволяет существенно расширить "область видимости", применяя как статические, так и динамические методы инструментовки кода
Во-вторых, DTrace позволяет получить информацию, пожалуй, о всех составляющих системы. Скажем, утилита truss(1), как и DTrace, тоже позволяет трассировать системные вызовы и сигналы, но ничего более. Для того, чтобы посмотреть статистику использования виртуальной памяти или ядра, потребуются утилиты vmstat(1M) или kstat(1M) соответственно. DTrace же собирает все эти утилиты "под одну крышу", попутно решая ещё одну проблему. Если ранее при анализе необходимо было коррелировать вывод статистических утилит чуть ли не "вручную", то теперь это можно запрограммировать в скрипте на D.
Конечно, этими двумя пунктами список не ограничивается. Но раз уж речь зашла о truss(1), стоит упомянуть и о том, что для сбора информации эта утилита пользуется файловой системой proc(4), которая разрабатывалась для традиционных средств отладки6К коим в первую очередь относятся отладчики – например, gdb или же dbx из пакета компиляторов и средств разработки Sun Studio.. Поэтому зачастую для сбора информации исследуемый процесс останавливается, далее снимается требуемая информация о состоянии и процесс запускается заново. Если ваш сервер обслуживает биржевые операции, то я бы не советовал использовать такой метод трассировки во время торгов. Что же предлагает DTrace? Чтобы разобраться, давайте поговорим еще немного про провайдер syscall.
Секрет фокуса syscall
В начале лекции мы говорили про методологию инструментирования (модификации кода системы инструментальными средствами), которая используется в провайдере fbt. Чтобы продемонстрировать тот факт, что методология может быть различной и каждый провайдер DTrace вправе использовать свою технику для инструментирования, посмотрим, что происходит в случае использования провайдера syscall. Для этого нам опять понадобится помощь уже знакомого модульного отладчика mdb.
Метод, которым пользуется провайдер syscall, чтобы отслеживать входы в и выходы из системных вызовов – модификация таблицы системных вызовов. При помощи mdb можно "подсмотреть" за тем, как это происходит. Структура элементов таблицы системных вызовов (struct sysent, ссылка на строчку кода может "поехать" со временем) определена в http://src.opensolaris.org/source/xref/onnv/onnv-gate/usr/src/uts/common/sys/systm.h#305
Все примеры в этой лекции проверялись в Solaris 10 update 4, так что и в любой свежей версии Solaris Express они тоже сработают.
mdb -k
Loading modules: [ unix genunix specfs dtrace cpu.AuthenticAMD.15
uppc pcplusmp scsi_vhci zfs random ip hook neti sctp arp usba
s1394 qlc fctl md lofs audiosup sppp ipc ptm crypto nfs cpc fcp
fcip logindmux ufs sv nsctl sdbc ii rdc mpt ]
> ::sizeof struct sysent
sizeof (struct sysent) = 0x20
> sysent+7*0x20::array struct sysent 1 |::print struct sysent
{
sy_narg = '\0'
sy_flags = 0x1
sy_call = 0
sy_lock = 0
sy_callc = wait
}Включаем датчик на wait (в другом терминале #dtrace -n 'syscall::wait:entry' ) и еще раз смотрим запись в таблице вызовов для wait:
> sysent+7*0x20::array struct sysent 1 |::print struct sysent
{
sy_narg = '\0'
sy_flags = 0x1
sy_call = 0
sy_lock = 0
sy_callc = dtrace_systrace_syscall
}Замена вызова системного вызова на dtrace_systrace_syscall позволяет передать управление DTrace, который снимет необходимую для трассировки информацию до и после системного вызова, передав управление "настоящему" wait, в соответствующий момент.
Провайдер proc
Этот провайдер предназначен для трассировки системных событий, отображающих процесс исполнения кода (запуск и завершение, отправка и обработка сигналов). Казалось бы, это можно сделать при помощи провайдера syscall и соответствующих датчиков ( exec, fork и т.п.). Почему же понадобился proc? Дело в том, что управление процессами и сигналами осуществляется не только системными вызовами, а еще и функциями из стандартной библиотеки С (особенно это касается сигналов и легковесных процессов – LWP), поэтому только лишь трассировкой системных вызовов не обойтись. Да и "специализация" провайдера делает его использование более удобным при написании скриптов. К примеру, датчику create в качестве аргумента передаётся ссылка на структуру psinfo_t, которая содержит, пожалуй, всю информацию о создаваемом процессе c точки зрения операционной системы.
Провайдер содержит небольшое количество датчиков (список датчиков можно посмотреть с помощью команды dtrace -l -P proc ), из названий очевидно следует их предназначение. В качестве примера посмотрим, каким образом можно отследить цепочку запуска процессов при вызове определённой команды :
#pragma D option quiet
proc:::exec
{
self->parent = execname;
}
proc:::exec-success
/self->parent != NULL/
{
@gs[self->parent, execname] = count();
self->parent = NULL;
}
proc:::exec-failure
/self->parent != NULL/
{
@gf[self->parent, execname] = count();
self->parent = NULL;
}
END
{
printa(" %s -> %s (%@d)\n", @gs );
}Пусть скрипт хранится в файле exec-chain.d, а в качестве подопытного возьмём команду su:
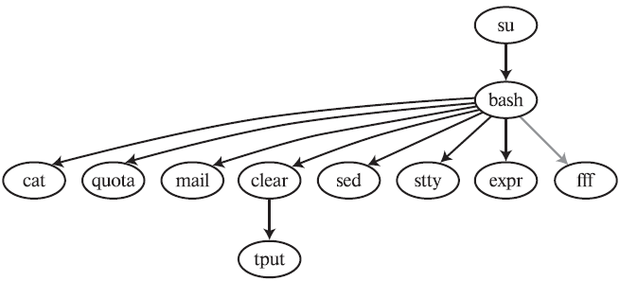
joda#dtrace -s exec-chain.d -c 'su – obi-wan' obi-wan#exit bash -> clear (1) bash -> cat (1) bash -> quota (1) bash -> mail (1) bash -> sed (1) clear -> tput (1) su -> bash (1) bash -> stty (2) bash -> expr (20) joda#
Как нетрудно заметить, порядок вывода не соответствует хронологическому порядку, поскольку DTrace гарантирует регистрацию события, а порядок вывода на печать – нет, оставляя эту задачу автору. Если важно соблюсти временную последовательность, то можно воспользоваться одной из встроенных переменных для учёта времени timestamp, vtimestamp или walltimestamp. Для относительного учёта вполне подойдёт переменная timestamp, стандартный шаблон её использования: инициализация thread-local переменной в датчике
BEGIN {
self->start = timestamp;
}и регистрация времени события относительно начального момента при помощи конструкции
timestamp-self->start
после чего нужно отсортировать список событий по времени. Допустим, exec-chain.d можно изменить, добавив в кортеж агрегации @gs последнюю приведённую конструкцию, затем добавить вывод отметки времени и передать вывод утилите sort.
Этот, прямо скажем, довольно простой пример демонстрирует очень мощный принцип: вывод скрипта может быть данными, предназначенными для последующей обработки другими утилитами. Более того, вывод скрипта на D может представлять из себя код программы на некотором языке (примеры, где скрипт на D выводит скрипт на perl, можно легко найти в Интернет). Если в примере exec-chain.d (без модификаций с timestamp ) заменить тело компоненты END на
END
{
printf( "digraph ExecGraph {\n" );
printa(" \"%s\" -> \"%s\" [weight=%@d];\n", @gs );
printa(" \"%s\" -> \"%s\" [color=red,weight=%@d];\n",@gf );
printf("}\n");то после отработки скрипта получим описание графа на языке dot, который используется в пакете визуализации графов Graphviz (http://www.graphviz.org/About.phр). Сохранив вывод в файле graph.dot, сгенерируем дерево вызовов:
#dot -Tjpg graph.dot -o graph.jpg
Это даёт нам очень наглядную картинку запускаемых командой su процессов. Красными дугами в полученном графе будут обозначаться неудавшиеся запуски. Уверен, что, скорей всего, команда su у вас работает нормально и красных дуг на картинке не будет. Мне пришлось специально моделировать ситуацию для того, чтобы получить такой граф.
Трассировку запусков можно ещё получить совсем простой командой в одну строчку (пример взят с http://www.solarisinternals.com/wiki/index.php/DTrace_Topics_One_Liner, где вы найдете массу полезных примеров в одну строку для различных провайдеров):
#dtrace -n 'proc:::exec-success { trace(curpsinfo->pr_psargs); }'Этот пример может пригодиться для трассировки удачных запусков в системе, однако мало чего расскажет о взаимной зависимости запускаемых приложений. Воспользовавшись же рассмотренным ранее способом визуализации, можно устанавливать не только "родственные" отношения между запущенными процессами, но и даже дерево вызовов функций произвольного приложения.
Александр Тагильцев