

| Россия, Новосибирск, НГПУ, 2009 |
Инспектор
Спонсор: Microsoft
Вы можете этот курс.
Опубликован: 22.04.2008 | Уровень: профессионал | Доступ: платный
Лекция 2:
Основы программирования на MPI
2.4. Коллективные операции и их исполнение
Коллективные операции в MPI выполняют следующие функции:
- MPI_Reduce,
- MPI_Allreduce,
- MPI_Reduce_scatter и
- MPI_Scan.
Помимо встроенных, пользователь может определять использовать свои собственные коллективные операции. Для этого служат функции MPI_Op_create и MPI_Op_free, а также специальный тип данных MPI_Usr_function.
Алгоритм исполнения всех коллективных функций одинаков: в каждом процессе имеется массив с данными и над элементами с одинаковым номеров в каждом из процессов производится одна и та же операция (сложение, произведение, вычисление максимума/минимума и т.п.). Встроенные коллективные функции отличаются друг от друга способом размещения результатов в процессах.
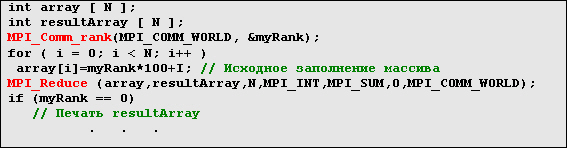
MPI_Reduce
Данная функция выполняет коллективную операцию во всех процессах группы и помещает результат в процесс с рангом root.
Формат вызова:
MPI_Reduce ( &sendbuf, &recvbuf, count, datatype, op, root, comm )
Пример поэлементного суммирования массивов:
Встроенных коллективных операций в MPI насчитывается 12:
- MPI_MAX и MPI_MIN - поэлементные максимум и минимум
- MPI_SUM - сумма векторов
- MPI_PROD - произведение векторов
- MPI_LAND, MPI_BAND, MPI_LOR, MPI_BOR, MPI_LXOR, MPI_BXOR - логические и двоичные (бинарные) операции И, ИЛИ, исключающее ИЛИ
- MPI_MAXLOC, MPI_MINLOC - поиск индекса процесса с максимумом/минимумом значения и самого этого значения
Эти функции могут работать только со следующими типами данных (и только ними):
- MPI_MAX, MPI_MIN - целые и вещественные
- MPI_SUM, MPI_PROD - целые, вещественные (комплексные - для Фортрана)
- MPI_LAND, MPI_LOR, MPI_LXOR - целые
- MPI_BAND, MPI_BOR, MPI_BXOR - целые и типа MPI_BYTE
- MPI_MAXLOC, MPI_MINLOC - вещественные
MPI_Allreduce
Применяет коллективную операцию и рассылает результат всем процессам в группе.
Формат вызова:
MPI_Allreduce (&sendbuf, &recvbuf, count, datatype, op, comm)
MPI_Reduce_scatter
Функция применяет вначале коллективную операцию к векторам всех процессов в группе, а затем результирующий вектор разбивается на непересекающиеся сегменты, которые распределяются по процессам. Данная операция эквивалентна вызову функции MPI_Reduce, за которым производится вызов MPI_Scatter.
Формат вызова:
MPI_Reduce_scatter (&sendbuf, &recvbuf, recvcount, datatype, op, comm)
MPI_Scan
Данная операция аналогична функции MPI_Allreduce в том отношении, что после ее выполнения каждый процесс получает результирующий массив. Главное отличие данной функции состоит в том, что содержимое результирующего массива в процессе i является результатом выполнения коллективной операции над массивами из процессов с номерами от 0 до i включительно.
Формат вызова:
MPI_Scan ( &sendbuf, &recvbuf, count, datatype, op, comm )
2.5. Управление процессами в MPI
Управление процессами в MPI происходит посредством организации их в группы, управляемые коммуникаторами
Группа есть упорядоченное множество процессов. Каждому процессу в группе присваивается уникальный целочисленный номер - ранг. Значения ранга изменяются от 0 до N - 1, где N есть количество процессов в группе. В MPI, группа представляется в памяти компьютера в виде объекта, доступ к которому программист осуществляет с помощью "обработчика" (handle) MPI_Group. С группой всегда связывается коммуникатор, также представляемый в виде объекта.
Коммуникатор обеспечивает взаимодействие между процессами, относящимися к одной и той же группе. Поэтому, во всех MPI-сообщениях одним из аргументов задается коммуникатор. Коммуникаторы как объекты также доступны программисту с помощью обработчиков. В частности, обработчик коммуникатора, который включает в себя все процессы задачи, называется MPI_COMM_WORLD.
Основные цели средств организации процессов в группы:
- позволяют организовывать задачи, объединяя в группы процессы, основываясь на их функциональном назначении;
- позволяют осуществлять коллективные операции (см. Раздел 4) только на заданном множестве процессов;
- предоставляют базис для организации пользователем виртуальных топологий;
- обеспечивают безопасную передачу сообщений в рамках одной группы.
Группы/коммуникаторы являются динамическими - они могут создаваться и уничтожаться во время исполнения программы.
Процессы могут относиться к более, чем одной группе/коммуникатору. В каждой группе/коммуникаторе, каждый процесс имеет уникальный номер (ранг).
MPI обладает богатой библиотекой функций, относящихся к группам, коммуникаторам и виртуальным топологиям, типичный сценарий использования которых представлен ниже:
- Получить обработчик глобальной группы, связанной с коммуникатором MPI_COMM_WORLD, используя функцию MPI_Comm_group.
- Создать новую группу как подмножество глобальной группы, используя функцию MPI_Group_incl.
- Создать новый коммуникатор для вновь созданной группы, используя функцию MPI_Comm_create.
- Получить новый ранг процесса во вновь созданном коммуникаторе, используя функцию MPI_Comm_rank.
- Выполнить обмен сообщениями между процессами в рамках вновь созданной группы.
- По окончании работы, освободить (уничтожить) группу и коммуникатор, используя функции MPI_Group_free и MPPI_Comm_free.
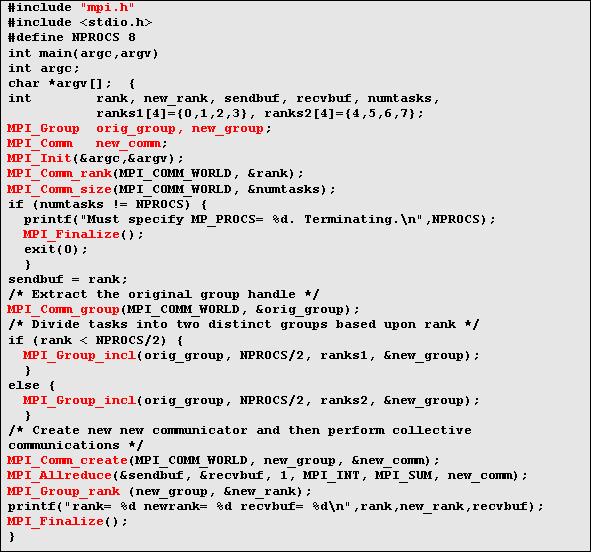
Пример, показанный ниже, демонстрирует создание двух отдельных групп процессов для выполнения коллективных операций внутри каждой из них.
Вывод программы на консоль будет таким:
rank= 7 newrank= 3 recvbuf= 22 rank= 0 newrank= 0 recvbuf= 6 rank= 1 newrank= 1 recvbuf= 6 rank= 2 newrank= 2 recvbuf= 6 rank= 6 newrank= 2 recvbuf= 22 rank= 3 newrank= 3 recvbuf= 6 rank= 4 newrank= 0 recvbuf= 22 rank= 5 newrank= 1 recvbuf= 22
2.6. Организация логических топологий процессов
В терминах MPI, виртуальная топология описывает отображение MPI процессов на некоторую геометрическую конфигурацию процессоров.
В MPI поддерживается два основных типа топологий - декартовые (решеточные) топологии и топологии в виде графа.
MPI-топологии являются виртуальными - связь между физической структурой параллельной машины и топологией MPI-процессов может и отсутствовать.
Виртуальные топологии строятся на основе групп и коммуникаторов, и "программируется" разработчиком параллельного приложения.
Смысл использования виртуальных топологий заключается в том, что они в некоторых случаях удобны для задач со специфической коммуникационной структурой. Например, декартова топология удобна для задач, в которых обрабатывающие элементы в процессе вычислений обмениваются данными только со своими 4-мя непосредственными соседями. В конкретных реализациях, возможна оптимизация отображения MPI-процессов на физическую структуру заданной параллельной машины.
В примере, показанном ниже, создается декартова топология 4 х 4 из 16 процессов, и каждый процесс сообщает свой ранг своим соседям, получая от них их собственные ранги.
Вывод данной программы на консоль будет следующим:
rank= 0 coords= 0 0 neighbors(u,d,l,r)= -3 4 -3 1
rank= 0 inbuf(u,d,l,r)= -3 4 -3 1
rank= 1 coords= 0 1 neighbors(u,d,l,r)= -3 5 0 2
rank= 1 inbuf(u,d,l,r)= -3 5 0 2
rank= 2 coords= 0 2 neighbors(u,d,l,r)= -3 6 1 3
rank= 2 inbuf(u,d,l,r)= -3 6 1 3
. . . . .
rank= 14 coords= 3 2 neighbors(u,d,l,r)= 10 -3 13 15
rank= 14 inbuf(u,d,l,r)= 10 -3 13 15
rank= 15 coords= 3 3 neighbors(u,d,l,r)= 11 -3 14 -3
rank= 15 inbuf(u,d,l,r)= 11 -3 14 -3