

|
Добрый день, Я прошёл платный курс по программе «Архитектурные решения на базе аппаратных платформ IBM» получил диплом №ПК 100848460. Как мне получить его ? Вы отправите его почтой ? |
Инспектор
Вы можете этот курс.
Опубликован: 09.01.2008 | Уровень: профессионал | Доступ: платный | ВУЗ: Компания IBM
Лекция 9:
Компоненты и функции архитектуры HACMP
Основные функции HACMP
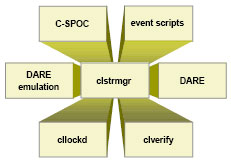
Состав ПО HACMP
- clstrmgr (Cluster Manager) – основной процесс, мониторинг узлов кластера
- DARE (Dynamic Automatic Reconfiguration Event) – динамическое изменение конфигурации кластера
- cllockd - конкурентный доступ приложений к разделяемым дискам (опционально)
- C-SPOC (Cluster Single Point Of Control) – администрирование кластера из единой точки
- clverify – проверка конфигурации кластера
- event scripts – скрипты для обработки событий
HACMP состоит из набора программных компонентов. Cluster manager (clstrmgr) – основной процесс, отвечающий за мониторинг узлов.
Кластер допускает динамическое изменение конфигурации (без остановки). Эта возможность называется Dynamic Automatic Reconfiguration Event (DARE).
C-SPOC – набор меню SMIT для управления кластером из единой точки.
Событийные скрипты – это shell-скрипты, которые запускаются в ответ на какое-либо событие, касающееся кластера.
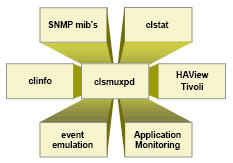
Дополнительные компоненты HACMP
- clsmuxpd – SNMP-subagent для удаленного мониторинга кластера
- clinfo – API для связи между Cluster Manager и приложениями; возможность удаленного мониторинга состояния кластера
- Application Monitoring – Мониторинг состояния приложений
HACMP имеет также дополнительный набор компонентов для администрирования, тестирования, удаленного мониторинга и верификации.
Служба simple network management protocol peer daemon (clsmuxpd) предоставляет возможности для управления и мониторинга кластера удаленно, используя SNMP-менеджер, например, IBM Tivoli Netview.
Процесс clinfo предоставляет API для взаимодействия между clstrmgr и специфичным приложением пользователя. Clinfo также предоставляет возможности удаленного мониторинга.
Мониторинг приложений (application monitoring) может быть использован для слежения за состоянием приложений и их рестарта в случае необходимости.
Обработка событий в кластере
HACMP не является "коробочным" решением!
HACMP обладает достаточной гибкостью для детального конфигурирования
HACMP обеспечивает:
- Мониторинг компонентов
- Обнаружение изменения состояния
- Диагностику и восстановление после сбоев
HACMP поставляется вместе с событийными скриптами, которые обрабатывают большинство сценариев сбоя. Однако, все ситуации заранее предусмотреть невозможно – для этого есть возможность добавления своих пред- и пост-обработчиков событий.
Планирование кластера
- Создание диаграммы кластера.
- Заполнение форм (planning sheets).
- Устранение общих точек сбоя (SPOF).
- Дублирование электропитание и шин.
- План тестирования.
- Методичный подход.
Вот только несколько советов для планирования кластера:
- Всегда рисуйте диаграмму предполагаемого решения.
- Используйте специальные формы (planning worksheets) и/или Javabased On-Line Planning Worksheets.
- Устраните как можно больше единых точек сбоя (SPOF).
- Используйте продублированные адаптеры, шины, источники питания.
Встроенные функции HACMP
В HACMP встроено автоматическое обнаружение и реагирование на события:
- Сбой узла
- Сбой сетевого адаптера
- Сбой сети
HACMP реально обнаруживает только три типа сбоев.
- A node failure (сбой узла).
- A network adapter failure (сбой сетевого адаптера).
- A network failure (сбой сети).
Остальные сбои обнаруживаются компонентами AIX (например, LVM), имеется возможность инициирования кластерного события при их возникновении.
Реакция на сбой
- Реакция кластера на сбой завистит от типа сбоя и настроек кластера.
- Настройки кластера зависят от требований приложения.
- Обычная реакция - подхват нагрузки резервным компонентом.
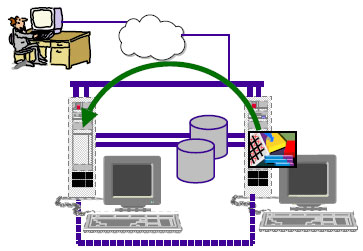
HACMP обычно отвечает на сбой использованием доступного эквивалентного компонента для подхвата нагрузки, бывшей на основном компоненте.
Например, при сбое узла HACMP инициирует fallover - действие, которое состоит из перемещения ресурсных групп, работавших ранее на сбойном узле, на оставшийся работоспособным узел. В случае сбоя сетевого адаптера HACMP обычно переносит IP адрес, использующийся для доступа клиентов, на другой, доступный сетевой адаптер на том же узле.
При отсутствии резервных адаптеров, HACMP инициирует fallover.
Реинтеграция после восстановления
- Реакция кластера на восстановление сбойного компонента зависит от типа сбоя и настроек кластера.
- Настройки кластера зависят от требований приложения.
- Возможен ручной и автоматический обратный перенос нагрузки.
Если ранее вышедший из строя компонент восстанавливается, он должен быть реинтегрирован в кластер.
Александр Панченко