


|
Добрый день, Я прошёл платный курс по программе «Архитектурные решения на базе аппаратных платформ IBM» получил диплом №ПК 100848460. Как мне получить его ? Вы отправите его почтой ? |
Инспектор
Вы можете этот курс.
Опубликован: 09.01.2008 | Уровень: профессионал | Доступ: платный | ВУЗ: Компания IBM
Лекция 2:
Технология POWER
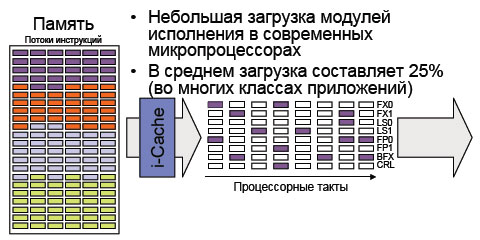
Предпосылки для многопоточной работы
На современных процессорах находится большое количество специализированных модулей исполнения, каждый из них способен выполнять небольшую часть общего набора инструкций – часть выполняют целочисленные операции, часть – операции с плавающей точкой, и т.д. Эти модули способы работать параллельно, так, что несколько инструкций программы могут быть выполнены одновременно.
Однако, обычные процессоры выполняют инструкции из одного потока. Несмотря на улучшения микроархитектуры, утилизация модулей исполнения остается низкой. В среднем, она составляет 25%. Для увеличения утилизации модулей исполнения, разработчики используют параллелизм на уровне нитей, при котором физический процессор выполняет инструкции из разных нитей. Для операционной системы такое процессорное ядро выглядит как симметричный мультипроцессор с двумя логическими процессорами.
Coarse-grained multi-threading
При кропноблочной (coarse-grained) многопоточной обработке, только одна нить выполняется в один момент времени. Когда нить сталкивается с событием, предусматривающим долгое ожидание, например, промах по кэшу, аппаратура переключает управление на вторую нить, вместо того, чтобы простаивать. Эта схема увеличивает общую пропускную способность. Обе нити совместно используют многие системные ресурсы, например, архитектурные регистры. Однако, переключение с одной нити на другую занимает несколько процессорных тактов. IBM реализовал такую схему в системе pSeries Model 680.
Крупноблочная многопоточность была представлена в серии процессоров IBM Star (например, RS64-IV, в системе S85), чтобы улучшить производительность системы для многих задач. Многопоточный процессор улучшает использование ресурса ядра процессора, выполняя несколько аппаратных потоков параллельно. В линии Star одновременно выполнялось два параллельных потока.
Процессор (например, RS64-IV) способен сохранять контекст двух нитей
- Быстрое переключение между нитями минимизирует потерю тактов из-за ожиданий ввода-вывода или промахов в кэше
- Может дать улучшение производительности ~20% (OLTP-задачи)
Дает преимущество только при более, чем двухкратном превышении количества активных нитей количества процессоров
AIX должен создать нить-"пустышку" при нехватке реальных нитей
Ненужные переключения на нити-"пустышки" могут снизить производительность на ~20%
Основная идея состоит в том, что, когда одна или более нитей (потоков) процессора остановлены на большое временя ожидания (например, при промахе в кэш), другие работают на ядре. Однако, ОС AIX должна была знать о различии между логическими и физическими процессорами и отвечала за то, что каждый логический процессор имел диспетчеризируемую нить - даже создавая нити – "пустышки" (idle).
Необходимо отметить, что крупноблочная многопоточность широко никогда не использовалась клиентами. Частично это было вследствие того, что это не было активизировано по умолчанию и требовало, перезагрузки для активизации. Другой причиной было то, что прирост производительности был произвольным, и мог, реально, иметь отрицательную величину. Для рабочих нагрузок с высокими соотношениями нить/процессор (например, TPC-C), HMT может дать ~20% прирост производительности.
При других нагрузках, например, системах бизнес-аналитики (BI), где соотношение нить/процессор - <2:1, AIX вынужден создавать фиктивные потоки. Переключение на\из этих фиктивных потоков занимает приблизительно шесть процессорноых тактов, тогда как без крупномоблочной многопоточности AIX вообще не производил бы переключение контекста. Другой недостаток крупноблочной многопоточности состоял в том, что он отключал динамическое освобождение процессоров (Dynamic CPU Deallocation).
Fine-grained multi-threading
Вариант крупномоблочной многопоточности - детальная многопоточность. Машины этого класса выполняют потоки в последовательных циклах, циклическим способом. Этот дизайн требует дублирования аппаратных средств. Когда поток сталкивается с длительным ожиданием, его такты остаются неиспользованными. В процессорах POWER4 был реализован SMP на чипе, но не была реализована детальная многопоточность.
Выполнение инструкций в POWER5
Ядро процессора POWER5 поддерживает как многопоточный режим (SMT), так и однопоточый. На этой диаграмме показан конвейер инструкций POWER5, который является идентичным POWER4.
Все задержки в POWER5, включая ошибки модуля предсказания переходов и время ожидания загрузки с удачным обращением в кэш данных L1, являются такими же, как в POWER4. Идентичная конвейерная структура позволяет оптимизации, разработанной для POWER4, работать на POWER5. В режиме SMT, POWER5 использует два отдельных регистра адреса вызова команды (instruction fetch address registers), чтобы хранить счетчики для двух потоков.
В однопоточном режиме, POWER5 использует только одну программу и может выбрать команды для этой нити каждый такт. Он может выбирать до восьми команд из кэша инструкций каждый такт.
Некоторые различия:
В процессоре 120 регистров общего назначения (GPR) и 120 регистров с плавающей точкой (FPR).
В однопоточном режиме, POWER5 делает все физические регистры доступными единственной нити, позволяя более высокий параллелизм на уровне инструкций.
L1 кэш инструкций и данных имеет тот же самый размер, как и в POWER4 - 64 КБ и 32 КБ - но их ассоциативность удвоилась.
Александр Панченко