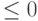 , пропуска байт нет. Возвращается реально пропущенное число байт. Если это значение
, пропуска байт нет. Возвращается реально пропущенное число байт. Если это значение 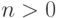 , то вперед, к концу файла. Если
, то вперед, к концу файла. Если  , то позиция головки не меняется. Возвращается число реально пропущенных байт. Оно может быть меньше n – например, из-за достижения конца файла.
, то позиция головки не меняется. Возвращается число реально пропущенных байт. Оно может быть меньше n – например, из-за достижения конца файла.| Изменяется размер ячеек памяти при записи оболочечных данных?Или в jawa это пока не предусмотренно |
Преподаватель
Вы можете этот курс.
Опубликован: 04.12.2009 | Уровень: специалист | Доступ: свободно
Лекция 7:
Важнейшие объектные типы
Работа с потоками ввода-вывода
Стандартные классы Java, инкапсулирующие работу с данными (оболочечные классы для числовых данных, классы String и StringBuffer, массивы и т.д.), не обеспечивают поддержку чтения этих данных из файлов или запись их в файл. Вместо этого используется весьма гибкая и современная, но не очень простая технология использования потоков (Streams).
Поток представляет накапливающуюся последовательность данных, поступающих из какого-то источника. Порция данных может быть считана из потока, при этом она из потока изымается. В потоке действует принцип очереди – "первым вошел, первым вышел".
В качестве источника данных потока может быть использован как стационарный источник данных (файл, массив, строка), так и динамический – другой поток. При этом в ряде случаев выход одного потока может служить входом другого. Поток можно представить себе как трубу, через которую перекачиваются данные, причем часто в таких "трубах" происходит обработка данных. Например, поток шифрования шифрует данные, полученные на входе, и при считывании из потока передает их в таком виде на выход. А поток архивации сжимает по соответствующему алгоритму входные данные и передает их на выход. "Трубы" потоков можно соединять друг с другом – выход одного со входом другого. Для этого в качестве параметра конструктора потока задается имя переменной, связанной с потоком - источником данных для создаваемого потока.
Буферизуемые потоки имеют хранящийся в памяти промежуточный буфер, из которого считываются выходные данные потока. Наличие такого буфера позволяет повысить производительность операций ввода-вывода, а также осуществлять дополнительные операции – устанавливать метки (маркеры) для какого-либо элемента, находящегося в буфере потока и даже делать возврат считанных элементов в поток (в пределах буфера).
Абстрактный класс InputStream ("входной поток") инкапсулирует модель входных потоков, позволяющих считывать из них данные. Абстрактный класс OutputStream ("выходной поток") - модель выходных потоков, позволяющих записывать в них данные. Абстрактные методы этих классов реализованы в классах-потомках.
Все методы класса InputStream, кроме markSupported и mark, возбуждают исключение IOException – оно возникает при ошибке чтения данных.
Все методы этого класса возбуждают IOException в случае ошибки записи.
Не все классы потоков являются потомками InputStream/OutputStream. Для чтения строк (в виде массива символов) используются потомки абстрактного класса java.io.Reader ("читатель"). В частности, для чтения из файла – класс FileReader. Аналогично, для записи строк используются классы - потомки абстрактного класса java.io.Writer ("писатель"). В частности, для записи массива символов в файл – класс FileWriter.
Имеется еще один важный класс для работы с файлами, не входящий в иерархии InputStream/OutputStream и Reader/ Writer. Это класс RandomAccessFile ("файл с произвольным доступом"), предназначенный для чтения и записи данных в произвольном месте файла. Такой файл с точки зрения класса RandomAccessFile представляет массив байт, сохраненных на внешнем носителе. Класс RandomAccessFile не является абстрактным, поэтому можно создавать его экземпляры.
Все операции чтения и записи начинаются с позиции, задаваемой файловым указателем перед началом операции. После каждой такой операции файловый указатель сдвигается к концу файла на число позиций (байт), соответствующее типу считанных данных. В случае, когда во время записи файловый указатель выходит за конец файла, размер файла автоматически увеличивается.
Все методы класса RandomAccessFile, кроме getChannel(), возбуждают исключение IOException – оно возникает при ошибке записи или ошибке доступа к данным.
В конструкторе класса требуется указать два параметра. Первый – имя файла или файловую переменную, второй – строку с модой доступа к файлу. Имеются следующие варианты:
- "r"- от read,- "только читать"
- "rw"- от read and write,- "читать и писать"
- "rws"- от read and write synchronously,- "читать и писать с поддержкой синхронизации" (см. далее раздел про потоки, Threads)
- "rwd"- от read and write to device,- "читать и писать с поддержкой синхронизации устройства" (см. далее раздел про потоки, Threads)
Например:
- java.io.RandomAccessFile rf1=new java.io.RandomAccessFile("q.txt","r");
- java.io.RandomAccessFile rf2=new java.io.RandomAccessFile(file,"rw");
Рассмотрим примеры, иллюстрирующие работу с потоками.
Пример чтения текста из файла:
File file;
javax.swing.JFileChooser fileChooser=new javax.swing.JFileChooser();
javax.swing.filechooser.FileFilter fileFilter=new SimpleFileFilter(".txt");
private void openMenuItemActionPerformed(java.awt.event.ActionEvent evt) {
fileChooser.addChoosableFileFilter(fileFilter);
if(fileChooser.showOpenDialog(null)!=fileChooser.APPROVE_OPTION){
return;//Нажали Cancel
};
file = fileChooser.getSelectedFile();
try{
InputStream fileInpStream=new FileInputStream(file);
int size=fileInpStream.available();
fileInpStream.close();
char[] buff=new char[size];
Reader fileReadStream=new FileReader(file);
int count=fileReadStream.read(buff);
jTextArea1.setText(String.copyValueOf(buff));
javax.swing.JOptionPane.showMessageDialog(null,
"Прочитано "+ count+" байт");
fileReadStream.close();
} catch(Exception e){
javax.swing.JOptionPane.showMessageDialog(null,
"Ошибка чтения из файла \n"+file.getAbsolutePath());
}
}Переменной fileInpStream, которая будет использована для работы потока FileInputStream, мы задаем тип InputStream. Это очень характерный прием при работе с потоками, позволяющий при необходимости заменять в дальнейшем входной поток с FileInputStream на любой другой без изменения последующего кода. После выбора имени текстового файла с помощью файлового диалога мы создаем файловый поток:
fileInpStream=new FileInputStream(file);
Функция fileInpStream.available() возвращает число байт, которые можно считать из файла. После ее использования поток fileInpStream нам больше не нужен, и мы его закрываем. Поток FileReader не поддерживает метод available(), поэтому нам пришлось использовать поток типа FileInputStream.
Массив buff используется в качестве буфера, куда мы считываем весь файл.
Если требуется читать файлы большого размера, используют буфер фиксированной длины и в цикле считывают данные из файла блоками, равными длине буфера, до тех пор, пока число считанных байт не окажется меньше размера буфера. Это означает, что мы дошли до конца файла. В таком случае выполнение цикла следует прекратить. При такой организации программы нет необходимости вызывать метод available() и использовать поток типа FileInputStream.
В операторе
Reader fileReadStream=new FileReader(file);
используется тип Reader, а не FileReader, по той же причине, что до этого мы использовали InputStream, а не FileInputStream.
Построчное чтение из файла осуществляется аналогично, но содержимое блока try следует заменить на следующий код:
FileReader filReadStream=new FileReader(file);
BufferedReader bufferedIn=new BufferedReader(filReadStream);
String s="",tmpS="";
while((tmpS=bufferedIn.readLine())!=null)
s+=tmpS+"\n";
jTextArea1.setText(s);
bufferedIn.close();Пример записи текста в файл очень похож на пример чтения, но гораздо проще, так как не требуется вводить промежуточные буферы и потоки:
private void saveAsMenuItemActionPerformed(java.awt.event.ActionEvent evt) {
fileChooser.addChoosableFileFilter(fileFilter);
if(fileChooser.showSaveDialog(null)!=fileChooser.APPROVE_OPTION){
return;//Нажали Cancel
};
file = fileChooser.getSelectedFile();
try{
Writer filWriteStream=new FileWriter(file);
filWriteStream.write(jTextArea1.getText() );
filWriteStream.close();
} catch(Exception e){
javax.swing.JOptionPane.showMessageDialog(null,
"Ошибка записи в файл \n"+file.getAbsolutePath());
}
}