
| ВКР |
Преподаватель
Вы можете этот курс.
Опубликован: 16.12.2009 | Уровень: для всех | Доступ: платный
Лекция 10:
Проблемы устойчивости эконометрических процедур
Устойчивость по отношению к объему выборки
В настоящем пункте рассматривается проблема и методы оценки близости предельных распределений статистик и распределений, соответствующих конечным объемам выборок. При каких объемах выборок уже можно пользоваться предельными распределениями? Каков точный смысл термина "можно" в предыдущей фразе? Основное внимание уделяется переходу от точных формул допредельных распределений к пределу и применению метода статистических испытаний (Монте-Карло).
Асимптотическая математическая статистика и практика анализа статистических данных. Как обычно подходят к обработке реальных данных в конкретной эконометрической задаче? Первым делом строят статистическую модель. Если хотят перенести выводы с совокупности результатов наблюдений на более широкую совокупность, например, предсказать что-либо (см. "Эконометрика прогнозирования и риска" ), то рассматривают, как правило, вероятностно-статистическую модель. Например, традиционную модель выборки, в которой результаты наблюдений - реализации независимых (в совокупности) одинаково распределенных случайных величин. Очевидно, любая модель лишь приближенно соответствует реальности. В частности, естественно ожидать, что распределения результатов наблюдений несколько отличаются друг от друга, а сами результаты связаны между собой, хотя и слабо (см. предыдущий пункт).
Итак, первый этап - переход от реальной ситуации к математической модели. Далее - неожиданность: на настоящем этапе своего развития математическая теория эконометрики и статистики зачастую не позволяет провести необходимые исследования для имеющихся объемов выборок. Более того, отдельные математики пытаются оправдать свой отрыв от практики соображениями о структуре этой теории, на первый взгляд убедительными. Неосторожная давняя фраза Б.В. Гнеденко и А.Н.Колмогорова: "Познавательная ценность теории вероятностей раскрывается только предельными теоремами" (см. классическую монографию [8], одну из наиболее ценных математических книг ХХ в.) взята на вооружение и более близкими к нам по времени авторами. Так, И.А. Ибрагимов и Р.З. Хасьминский пишут: "Решение неасимптотических задач оценивания, хотя и весьма важное само по себе, как правило, не может являться объектом достаточно общей математической теории. Более того, соответствующее решение часто зависит от конкретного типа распределения, объема выборки и т.д. Так, теория малых выборок из нормального закона будет отличаться от теории малых выборок из закона Пуассона" (см. напичканную формулами монографию [9, с.7]).
Согласно цитированным и подобным им авторам, основное содержание математической теории статистики - предельные теоремы, полученные в предположении, что объемы рассматриваемых выборок стремятся к бесконечности. Эти теоремы опираются на предельные соотношения теории вероятностей, типа Закона Больших Чисел и Центральной Предельной Теоремы. Ясно, что сами по себе подобные утверждения относятся к математике, т.е. к сфере чистой абстракции, и не могут быть непосредственно применены для анализа реальных данных. Их практическое использование, о котором "чистые" математики предпочитают не думать, опирается на важное предположение: "При данном объеме выборки достаточно точными являются асимптотические формулы."
Конечно, в качестве первого приближения представляется естественным воспользоваться асимптотическими формулами, не тратя сил на анализ их точности. Но это - лишь начало долгой цепи исследований. Как же обычно преодолевают разрыв между результатами асимптотической математической статистики и потребностями практики эконометрического и статистического анализа данных? Какие "подводные камни" подстерегают на этом пути? Обсуждению этих вопросов и посвящен настоящий пункт.
Точные формулы и асимптотика. Начнем с наиболее продвинутой в математическом плане ситуации, когда для статистики известны как предельное распределение, так и распределения при конечных объемах выборки.
Примером является двухвыборочная односторонняя статистика Н.В.Смирнова. Рассмотрим две независимые выборки объемов 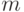 и
и  из непрерывных функций распределения
из непрерывных функций распределения 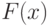 и
и 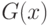 соответственно. Для проверки гипотезы однородности двух выборок (ср.
"Статистический анализ числовых величин (непараметрическая статистика)"
)
соответственно. Для проверки гипотезы однородности двух выборок (ср.
"Статистический анализ числовых величин (непараметрическая статистика)"
) 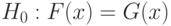 для всех действительных чисел x в 1939 г. Н.В. Смирнов предложил использовать статистику
для всех действительных чисел x в 1939 г. Н.В. Смирнов предложил использовать статистику 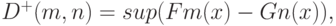 где
где  - эмпирическая функция распределения, построенная по первой выборке,
- эмпирическая функция распределения, построенная по первой выборке, 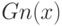 - эмпирическая функция распределения, построенная по второй выборке, супремум берется по всем действительным числам
- эмпирическая функция распределения, построенная по второй выборке, супремум берется по всем действительным числам 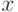 . Для обсуждения проблемы соотношения точных и предельных результатов ограничимся случаем равных объемов выборок, т.е.
. Для обсуждения проблемы соотношения точных и предельных результатов ограничимся случаем равных объемов выборок, т.е.  . Положим
. Положим 
В цитированной статье [10] Н.В. Смирнов показал, что при безграничном возрастании объема выборки вероятность  стремится к
стремится к 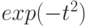 .
.
В работе [11] 1951 г. Б.В. Гнеденко и В.С. Королюк показали, что при целом 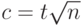 (именно при таких
(именно при таких 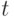 вероятность как функция t имеет скачки, поскольку статистика Смирнова
вероятность как функция t имеет скачки, поскольку статистика Смирнова 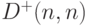 кратна
кратна 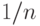 ) рассматриваемая вероятность выражается через биномиальные коэффициенты, а именно,
) рассматриваемая вероятность выражается через биномиальные коэффициенты, а именно,
 |
( 1) |
К сожалению, непосредственные расчеты по формуле (1) возможны лишь при сравнительно небольших объемах выборок, поскольку величина 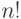 . ( -факториал) уже при
. ( -факториал) уже при 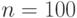 имеет более 200 цифр и не может быть без преобразований использована в вычислениях. Следовательно, наличие точной формулы для интересующей нас вероятности не снимает необходимости использования предельного распределения и изучения точности приближения с его помощью.
имеет более 200 цифр и не может быть без преобразований использована в вычислениях. Следовательно, наличие точной формулы для интересующей нас вероятности не снимает необходимости использования предельного распределения и изучения точности приближения с его помощью.
Широко известная формула Стирлинга для гамма-функции и, в частности, для факториалов позволяет преобразовать последнее выражение в асимптотическое разложение, т.е. построить бесконечный степенной ряд (по степеням ) такой что каждая следующая частичная сумма дает все более точное приближение для интересующей нас вероятности 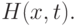 Это и было сделано в работе А.А. Боровкова 1962 г. Большое количество подобных разложений для различных статистических задач приведено в работах В.М. Калинина и О.В. Шалаевского конца 1960-х - начала 1970-х годов. (Интересно отметить, что асимптотические разложения в ряде случаев расходятся, т.е. остаточные члены имеют нетривиальную природу.)
Это и было сделано в работе А.А. Боровкова 1962 г. Большое количество подобных разложений для различных статистических задач приведено в работах В.М. Калинина и О.В. Шалаевского конца 1960-х - начала 1970-х годов. (Интересно отметить, что асимптотические разложения в ряде случаев расходятся, т.е. остаточные члены имеют нетривиальную природу.)
Затем в работах конца семидесятых годов была сделана попытка теоретически оценить остаточный член второго порядка. Итоги подведены в монографии [1, § 2.2, с.37-45]. Справедливо равенство

где
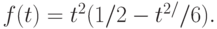
Целью последних из названных работ было получение равномерных по 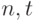 оценок остаточного члена второго порядка
оценок остаточного члена второго порядка 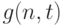 сверху и снизу в области, задаваемой условиями
сверху и снизу в области, задаваемой условиями
 |
( 2) |
где  - некоторые параметры. С помощью длинных цепочек оценок остаточных членов в формулах, получаемых при преобразовании формулы (1) к предельному виду, сформулированная выше цель была достигнута, и для различных наборов параметров получены равномерные по
- некоторые параметры. С помощью длинных цепочек оценок остаточных членов в формулах, получаемых при преобразовании формулы (1) к предельному виду, сформулированная выше цель была достигнута, и для различных наборов параметров получены равномерные по 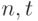 оценки (сверху и снизу) остаточного члена второго порядка в области (2). Так, например, при
оценки (сверху и снизу) остаточного члена второго порядка в области (2). Так, например, при 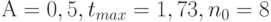 нижняя граница равна (- 0,71), а верхняя есть 2,65.
нижняя граница равна (- 0,71), а верхняя есть 2,65.
Основными недостатками такого подхода являются, во первых, зависимость оценок от параметров , задающих границы областей, во-вторых, завышение оценок, иногда в сотни раз, обусловленное желанием получить равномерные оценки по области (оценкой реальной погрешности в конкретной точке является значение следующего члена асимптотического разложения).
Поэтому при составлении рассчитанной на практическое использование методики [12] проверки однородности двух выборок с помощью статистики Смирнова было решено перейти на несколько другую методологию (назовем ее "методологией заданной точности"), которую кратко можно описать следующим образом.
- выбирается достаточно малое положительное число
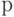 , например
, например 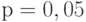 или
или 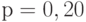 ;
; - приводятся точные значения для всех значений
 таких, что
таких, что  ;
; - если же последнее неравенство не выполнено, то предлагается пользоваться вместо предельным значением
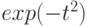 .
.
Таким образом, принятая в методике [12] методология предполагает интенсивное использование вычислительной техники. Результатами расчетов являются граничные значения объемов выборок 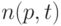 такие, что при меньших значениях объемов выборок рекомендуется пользоваться точными значениями функции распределения статистики Смирнова, а при больших - предельными. Описывается этот результат таблицей, а не формулой. Отметим, что при построении реальных таблиц не обойтись без выбора того или иного конкретного значения р, задающего объемы таблиц.
такие, что при меньших значениях объемов выборок рекомендуется пользоваться точными значениями функции распределения статистики Смирнова, а при больших - предельными. Описывается этот результат таблицей, а не формулой. Отметим, что при построении реальных таблиц не обойтись без выбора того или иного конкретного значения р, задающего объемы таблиц.
Оценки скорости сходимости. Теоретические оценки скорости сходимости в различных задачах эконометрики и прикладной математической статистики иногда формулируются в весьма абстрактном виде. Так, в 1960-1970-х годах была популярна задача оценки скорости сходимости распределения классической статистики омега-квадрат (Крамера-Мизеса-Смирнова). Для максимума модуля разности допредельной и предельной функций распределения этой статистики различные авторы доказывали, что для любого  существует константа
существует константа  такая, что упомянутый максимум не превосходит
такая, что упомянутый максимум не превосходит 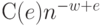 . Прогресс состоял в увеличении константы
. Прогресс состоял в увеличении константы  . Сформулированный выше результат был доказан последовательно для
. Сформулированный выше результат был доказан последовательно для 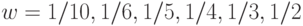 и 1 (подробнее история этих исследований рассказана в §2.3 монографии [1]).
и 1 (подробнее история этих исследований рассказана в §2.3 монографии [1]).
Конечно, все эти исследования не могли дать конкретных практических рекомендаций. Однако необходимой исходной точкой является само существование предельного распределения. Представим себе, что некто, не зная, что у распределения Коши нет математического ожидания, моделирует выборочные средние арифметические результатов наблюдений из этого распределения. Ясно, что его попытки оценить скорость сходимости выборочных средних к пределу обречены на провал.
Последовательное улучшение теоретических оценок скорости сходимости дает надежду на быструю реальную сходимость. Действительно, численные расчеты показали, что предельным распределением для статистики омега-квадрат (Крамера-Мизеса-Смирнова) можно пользоваться уже при объеме выборки, равном 4.
Использование датчиков псевдослучайных чисел. Если же предельное распределение известно, то возникает возможность изучить скорость сходимости численно методом статистических испытаний (Монте-Карло). Однако при этом обычно возникают две проблемы.
Во-первых, откуда известно, что скорость сходимости монотонна? Если при данном объеме выборки различие мало, то будет ли оно мало и при дальнейших объемах? Иногда отклонения допредельного распределения от предельного объясняются довольно сложными причинами. Так, для распределения хи-квадрат они связаны с рядом до сих пор не решенных теоретико-числовых проблем о числе целых точек в эллипсоиде растущего диаметра.
Во-вторых, с помощью датчиков псевдослучайных чисел получаем допредельные распределения с погрешностью, которая может преуменьшать различие. Поясним мысль аналогией. Растущий сигнал измеряется с погрешностями. Когда можно гарантировать, что его величина наверняка превзошла заданную границу?
Напомним, что проблема качества датчиков псевдослучайных чисел продолжает оставаться открытой (см. "Эконометрические информационные технологии" ). Для моделирования в пространствах фиксированной размерности датчики псевдослучайных чисел решают поставленные задачи. Но для рассматриваемых нами задач размерность не фиксирована - мы не знаем, при каком конкретно объеме выборки можно переходить к предельному распределению согласно "методологии заданной точности".
Нужны дальнейшие работы по изучению качества датчиков псевдослучайных чисел в задачах неопределенной размерности. Поскольку критиков датчиков обычно обвиняют в том, что они сами их не используют, отмечу, что мы применяли этот инструментарий при изучении помех, создаваемых электровозами (см. монографию [1]), при изучении статистических критериев проверки однородности двух выборок.
А нужна ли вообще асимптотика? В настоящее время развивается актуальное направление прикладной статистики, связанное с интенсивным использованием вычислительной техники для изучения свойств статистических процедур. Как уже отмечалось, математические методы в статистике обычно позволяют получать лишь асимптотические результаты, и для переноса выводов на конечные объемы выборок приходится применять вычислительные методы. В Новосибирском государственном техническом университете разработан и успешно применяется оригинальный подход, основанный на интенсивном использовании современной вычислительной техники. Основная идея такова: в качестве альтернативы асимптотическим методам математической статистики используется анализ результатов статистического моделирования (порядка 2000 испытаний) выборок конкретных объемов (200, 500, 1000). При этом анализ предельных распределений заменяется на анализ распределений соответствующих статистик при указанных объемах выборок.
К достоинствам подхода относится возможность замены теоретических исследований расчетами. Разработанная программная система дает в принципе возможность численно изучить свойства любого статистического алгоритма для любого конкретного распределения результатов наблюдений и любого конкретного объема выборки. К недостаткам рассматриваемого подхода относится зависимость от свойств датчиков псевдослучайных чисел, а также - что более важно - неизвестность предельного распределения (и даже самого факта его существования), а потому невозможность обоснованного переноса полученных выводов на объемы выборок, отличные от исследованных. Поэтому с точки зрения теории математической статистики полученные рассматриваемым способом результаты следует рассматривать как правдоподобные (а не доказательные, как в классической математической статистике).
Кроме того, они принципиально неточные. Даже в наиболее благоприятных условиях отклонение смоделированного распределения, построенного по 2000 испытаниям, от теоретического предельного распределения, по нашей оценке, может иметь порядок 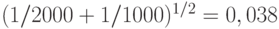 . Это означает, в частности, что процентные точки, соответствующие уровням значимости 0,05 и особенно 0,01, могут сильно отличаться от соответствующих процентных точек предельных распределений. Очевидно, следующий этап работ - изучение точности полученных в рассматриваемом подходе выводов, прежде всего приближений и процентных точек.
. Это означает, в частности, что процентные точки, соответствующие уровням значимости 0,05 и особенно 0,01, могут сильно отличаться от соответствующих процентных точек предельных распределений. Очевидно, следующий этап работ - изучение точности полученных в рассматриваемом подходе выводов, прежде всего приближений и процентных точек.
Однако сразу все не сделаешь. Поэтому новосибирцы совершенно правы, развивая новые компьютерные подходы к давним задачам эконометрики и прикладной математической статистики. В частности, весьма полезными и интересными являются результаты, касающиеся непараметрических критериев согласия. Весьма интересным и полезным представляется также метод построения оптимального группирования, в частности, при использовании критериев типа хи-квадрат. Важен результат о неробастности (неустойчивости) оценок максимального правдоподобия по негруппированным данным. Надо поддержать идею использования одновременно двух оценок по группированным данным с использованием как оптимального, так и равновероятного группирования. Этот подход сибиряков соответствует современным идеям в области устойчивости (робастности) статистических выводов.
Однако стоит сделать два замечания. В работе [14] сравниваются два плана контроля надежности технических изделий. Оказывается, что при объемах выборки, меньших 150, лучше первый план, а при объемах, больших 150 - второй. Значит, если бы по новосибирскому методу сравнивались эти планы при достаточно большом объеме выборки , то лучшим был бы признан первый план, что неверно - наступит момент (объем выборки), когда лучшим станет второй план.
Другая относящаяся к делу ассоциация - из весьма содержательной монографии о прикладной математике [15]. Будем суммировать бесконечный ряд с членами 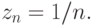 Поскольку члены его убывают, то обычно используемые алгоритмы остановят вычисления на каком-то шагу. А сумма-то - бесконечна!
Поскольку члены его убывают, то обычно используемые алгоритмы остановят вычисления на каком-то шагу. А сумма-то - бесконечна!
Кажется, что компьютер дал универсальную отмычку ко всем проблемам вообще и в области эконометрики в частности. Но это только кажется.
Итак, в Новосибирском государственном техническом университете предложен интересный эконометрический инструментарий и проделана полезная работа. Однако этот подход никоим образом не является панацеей.