Инспектор

Вы можете этот курс.
Опубликован: 06.03.2006 | Уровень: для всех | Доступ: платный
Лекция 4:
Документооборот на современном предприятии
Технологии перевода бумажных документов в электронные
В отличие от бумажных документов, электронные могут обрабатываться более эффективно (тиражироваться, рассылаться, храниться и т.п.). В настоящее время активно развиваются технологии перевода бумажных документов в электронную форму с целью реализации электронного документооборота. Остановимся подробнее на применяемых технологиях и используемой терминологии.
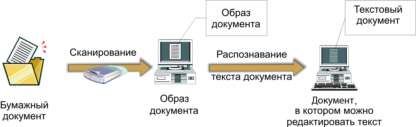
На первом этапе перевода документа в электронную форму производится его сканирование и создается электронная копия документа в виде изображения. Изображение, полученное в результате сканирования, также называют образом документа. Сканирование является начальным этапом любой системы автоматизированного ввода документов.
В процессе сканирования может выполняться программная обработка изображения, а также производится визуальный контроль качества (рис. 3.6).
Если речь идет о промышленном вводе документов, то сканеры обычно предоставляют ряд дополнительных функций, например возможность подачи разноформатных документов.
Обычно процесс сканирования - это промежуточная стадия получения электронного документа. Очевидно, что с электронным изображением документа гораздо удобнее работать, чем с бумажным (его можно копировать, отправлять по сети и т.д.).
Однако в большинстве случаев само по себе изображение (образ документа) дает мало преимуществ. Для того чтобы можно было редактировать документ, осуществлять поиск по нему или использовать его фрагменты при подготовке новых документов и т.д., необходимо перевести полученный образ в текстовый документ, понятный офисным программам. Поэтому следующая задача заключается в распознавании отсканированных документов.
Для этого необходим специальный инструмент, способный перевести изображение в текстовый редактируемый электронный документ. Такие инструменты существуют, их общее название - программы оптического распознавания символов (optical character recognition, OCR). C помощью OCR-программы компьютер сможет "прочесть" на отсканированной странице текст, отделив его от иллюстраций и прочих элементов оформления, найти таблицы и "разобраться" в их содержимом. А затем скомпоновать все это заново, воссоздав внешний вид страницы.
С точки зрения перевода документов в электронный вид (ввода документов в компьютер) их условно делят на формализованные, неформализованные и специальные (рис. 3.7).

Формализованные документы - это документы, в которых заранее определена форма: расположение обязательных полей, в которые заносятся данные. Например, бланки, накладные, анкеты, картотеки и т.д. Неформализованные документы - это документы произвольной формы: договоры, письма и т.д. К специализированным относятся такие документы как, например, карты и отпечатки пальцев.
Перевод каждого из перечисленных видов документов имеет свою специфику. Если вводятся фотографии, то достаточно электронного изображения, если документ содержит текст, его необходимо распознать, если это форматированный текст с рисунками, то нужно не только распознать текст, но и восстановить формат документа, а если это анкета, то, скорее всего, сам документ вообще не нужен, важна только содержащаяся в нем информация. Например, при обработке листов для голосования обычно не требуется изображения самого документа, достаточно информации о том, за кого отдан голос.
Ввод формализованных документов
Чтобы пояснить, какие задачи возникают при вводе формализованных документов, рассмотрим конкретный пример.
Предположим, в офисе отеля проводится анкетирование проживающих для оценки уровня обслуживания на разных этажах. Каждому жителю отеля в его номере оставляется анкета, которую он должен заполнить (рис. 3.8).

Если за месяц накапливается несколько тысяч таких анкет, то их обработка представляет собой непростую задачу. Очевидно, что получение образов (электронных изображений) этих анкет хоть и облегчает задачу их хранения, однако не позволяет использовать компьютер для обработки информации.
Чаще всего задача ввода форм (в данном случае анкеты) состоит в превращении образа документа в строчку базы данных, содержащую соответствующую информацию. Когда все анкеты будут введены в базу данных, можно будет их обработать и, например, выяснить, на каком этаже обслуживание ведется лучше.
При заполнении анкеты требуется ответить на вопросы и внести информацию в определенные служебные поля, а задача программы при вводе форм - определять эти специальные поля, распознавать информацию в них и ввести ее в базу данных. При этом особенностью ввода форм в компьютер является необходимость распознавания текстов, заполненных от руки.
Обычно в том случае, если форма должна распознаваться компьютером, заполняющего просят ввести текст раздельными буквами, и такой текст называют рукопечатным. Технологии распознавания рукопечатных символов обозначаются термином ICR (Intelligent Character Recognition). Распознавание рукопечатных символов представляет собой более сложную задачу по сравнению с распознаванием печатных, поскольку требуется распознать символ, вписанный в форму от руки с учетом возможных его отклонений, обусловленных индивидуальными особенностями почерка.

Задачи распознавания при вводе форм не обязательно связаны с распознаванием текста. При вводе форм может потребоваться распознавание различных меток и знаков, для которого тоже существует свой термин: OMR (Optical Mark Recognition). Например, в бюллетенях для голосования голосующего просят поставить крестик (или другой знак) напротив фамилии кандидата, и задача компьютера - распознать, есть в определенном поле какой-нибудь знак или нет.