Опубликован: 17.10.2005 | Уровень: специалист | Доступ: платный
Лекция 17:
Типизация
Статическая и динамическая типизация
Хотя возможны и промежуточные варианты, здесь представлены два главных подхода:
- Динамическая типизация: ждать момента выполнения каждого вызова и тогда принимать решение.
- Статическая типизация: с учетом набора правил определить по исходному тексту, возможны ли нарушения типов при выполнении. Система выполняется, если правила гарантируют отсутствие ошибок.
Эти термины легко объяснимы: при динамической типизации проверка типов происходит во время работы системы (динамически), а при статической типизации проверка выполняется над текстом статически (до выполнения).
Статическая типизация предполагает автоматическую проверку, возлагаемую, как правило, на компилятор. В итоге имеем простое определение:
Определение: статически типизированный язык
ОО-язык статически типизирован, если он поставляется с набором согласованных правил, проверяемых компилятором, соблюдение которых гарантирует, что выполнение системы не приведет к нарушению типов.
В литературе встречается термин " сильная типизация" (strong). Он соответствует ультимативной природе определения, требующей полного отсутствия нарушения типов. Возможны и слабые (weak) формы статической типизации, при которых правила устраняют определенные нарушения, не ликвидируя их целиком. В этом смысле некоторые ОО-языки являются статически слабо типизированными. Мы будем бороться за наиболее сильную типизацию.
В динамически типизированных языках, известных как нетипизированные, отсутствуют объявления типов, а к сущностям в период выполнения могут присоединяться любые значения. Статическая проверка типов в них невозможна.
Правила типизации
Наша ОО-нотация является статически типизированной. Ее правила типов были введены в предыдущих лекциях и сводятся к трем простым требованиям.
- При объявлении каждой сущности или функции должен задаваться ее тип, например, acc: ACCOUNT. Каждая подпрограмма имеет 0 или более формальных аргументов, тип которых должен быть задан, например: put (x: G; i: INTEGER).
- В любом присваивании x := y и при любом вызове подпрограммы, в котором y - это фактический аргумент для формального аргумента x, тип источника y должен быть совместим с типом цели x. Определение совместимости основано на наследовании: B совместим с A, если является его потомком, - дополненное правилами для родовых параметров (см. "Введение в наследование" ).
- Вызов x.f (arg) требует, чтобы f был компонентом базового класса для типа цели x, и f должен быть экспортирован классу, в котором появляется вызов (см. 14.3).
Реализм
Хотя определение статически типизированного языка дано совершенно точно, его недостаточно, - необходимы неформальные критерии при создании правил типизации. Рассмотрим два крайних случая.
- Совершенно корректный язык, в котором каждая синтаксически правильная система корректна и в отношении типов. Правила описания типов не нужны. Такие языки существуют (представьте себе польскую запись выражения со сложением и вычитанием целых чисел). К сожалению, ни один реальный универсальный язык не отвечает этому критерию.
- Совершенно некорректный язык, который легко создать, взяв любой существующий язык и добавив правило типизации, делающее любую систему некорректной. По определению, этот язык типизирован: так как нет систем, соответствующих правилам, то ни одна система не вызовет нарушения типов.
Можно сказать, что языки первого типа пригодны, но бесполезны, вторые, возможно, полезны, но не пригодны.
На практике необходима система типов, пригодная и полезная одновременно: достаточно мощная для реализации потребностей вычислений и достаточно удобная, не заставляющая нас идти на усложнения для удовлетворения правил типизации.
Будем говорить, что язык реалистичен, если он пригоден к применению и полезен на практике. В отличие от определения статической типизации, дающего безапелляционный ответ на вопрос: " Типизирован ли язык X статически?", определение реализма отчасти субъективно.
В этой лекции мы убедимся, что предлагаемая нами нотация реалистична.
Пессимизм
Статическая типизация приводит по своей природе к "пессимистической" политике. Попытка дать гарантию, что все вычисления не приводят к отказам, отвергает вычисления, которые могли бы закончиться без ошибок.
Рассмотрим обычный, необъектный, Pascal-подобный язык с различными типами REAL и INTEGER. При описании n: INTEGER; r: Real оператор n := r будет отклонен, как нарушающий правила. Так, компилятор отвергнет все нижеследующие операторы:
n := 0.0 [A] n := 1.0 [B] n := -3.67 [C] n := 3.67 - 3.67 [D]
Если мы разрешим их выполнение, то увидим, что [A] будет работать всегда, так как любая система счисления имеет точное представление вещественного числа 0,0, недвусмысленно переводимое в 0 целых. [B] почти наверняка также будет работать. Результат действия [C] не очевиден (хотим ли мы получить итог округлением или отбрасыванием дробной части?). [D] справится со своей задачей, как и оператор:
if n ^ 2 < 0 then n := 3.67 end [E]
куда входит недостижимое присваивание (n ^ 2 - это квадрат числа n). После замены n ^ 2 на n правильный результат даст только ряд запусков. Присваивание n большого вещественного значения, не представимого целым, приведет к отказу.
В типизированных языках все эти примеры (работающие, неработающие, иногда работающие) безжалостно трактуются как нарушения правил описания типов и отклоняются любым компилятором.
Вопрос не в том, будем ли мы пессимистами, а в том, насколько пессимистичными мы можем позволить себе быть. Вернемся к требованию реализма: если правила типов настолько пессимистичны, что препятствуют простоте записи вычислений, мы их отвергнем. Но если достижение безопасности типов достигается небольшой потерей выразительной силы, мы примем их. Например, в среде разработки, предоставляющей функции округления и выделения целой части - round и truncate, оператор n := r считается некорректным справедливо, поскольку заставляет вас явно записать преобразование вещественного числа в целое, вместо использования двусмысленных преобразований по умолчанию.
Статическая типизация: как и почему
Хотя преимущества статической типизации очевидны, неплохо поговорить о них еще раз.
Преимущества
Причины применения статической типизации в объектной технологии мы перечислили в начале лекции. Это надежность, простота понимания и эффективность.
Надежность обусловлена обнаружением ошибок, которые иначе могли проявить себя лишь во время работы, и только в некоторых случаях. Первое из правил, заставляющее объявлять сущности, как, впрочем, и функции, вносит в программный текст избыточность, что позволяет компилятору, используя два других правила, обнаруживать несоответствия между задуманным и реальным применением сущностей, компонентов и выражений.
Раннее выявление ошибок важно еще и потому, что чем дольше мы будем откладывать их поиск, тем сильнее вырастут издержки на исправление. Это свойство, интуитивно понятное всем программистам-профессионалам, количественно подтверждают широко известные работы Бема (Boehm). Зависимость издержек на исправление от времени отыскания ошибок приведена на графике, построенном по данным ряда больших промышленных проектов и проведенных экспериментов с небольшим управляемым проектом:
![Сравнительные издержки на исправление ошибок ([Boehm 1981], публикуется с разрешения)](/EDI/09_01_19_1/1546985980-8393/tutorial/154/objects/17/files/17_1.gif)
Читабельность или Простота понимания (readability) имеет свои преимущества. Во всех примерах этой книги появление типа у сущности дает читателю информацию о ее назначении. Читабельность крайне важна на этапе сопровождения.
| Исключив читабельность из круга приоритетов, можно было бы получить другие преимущества, не вводя явных объявлений. В самом деле, возможна неявная форма типизации, когда компилятор, не требуя явного указания типа, пытается автоматически определить его из контекста применения сущности. Эта стратегия известна как выведение типов (type inference). Но в программной инженерии явные объявления типов это помощь, а не наказание, - тип должен быть ясен не только машине, но и читающему текст человеку. |
Наконец, эффективность может определять успех или отказ от объектной технологии на практике. В отсутствие статической типизации на выполнение x.f (arg) может уйти сколько угодно времени. Причина этого в том, что на этапе выполнения, не найдя f в базовом классе цели x, поиск будет продолжен у ее потомков, а это верная дорога к неэффективности. Снять остроту проблемы можно, улучшив поиск компонента по иерархии. Авторы языка Self провели большую работу, стремясь генерировать лучший код для языка с динамической типизацией. Но именно статическая типизация позволила такому ОО-продукту приблизиться или сравняться по эффективности с традиционным ПО.
Ключом к статической типизации является уже высказанная идея о том, что компилятор, генерирующий код для конструкции x.f (arg), знает тип x. Из-за полиморфизма нет возможности однозначно определить подходящую версию компонента f. Но объявление сужает множество возможных типов, позволяя компилятору построить таблицу, обеспечивающую доступ к правильному f с минимальными издержками, - с ограниченной константой сложностью доступа. Дополнительно выполняемые оптимизации статического связывания (static binding) и подстановки (inlining) - также облегчаются благодаря статической типизации, полностью устраняя издержки в тех случаях, когда они применимы.
Аргументы в пользу динамической типизации
Несмотря на все это, динамическая типизация не теряет своих приверженцев, в частности, среди Smalltalk-программистов. Их аргументы основаны прежде всего на реализме, речь о котором шла выше. Они уверены, что статическая типизация чересчур ограничивает их, не давая им свободно выражать свои творческие идеи, называя иногда ее "поясом целомудрия".
С такой аргументацией можно согласиться, но лишь для статически типизированных языков, не поддерживающих ряд возможностей. Стоит отметить, что все концепции, связанные с понятием типа и введенные в предыдущих лекциях, необходимы - отказ от любой из них чреват серьезными ограничениями, а их введение, напротив, придает нашим действиям гибкость, а нам самим дает возможность в полной мере насладиться практичностью статической типизации.
Типизация: слагаемые успеха
Каковы механизмы реалистичной статической типизации? Все они введены в предыдущих лекциях, а потому нам остается лишь кратко о них напомнить. Их совместное перечисление показывает согласованность и мощь их объединения.
Наша система типов полностью основана на понятии класса. Классами являются даже такие базовые типы, как INTEGER, а стало быть, нам не нужны особые правила описания предопределенных типов. (В этом наша нотация отличается от "гибридных" языков наподобие Object Pascal, Java и C++, где система типов старых языков сочетается с объектной технологией, основанной на классах.)
Развернутые типы дают нам больше гибкости, допуская типы, чьи значения обозначают объекты, наряду с типами, чьи значения обозначают ссылки.
Решающее слово в создании гибкой системы типов принадлежит наследованию и связанному с ним понятию совместимости. Тем самым преодолевается главное ограничение классических типизированных языков, к примеру, Pascal и Ada, в которых оператор x := y требует, чтобы тип x и y был одинаковым. Это правило слишком строго: оно запрещает использовать сущности, которые могут обозначать объекты взаимосвязанных типов (SAVINGS_ACCOUNT и CHECKING_ACCOUNT). При наследовании мы требуем лишь совместимости типа y с типом x, например, x имеет тип ACCOUNT, y - SAVINGS_ACCOUNT, и второй класс - наследник первого.
На практике статически типизированный язык нуждается в поддержке множественного наследования. Известны принципиальные обвинения статической типизации в том, что она не дает возможность по-разному интерпретировать объекты. Так, объект DOCUMENT (документ) может передаваться по сети, а потому нуждается в наличия компонентов, связанных с типом MESSAGE (сообщение). Но эта критика верна только для языков, ограниченных единичным наследованием.

Универсальность необходима, например, для описания гибких, но безопасных контейнерных структур данных (например class LIST [G] ...). Не будь этого механизма, статическая типизация потребовала бы объявления разных классов для списков, отличающихся типом элементов.
В ряде случаев универсальность требуется ограничить, что позволяет использовать операции, применимые лишь к сущностям родового типа. Если родовой класс SORTABLE_LIST поддерживает сортировку, он требует от сущностей типа G, где G - родовой параметр, наличия операции сравнения. Это достигается связыванием с G класса, задающего родовое ограничение, - COMPARABLE:
class SORTABLE_LIST [G -> COMPARABLE] ...
Любой фактический родовой параметр SORTABLE_LIST должен быть потомком класса COMPARABLE, имеющего необходимый компонент.
Еще один обязательный механизм - попытка присваивания - организует доступ к тем объектам, типом которых ПО не управляет. Если y - это объект базы данных или объект, полученный через сеть, то оператор x ?= y присвоит x значение y, если y имеет совместимый тип, или, если это не так, даст x значение Void.
Утверждения, связанные, как часть идеи Проектирования по Контракту, с классами и их компонентами в форме предусловий, постусловий и инвариантов класса, дают возможность описывать семантические ограничения, которые не охватываются спецификацией типа. В таких языках, как Pascal и Ada, есть типы-диапазоны, способные ограничить значения сущности, к примеру, интервалом от 10 до 20, однако, применяя их, вам не удастся добиться того, чтобы значение i являлось отрицательным, всегда вдвое превышая j. На помощь приходят инварианты классов, призванные точно отражать вводимые ограничения, какими бы сложными они не были.
Закрепленные объявления нужны для того, чтобы на практике избегать лавинного дублирования кода. Объявляя y: like x, вы получаете гарантию того, что y будет меняться вслед за любыми повторными объявлениями типа x у потомка. В отсутствие этого механизма разработчики беспрестанно занимались бы повторными объявлениями, стремясь сохранить соответствие различных типов.
Закрепленные объявления - это особый случай последнего требуемого нам языкового механизма - ковариантности, подробное обсуждение которого нам предстоит позже.
При разработке программных систем на деле необходимо еще одно свойство, присущее самой среде разработки - быстрая, возрастающая (fast incremental) перекомпиляция. Когда вы пишите или модифицируете систему, хотелось бы как можно скорее увидеть эффект изменений. При статической типизации вы должны дать компилятору время на перепроверку типов. Традиционные подпрограммы компиляции требуют повторной трансляции всей системы (и ее сборки), и этот процесс может быть мучительно долгим, особенно с переходом к системам большого масштаба. Это явление стало аргументом в пользу интерпретирующих систем, таких как ранние среды Lisp или Smalltalk, запускавшие систему практически без обработки, не выполняя проверку типов. Сейчас этот аргумент позабыт. Хороший современный компилятор определяет, как изменился код с момента последней компиляции, и обрабатывает лишь найденные изменения.
"Типизирована ли кроха"?
Наша цель - строгая статическая типизация. Именно поэтому мы и должны избегать любых лазеек в нашей "игре по правилам", по крайней мере, точно их идентифицировать, если они существуют.
Самой распространенной лазейкой в статически типизированных языках является наличие преобразований, меняющих тип сущности. В C и производных от него языках их называют "приведением типа" или кастингом (cast). Запись (OTHER_TYPE) x указывает на то, что значение x воспринимается компилятором, как имеющее тип OTHER_TYPE, при соблюдении некоторых ограничений на возможные типы.
Подобные механизмы обходят ограничения проверки типов. Приведение широко распространено при программировании на языке C, включая диалект ANSI C. Даже в языке C++ приведение типов, хотя и не столь частое, остается привычным и, возможно, необходимым делом.
Придерживаться правил статической типизации не так просто, если в любой момент их можно обойти путем приведения.
Далее будем полагать, что система типов является строгой и не допускает приведения типа.
| Возможно, вы заметили, что попытка присваивания - неотъемлемый компонент реалистичной системы типов - напоминает приведение. Однако есть существенное отличие: попытка присваивания выполняет проверку, действительно ли текущий тип соответствует заданному типу, - это безопасно, а иногда и необходимо. |
Типизация и связывание
Хотя как читатель этой книги вы наверняка отличите статическую типизацию от статического связывания, есть люди, которым подобное не под силу. Отчасти это может быть связано с влиянием языка Smalltalk, отстаивающего динамический подход к обеим задачам и способного сформировать неверное представление, будто они имеют одинаковое решение. (Мы же в своей книге утверждаем, что для создания надежных и гибких программ желательно объединить статическую типизацию и динамическое связывание.)
Как типизация, так и связывание имеют дело с семантикой Базисной Конструкции x.f (arg), но отвечают на два разных вопроса:
Типизация и связывание
- Вопрос о типизации: когда мы должны точно знать, что во время выполнения появится операция, соответствующая f, применимая к объекту, присоединенному к сущности x (с параметром arg)?
- Вопрос о связывании: когда мы должны знать, какую операцию инициирует данный вызов?
Типизация отвечает на вопрос о наличии как минимум одной операции, связывание отвечает за выбор нужной.
В рамках объектного подхода:
- проблема, возникающая при типизации, связана с полиморфизмом: поскольку x во время выполнения может обозначать объекты нескольких различных типов, мы должны быть уверены, что операция, представляющая f, доступна в каждом из этих случаев;
- проблема связывания вызвана повторными объявлениями: так как класс может менять наследуемые компоненты, то могут найтись две или более операции, претендующие на то, чтобы представлять f в данном вызове.
Обе задачи могут быть решены как динамически, так и статически. В существующих языках представлены все четыре варианта решения.
- Ряд необъектных языков, скажем, Pascal и Ada, реализуют как статическую типизацию, так и статическое связывание. Каждая сущность представляет объекты только одного типа, заданного статически. Тем самым обеспечивается надежность решения, платой за которую является его гибкость.
- Smalltalk и другие ОО-языки содержат средства динамического связывания и динамической типизации. При этом предпочтение отдается гибкости в ущерб надежности языка.
- Отдельные необъектные языки поддерживают динамическую типизацию и статическое связывание. Среди них - языки ассемблера и ряд языков сценариев (scripting languages).
- Идеи статической типизации и динамического связывания воплощены в нотации, предложенной в этой книге.
Отметим своеобразие языка C++, поддерживающего статическую типизацию, хотя и не строгую ввиду наличия приведения типов, статическое связывание (по умолчанию), динамическое связывание при явном указании виртуальных (virtual) объявлений.
Причина выбора статической типизации и динамического связывания очевидна. Первый вопрос: "Когда мы будем знать о существовании компонентов?" - предполагает статический ответ: " Чем раньше, тем лучше ", что означает: во время компиляции. Второй вопрос: "Какой из компонентов использовать?" предполагает динамический ответ: " тот, который нужен ", - соответствующий динамическому типу объекта, определяемому во время выполнения. Это единственно приемлемое решение, если статическое и динамическое связывание дает различные результаты.
Следующий пример иерархии наследования поможет прояснить эти понятия:
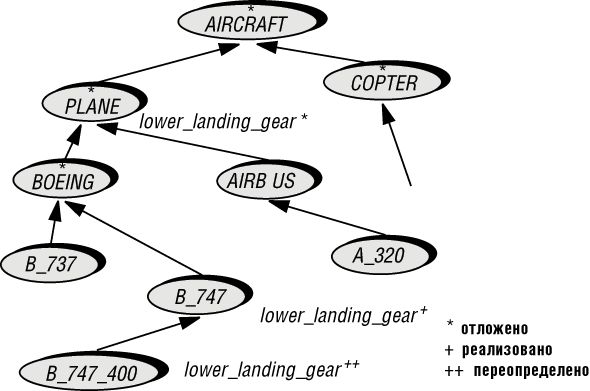
Рассмотрим вызов:
my_aircraft.lower_landing_gear
Вопрос о типизации: когда убедиться, что здесь будет компонент lower_landing_gear ("выпустить шасси"), применимый к объекту (для COPTER его не будет вовсе) Вопрос о связывании: какую из нескольких возможных версий выбрать.
Статическое связывание означало бы, что мы игнорируем тип присоединяемого объекта и полагаемся на объявление сущности. В итоге, имея дело с Boeing 747-400, мы вызвали бы версию, разработанную для обычных лайнеров серии 747, а не для их модификации 747-400. Динамическое связывание применяет операцию, требуемую объектом, и это правильный подход.
При статической типизации компилятор не отклонит вызов, если можно гарантировать, что при выполнении программы к сущности my_aircraft будет присоединен объект, поставляемый с компонентом, соответствующим lower_landing_gear. Базисная техника получения гарантий проста: при обязательном объявлении my_aircraft требуется, чтобы базовый класс его типа включал такой компонент. Поэтому my_aircraft не может быть объявлен как AIRCRAFT, так как последний не имеет lower_landing_gear на этом уровне; вертолеты, по крайней мере в нашем примере, выпускать шасси не умеют. Если же мы объявим сущность как PLANE, - класс, содержащий требуемый компонент, - все будет в порядке.
Динамическая типизация в стиле Smalltalk требует дождаться вызова, и в момент его выполнения проверить наличие нужного компонента. Такое поведение возможно для прототипов и экспериментальных разработок, но недопустимо для промышленных систем - в момент полета поздно спрашивать, есть ли у вас шасси.