Инспектор

Вы можете этот курс.
Алтайский государственный университет
Опубликован: 12.07.2010 | Доступ: платный | Студентов: 88 / 0 | Оценка: 4.02 / 3.93 | Длительность: 16:32:00
ISBN: 978-5-9963-0349-6
Тема: Аппаратное обеспечение
Специальности: Разработчик аппаратуры
Лекция 10:
Мультипроцессор Cell
< Лекция 9 || Лекция 10 || Лекция 11 >
Аннотация: В лекции описывается один из самых известных мультиядерных процессоров — мультипроцессор Cell. Основные области применения процессора на сегодняшний день — мультимедийные центры, игровые консоли.
Ключевые слова: cell, процессор, broadband, engine, architecture, архитектура, power, EIB, байт, пропускная способность, процессорное ядро, SPU, память, модуль, интерфейс ввода, интерфейс, mic, SMT, кэш данных, кэш, мультипроцессор, ядро, разделы, исключение, ресурс, производительность, операции, фиксированная запятая, команда, подмножество, множества, контроль, Instruction, execution unit, vector, scalar unit, векторные, буфер, таблица, бит, поток, арифметические команды, очередь, hit, miss, cache, SIMD, приложение, DMA, обмен данными, выборка, контроллер, memory, flow control, MFC, энергопотребление, когерентность, таблица страниц, операционная система, общая память, scattered, gathering, локальная память, иерархия памяти, Дополнение, хранение данных, латентность, kernel, поддержка, компонент, эффективная реализация, ячейка, SRAM, порт, файл, слот, компилятор, очередь запросов, PLL, поток инструкций, доступ, процессорный элемент, управляющие
Общая структура процессора Cell
Cell представляет собой процессор с архитектурой CBEA (CBEA (Cell Broadband Engine Architecture) — архитектура, расширяющая 64-битную архитектуру), построенный на основе 64-битной архитектуры Power, которая направлена на распределенную обработку данных и выполнение приложений, предназначенных для обработки больших объемов мультимедиа-данных [57-58-59].
Процессор состоит из набора модулей, объединенных при помощи высокоскоростной шины (EIB), которая представляет собой две пары колец (96 байт за такт), работающих на половине частоты процессора. Пропускная способность канала ввода данных — 35 Гб/с, канала вывода данных — 40 Гб/с, объединенная пропускная способность канала обмена данными с общей памятью — 25,6 Гб/с.

В состав процессора входит 8 одинаковых процессорных модулей (SPE), содержащих процессорное ядро (SPU), локальную память модуля (LS), один процессорный модуль (PPE), содержащий 64-битный процессор, кэши первого и второго уровней, два реконфигурируемых некогерентных интерфейса ввода-вывода (BIC), интерфейс памяти (MIC) ( рис. 10.1) [57].
Структура процессорного элемента Power (PPE)
Процессорный элемент Power (PPE) имеет 64-разрядную архитектуру, с упорядоченной выдачей двух инструкций одновременно (SMT), кэш данных и кэш инструкций первого уровня объемом 32 Кб, объединенный кэш второго уровня объемом 512 Кб.
Процессор обеспечивает два одновременных потока выполнения и может рассматриваться как двухпроцессорный мультипроцессор с общим потоком данных. Ядро чередует команды от двух вычислительных потоков, выполняющихся одновременно. Это позволяет программному обеспечению воспринимать его как два независимых процессора. Продублированы все видимые состояния, в том числе видимые регистры и регистры специального назначения (за исключением регистров, имеющих дело с ресурсами на уровне системы, такими как логические разделы, память и управление потоками). Такое решение позволяет оптимизировать применение слотов выдачи команд, сохранить максимальную эффективность процессора и уменьшить глубину конвейера. Невидимые для программиста ресурсы (типа кэшей и очередей) обычно используются обоими потоками совместно. Исключение составляют те случаи, когда ресурс невелик или может существенно повысить производительность многопоточных приложений.
Простые арифметические операции выполняются и отправляют далее свои результаты за два такта. Задействован режим отложенного выполнения на конвейере операций с фиксированной запятой, благодаря чему команды загрузки также завершаются и отправляют свои результаты за два такта. Команда двойной точности с плавающей запятой выполняется за десять тактов.
PPE поддерживает обычную иерархию кэш-памяти; имеются кэши первого уровня для команд и данных емкостью по 32 Кбайт и кэш-память второго уровня емкостью 512 Кбайт. Кэш второго уровня и кэши преобразования адресов используют таблицы управления заменой, чтобы разрешить программе направлять данные из определенных диапазонов адресов в конкретное подмножество кэша. Такой механизм позволяет блокировать данные в кэше, если размер диапазона адресов равен размеру множества. Он может служить и для предотвращения перезаписи данных в кэше: данные, применяемые только один раз, направляются в определенное множество кэша. Все это повышает эффективность процессора и усиливает контроль над процессором, осуществляемый в масштабе реального времени.
Процессорный блок состоит из 3 блоков: IU (Instruction Unit); XU (eXecution Unit); VSU (Vector Scalar Unit) ( рис. 10.2). Узел команд IU (Instruction Unit) отвечает за выборку, дешифровку, выдачу и завершение команды, а также за выполнение команд перехода. Узел операций с фиксированной запятой XU (Fixed-Point eXecution Unit) выполняет все команды с фиксированной запятой и команды загрузки/сохранения. Узел векторно-скалярных команд VSU (Vector Scalar Unit) отвечает за векторные команды и команды с плавающей запятой.
Узел команд IU за один такт выбирает из каждого потока четыре команды в буфер команд и отправляет команды из этого буфера по назначению. После дешифровки и проверки зависимостей команды выдаются на узел выполнения по две за такт. Для прогнозирования результата команды перехода служит таблица истории переходов 4 Кбит х 2 бит с шестью битами глобальной истории на поток. Узел IU может выдавать до двух команд за такт.
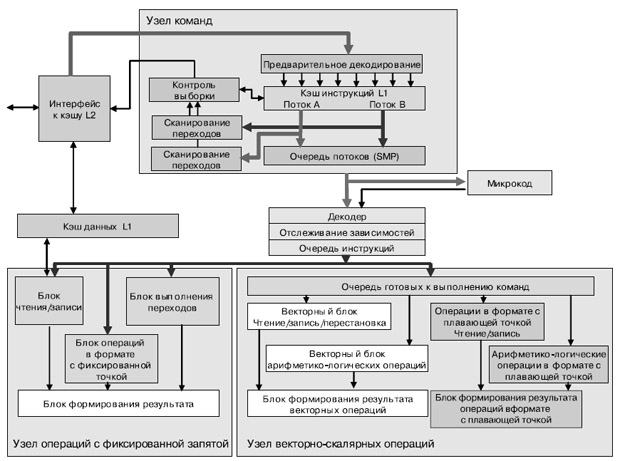
При такой "сдвоенной" выдаче возможны любые комбинации, кроме двух команд к одному и тому же узлу, а также следующих исключений. Простая векторная, комплексная векторная, векторная с плавающей запятой и скалярная с плавающей запятой арифметические команды не могут быть сдвоены с командой того же типа (например, не допускается выдача простой векторной команды в одном такте с комплексной векторной). Однако эти команды могут быть сдвоены с любой формой команды загрузки/сохранения, перехода с фиксированной запятой или перестановки элементов вектора. Очередь готовых к выдаче команд в узле VSU отделяет конвейеры векторных команд и команд с плавающей запятой от остальных конвейеров. Это позволяет выдавать такие команды вне очереди других команд.
Узел XU состоит из двух файлов регистров общего назначения 32x64 бит (по одному на поток), блока выполнения команд с фиксированной запятой и блока загрузки/сохранения. В последний входят кэш данных первого уровня, кэш преобразования адресов, 8-элементная очередь кэш-промахов и 16-элементная очередь хранения. Он поддерживает неблоки-руемый кэш данных первого уровня, который позволяет процессору обращаться к другой области кэш-памяти даже в процессе замены блока, вызвавшего кэш-промах (hit under miss cache).
Узел VSU состоит из двух файлов регистров 32x64 бит (по одному на поток) и конвейера двойной точности с десятью стадиями. Узел работает со 128-разрядным потоком данных [57]. Он имеет четыре узла для выполнения простых и комплексных векторных операций, операций одинарной точности с плавающей запятой и операций перестановки. В нем имеются два 32-элементных 128-разрядных векторных файла регистров (по одному на поток), а все команды являются 128-разрядными SIMD-командами с изменяющейся шириной элементов (2x64, 4x32, 8x16, 16x8 и 128x1 разрядов).
Структура SPE (Synergistic Processor Elements) — "синергичного" процессорного элемента
SPE представляет собой отдельный процессор, выполняющий отдельное приложение, но разделяемая когерентная память и большой набор команд для DMA позволяет организовать эффективных обмен данными между SPE.
Выборка инструкций, а также инструкции загрузки/сохранения работают только в пределах адресного пространства локальной памяти SPE. Большой объем регистрового файла служит более полному заполнению вычислительного конвейера. В каждом SPE есть контроллер потока данных памяти (Memory Flow Controller — MFC), в состав которого входит DMA-контроллер ( рис. 10.3).
SPE может настроить DMA для обмена данными с локальной памятью другого SPE, а также для обмена данными с общей памятью.
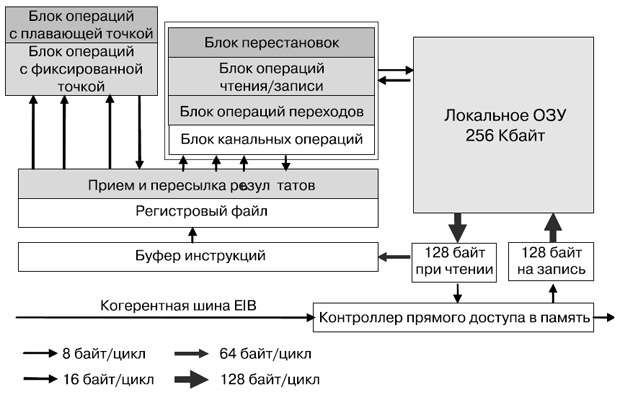
В процессорном элементе SPE реализована новая архитектура системы команд, энергопотребление и производительность которой оптимизированы для вычислительных и мультимедийных приложений. SPE работает с локальной памятью объемом 256 Кбайт, которая хранит команды и данные. Они передаются между этой и системной памятью с помощью асинхронных когерентных команд прямого доступа, которые выполняются блоком управления потоком данных, входящим в состав любого SPE.
Каждый SPE поддерживает до 16 ожидающих выполнения команд прямого доступа к памяти (DMA). В этих когерентных командах применяются такие же, как в PPE, преобразование адресов и защита, управляемые таблицами страниц и сегментов из архитектуры Power Architecture, поэтому адреса можно передавать между PPE и SPE. Вследствие этого операционная система способна использовать общую память и согласованно управлять всеми системными ресурсами.
Блок DMA может быть запрограммирован одним из трех способов: при помощи команд SPE, которые вставляют в очереди команды прямого доступа к памяти; путем подготовки в локальной памяти списка команд для пересылки содержимого разрозненных участков памяти (scatter-gather DMA) и выдачи единого списка команд DMA; с помощью вставки команд в очередь DMA другого процессора (с соответствующими привилегиями) и применения команд сохранения или записи DMA. Для удобства программирования (чтобы разрешить транзакции DMA типа "локальная память — локальная память") локальная память отображается на карту памяти процессора. Однако при кэшировании эта память не является в системе когерентной.
Появление локальной памяти вводит новый уровень иерархии памяти — в дополнение к регистрам, которые обеспечивают локальное хранение данных в большинстве процессорных архитектур. Это обеспечивает механизм борьбы с проблемой "стена памяти" (memory wall), поскольку позволяет одновременно выполнять множество транзакций с памятью без глубокой спекуляции, которая сильно снижает эффективность других процессоров. Латентность основной памяти приближается к 1 тыс. тактов, поэтому те несколько тактов, которые нужны для настройки команды DMA при обращении к ней, становятся вполне приемлемой дополнительной нагрузкой. Очевидно, что такая организация процессора удобна для обработки мультимедийных потоков. А поскольку локальная память достаточно велика для хранения большего, чем просто ядро (streaming kernel) потока, возможна поддержка самых разных моделей программирования.
Локальная память — самый крупный компонент SPE, поэтому была очень важна ее эффективная реализация. Для минимизации площади использована однопортовая ячейка SRAM. Локальная память имеет узкий (128-разрядный) и широкий (128-байтовый) порты чтения и записи. Это обеспечивает высокую производительность, хотя она и должна выступать в роли арбитра по отношению к операциям чтения, записи, выборки команд, загрузки и сохранения с прямым доступом. Широкий порт служит для прямого чтения и записи в память, а также для упреждающей выборки команд.
Поскольку типичная 128-байтовая операция прямого чтения/записи требует 16 тактов процессора для пересылки данных по внутренней когерентной шине (даже когда операции прямого чтения/записи выполняются без ограничений на пропускную способность), семь из каждых восьми тактов остаются доступными для операций загрузки, сохранения и выборки команд. Аналогичным образом команды выбираются по 128 байтов за раз, и нагрузка на локальную память остается минимальной. Наивысший приоритет отдан командам DMA, за которыми следуют операции загрузки и сохранения, а операция упреждающей выборки команды выполняется, когда есть свободный такт. Существует специальная команда "без операции", позволяющая при необходимости принудительно обеспечить доступность слота для выборки команды.
Блоки выполнения операций в SPE работают со 128-разрядным потоком данных. Достаточно большой файл регистров из 128 элементов позволяет компилятору переупорядочить команды и компенсировать ла-тентность их выполнения. Имеется только один файл регистров, а все команды являются 128-разрядными SIMD-командами с изменяющейся шириной элемента (2x64, 4x32, 8x16, 16x8 и 128x1 разрядов).
За один такт может быть выдано до двух команд; один слот выдачи команды поддерживает операции с плавающей и фиксированной запятой, а другой обеспечивает загрузку/сохранение, операции перестановки байтов и перехода. Простые операции с фиксированной запятой занимают два такта, а команды одинарной точности с плавающей запятой и команды загрузки требуют шести тактов. Поддерживаются также двухпо-точные SIMD-команды двойной точности с плавающей запятой, но максимальная скорость их выдачи составляет семь тактов на команду. Все остальные команды полностью конвейеризованы.
Для того чтобы ограничить дополнительную нагрузку на оборудование, вызванную прогнозированием ветвлений, программист или компилятор могут "подсказать" переход. Команда подсказки перехода уведомляет оборудование об адресе предстоящей команды перехода и его целевом адресе. Оборудование (в предположении, что доступны слоты локальной памяти) заранее выбирает по меньшей мере 17 команд по целевому адресу перехода. Для уменьшения числа ветвлений в коде можно использовать поразрядную команду выбора с тремя источниками.
Настройка DMA-контроллера, а также наличие очередей запросов позволяет SPE работать параллельно с работой DMA. Именно таким образом удается избежать простаивания SPE в результате задержки получения данных из основной памяти.
Основные параметры:
- площадь кристалла — 253 мм2;
- максимальная частота PLL — 17,5 ГГц;
- 9 ядер, 10 потоков инструкций;
- пиковая пропускная способность памяти — 25,6 Гб/с;
- пиковая пропускная способность каналов ввода/вывода — 75 Гб/с.
Несмотря на то, что PPE и SPE имеют общую память, между ними есть четкое разделение функций. PPE оптимизирован для решения задач управления и смены контекста, в то время как SPE — для решения вычислительных задач.
PPE получает доступ к общей памяти посредством инструкций загрузки/сохранения (через иерархию кэшей), перемещающих данные между регистровым файлом PPE и основной памятью.
SPE получает доступ к общей памяти посредством DMA-передач, перемещающих данные между локальной памятью SPE и общей памятью CELL
Краткие итоги
Процессор Cell представляет собой мощную асимметричную многоядерную процессорную систему. Состоит из процессорного элемента Power, чаще всего выполняющего управляющие функции, и из восьми си-нергичных процессорных элементов, выполняющих основную вычислительную работу. Ядра объединены при помощи двунаправленной кольцевой шины.
Для борьбы с узким местом при доступе в основную память в процессоре Cell в процессорном элементе PPE применяется двухуровневый кэш и аппаратная поддержка двух потоков. В элементах SPE присутствует локальная оперативная память объемом 256 Кбайт и высокопрозводи-тельный блок прямого доступа в память.
Контрольные вопросы
- Какова топология связей между процессорными элементами в процессоре Cell?
- Как реазизована иерахия памяти в процессорном элементе Power?
- Укажите основные составные блоки PPE.
- Опишите структуру векторного сопроцессора PPE.
- Как организована подсистема памяти в процессорном элементе SPE?
Упражнения
- Сравните показатели мультиядерных процессоров Cell с процессорами ARM и MIPS.
< Лекция 9 || Лекция 10 || Лекция 11 >