
|
При попытке исполнения запроса: CREATE DOMAIN EMP_NO AS INTEGER CHECK (VALUE BETWEEN 1 AND 10000); Выдается ошибка: Неизвестный тип объекта "DOMAIN" в интсрукции CREATE, DROP или ALTER. Используется SQL Server MS SQL 2008R2 |
Инспектор
Вы можете этот курс.
Московский государственный университет имени М.В.Ломоносова
Опубликован: 10.10.2005 | Доступ: платный | Студентов: 407 / 5 | Оценка: 3.85 / 3.50 | Длительность: 22:03:00
Тема: Базы данных
Специальности: Администратор баз данных
Лекция 1:
Общее введение, типы данных и средства определения доменов
Аннотация: Оставшаяся часть этого курса посвящается языку реляционных баз данных SQL. В курсе о реляционных базах данных невозможно обойтись без материала, который относится к этому языку. Это связано совсем не с тем, что язык представляет собой особое достижение в области реляционных БД. Напротив, многие черты SQL, начиная с самых первых его вариантов, противоречили принципам реляционной модели данных, заложенным Эдгаром Коддом. С другой стороны, спецификация языка SQL, по своей сути, является завершенной спецификацией модели данных, которая сегодня играет роль суррогата реляционной модели.
Если бы мы попытались обойтись в этом курсе без обсуждения языка SQL, курс был бы полностью оторван от жизни. Сегодня SQL является lingua franca в мире баз данных. Интерфейсы, основанные на SQL, поддерживаются почти во всех используемых СУБД, далеко не все из которых первоначально разрабатывались как реляционные системы. И похоже, что эта ситуация при жизни нынешнего поколения радикальным образом не изменится. Кроме того, язык сам по себе достаточно интересен. В нем нашел отражение многолетний практический опыт многих людей, и он впитал в себя многие положительные (и отрицательные) черты других языков и подходов (не только языков баз данных и не только реляционного подхода).
В данной лекции после небольшой исторической справки и краткого введения в структуру языка SQL будут рассмотрены типы данных, допустимые в языке SQL и в SQL-ориентированных базах данных, а также языковые средства определения, изменения определения и отмены определения доменов.
Ключевые слова: язык баз данных SQL, компания ibm, СУБД System R, SEQUEL, structure, query language, ограничение целостности, D-триггер, авторизация доступа, откат, SQL/DS, DB2, Oracle, Informix, Sybase, подзапрос, Microsoft SQL Server, авторизация доступа к данным, динамический SQL, ANSI, реляционная база данных, стандарт SQL/86, стандарт SQL/89, выборка данных, ключ отношения, внешний ключ, ссылочная целостность, SQL2, стандарт SQL/92, метаданные, описатели, схема базы данных, SQL/CLI, Ada, Pascal, ODBC, open database connectivity, JDBC, SQL/PSM, Persistence, store, MODULE, хранимая процедура, SQL3, тип, определяемый пользователем, стандарт SQL:1999, стандарт языка, foundation, базис, система типов языка SQL, функциональные зависимости, возможный ключ, управление транзакциями, операторы управления, подключение к базе данных, SQL/Bindings, FORTRAN, COBOL, MUMPS, распределенные транзакции, SQL/Transaction, SQL/Temporal, SQL/MED, SQL/OLB, SQL/OLAP, стандарт SQL:2003, SQL/Schemata, SQL/JRT, SQL/XML, routine, programming language, язык программирования java, XML-документ, состояние процесса, систематический, базовый, промежуточный и полный уровни языка SQL, прямой SQL, directed, встроенный SQL, программирование приложений, определение домена, table row, тип символьной строки, тип битовой строки, Character, BIT STRING, базы данных, тип данных, домен, СУБД, точный числовой тип, exact, приближенный числовой тип, character string, тип даты и времени, %datetime, тип временного интервала, interval, булевский тип, boolean, тип коллекции, анонимный строчный тип, anonymity, user-defined, ссылочный тип, reference type, неопределенное значение, выражение, операции, значение выражения, значение, истинно целый тип, SMALLINT, точный тип, допускающий наличие дробной части, non-numerical, decimal, определение столбца, литерал типа, спецификация типа, мантисса, real, double precision, тип значений, CHARACTER VARYING, vary, CLOB, локализация, national characters, интернационализация, операция конкатенации, соединение строк, выделение подстроки, substring, UPPER, октет, CTD, binary, BLOB, TIMESTAMP, time zone, UTC, coordinate, man-month, hour, second, тип дата/время, истинностное значение, предикат, условия поиска, булевское выражение, трехзначная логика, таблица истинности, логические операции, Мультимножество, тип массива, тип мультимножества, конструктор типа массива, преобразование типов, совместимость типов, оператор CAST, cardinality, element, операция объединения, UNION, INTERSECT, distinction, реляционная модель данных, конструктор типа мультимножества, вложенная таблица, структуры баз данных, кортеж отношения, кортеж, конструктор анонимного строчного типа, структурный определяемый пользователем тип, structured type, индивидуальный определяемый пользователем тип, distinct type, типизированная таблица, первичный ключ, ссылочное значение, определение, базовые таблицы, изменение определения домена, отмена определения домена, оператор CREATE DOMAIN, объект базы данных, значение домена по умолчанию, literal, идентификатор пользователя, оператор ALTER DOMAIN, constraint, условное выражение, ограничение домена, EMP, PRO, заработная плата, базовый тип, DROP, оператор DROP DOMAIN, restriction, CASCADE, неявное преобразование типа, явное преобразование типа или домена, скалярное выражение, FC-AL, VC, variable-length, SD, SQL, логический, избыточность, поддержка
Введение
В начале лекции мы представим небольшой исторический обзор SQL. Язык уже далеко не молод. В 2004 г. сообщество баз данных отметило его 30-летний юбилей. Поэтому, чтобы правильно понимать и трактовать современные варианты SQL, нужно знать историю языка хотя бы в общих чертах.
Краткая история языка SQL
Язык SQL, предназначенный для взаимодействия с базами данных, появился в середине 70-х гг. (первые публикации датируются 1974 г.) и был разработан в компании IBM в рамках проекта экспериментальной реляционной СУБД System R. Исходное название языка SEQUEL (Structured English Query Language) только частично отражало суть этого языка. Конечно, язык был ориентирован главным образом на удобную и понятную пользователям формулировку запросов к реляционным БД. Но, в действительности, он почти с самого начала являлся полным языком БД, обеспечивающим помимо средств формулирования запросов и манипулирования БД следующие возможности:
- средства определения и манипулирования схемой БД;
- средства определения ограничений целостности и триггеров;
- средства определения представлений БД;
- средства определения структур физического уровня, поддерживающих эффективное выполнение запросов;
- средства авторизации доступа к отношениям и их полям 1В этом абзаце применяется терминология, которая использовалась в публикациях, посвященных System R . ;
- средства определения точек сохранения транзакции, и выполнения фиксации и откатов транзакций.
В языке отсутствовали средства явной синхронизации доступа к объектам БД со стороны параллельно выполняемых транзакций: с самого начала предполагалось, что необходимую синхронизацию неявно выполняет СУБД.
В настоящее время язык SQL реализован во всех коммерческих реляционных СУБД и почти во всех СУБД, которые изначально основывались не на реляционном подходе. Все компании-производители провозглашают соответствие своей реализации стандарту SQL, и на самом деле реализованные диалекты SQL очень близки. Этого удалось добиться не сразу.
Наиболее близки к System R были две системы компании IBM – SQL/DS и DB2 2Как это ни странно, компания IBM, имевшая уникальный и положительный опыт реализации экспериментальной реляционной СУБД System R, не стала первой компанией, выпустившей на рынок коммерческую реляционную СУБД. Компанию IBM опередила на два года незадолго до того образованная компания Oracle, выпустившая свою первую систему в 1979 г. Современные эксперты по разному объясняют причины этой "заторможенности" IBM, но, по всей видимости, основная причина кроется в традиционном консерватизме руководства компании.. Разработчики обеих систем использовали опыт проекта System R, а СУБД SQL/DS напрямую основывалась на программном коде System R. Отсюда предельная близость диалектов SQL, реализованных в этих системах, к SQL System R. Из SQL System R были удалены только те части, которые были недостаточно проработаны (например, точки сохранения) или реализация которых вызывала слишком большие технические трудности (например, ограничения целостности и триггеры). Можно назвать этот путь к коммерческой реализации SQL движением сверху вниз.
Другой подход применялся в таких системах, как Oracle, Informix и Sybase. Несмотря на различие в способах разработки систем, реализация SQL везде происходила "снизу вверх". В первых выпущенных на рынок версиях этих систем использовалось ограниченное подмножество SQL System R. В частности, в первой известной нам реализации SQL в СУБД Oracle в операторах выборки не допускалось использование вложенных подзапросов и отсутствовала возможность формулировки запросов с соединениями нескольких отношений.
Тем не менее, несмотря на эти ограничения и на очень слабую, на первых порах, эффективность СУБД, ориентация компаний на поддержку разных аппаратных платформ и заинтересованность пользователей в переходе к реляционным системам позволили компаниям добиться коммерческого успеха и приступить к совершенствованию своих реализаций. В текущих версиях Oracle, Informix, Sybase и Microsoft SQL Server поддерживаются достаточно мощные диалекты SQL, хотя реализация иногда вызывает сомнения. 3Например, одной из выигрышных черт SQL System R являлось то, что в одной транзакции разрешалось комбинировать все возможные операторы SQL. Поскольку технически это обеспечить достаточно трудно, почти во всех сегодняшних SQL -ориентированных СУБД имеются ограничения на состав операторов, которые можно выполнять в одной транзакции.
Особенностью большинства современных коммерческих СУБД, затрудняющей сравнение существующих диалектов SQL, является отсутствие единообразного описания языка. Обычно описание разбросано по разным руководствам и перемешано с описанием специфических для данной системы языковых средств, не имеющих прямого отношения к SQL. Тем не менее можно сказать, что базовый набор операторов SQL, включающий операторы определения схемы БД, выборки и манипулирования данными, авторизации доступа к данным, поддержки встраивания SQL в языки программирования и операторы динамического SQL, в коммерческих реализациях устоялся и более или менее соответствует стандарту.
Деятельность по стандартизации языка SQL началась практически одновременно с появлением его первых коммерческих реализаций. В 1982 г. комитету по базам данных Американского национального института стандартов (ANSI) было поручено разработать спецификацию стандартного языка реляционных баз данных. Первый документ из числа имеющихся у автора проектов стандарта датирован октябрем 1985 г. и является уже не первым проектом стандарта ANSI. Стандарт был принят ANSI в 1986 г., а в 1987 г. одобрен Международной организацией по стандартизации (ISO). Этот стандарт принято называть SQL/86 .
Понятно, что в качестве основы стандарта нельзя было использовать SQL System R. Во-первых, этот вариант языка не был должным образом технически проработан. Во-вторых, его слишком сложно было бы реализовать (кто знает, как бы сложилась судьба SQL, если бы все идеи проекта System R были реализованы полностью). Поэтому за основу был взят диалект языка SQL, сложившийся в IBM к началу 1980-х гг. В сущности, этот диалект представлял собой технически проработанное подмножество SQL System R.
К 1989 г. стандарт SQL/86 был несколько расширен, и был подготовлен и принят следующий стандарт, получивший название ANSI/ISO SQL/89 . Анализ доступных документов показывает, что процесс стандартизации SQL происходил очень сложно с использованием не только научных доводов. В результате SQL/89 во многих частях имеет чрезвычайно общий характер и допускает очень широкое толкование. В этом стандарте полностью отсутствуют такие важные разделы, как манипулирование схемой БД и динамический SQL. Многие важные аспекты языка в соответствии со стандартом определяются в реализации. 4Это практически обесценивает стандарт с точки зрения программистов приложений баз данных, поскольку не дает возможности создавать приложения, не привязанные к особенностям конкретных СУБД.
Возможно, наиболее важными достижениями стандарта SQL/89 являются четкая стандартизация синтаксиса и семантики операторов выборки данных и манипулирования данными и фиксация средств ограничения целостности БД. Были специфицированы средства определения первичного и внешних ключей отношений и так называемых проверочных ограничений целостности, которые представляют собой подмножество немедленно проверяемых ограничений целостности SQL System R. Средства определения внешних ключей позволяют легко формулировать требования так называемой ссылочной целостности БД. Это распространенное в реляционных БД требование можно было сформулировать и на основе общего механизма ограничений целостности SQL System R, но формулировка на основе понятия внешнего ключа более проста и понятна.
Осознавая неполноту стандарта SQL, на фоне завершения разработки этого стандарта специалисты различных компаний начали работу над стандартом SQL2. Эта работа также длилась несколько лет, было выпущено множество проектов стандарта, пока наконец в марте 1992 г. не был принят окончательный проект стандарта ( SQL/92 ). Этот стандарт существенно полнее стандарта SQL/89 и охватывает практически все аспекты, необходимые для реализации приложений: манипулирование схемой БД, управление транзакциями (появились точки сохранения) и сессиями (сессия – это последовательность транзакций, в пределах которой сохраняются временные отношения), подключения к БД, динамический SQL. Наконец, были стандартизованы отношения-каталоги БД, что вообще-то не связано непосредственно с языком, но очень сильно влияет на реализацию. 5Среди прочих достижений System R нельзя не отметить то, что в базах данных, управляемых этой СУБД, хранились как данные, так и метаданные – описатели отношений, их полей, представлений, ограничения целостности и т.д. Для хранения метаданных использовались специальные служебные отношения, которые стали называть отношениями-каталогами. Из отношений-каталогов можно было выбрать данные с помощью обычных средств языка SQL. Конечно, организация служебных данных – это вопрос реализации SQL, но этот вопрос непосредственно касается потенциальных пользователей SQL -ориентированных СУБД, и поэтому стандартизация представления пользователю отношений-каталогов (в стандарте SQL, информационной схемы базы данных) является исключительно важным делом.
В 1995 г. стандарт был дополнен спецификацией интерфейса уровня вызова (Call-Level Interface – SQL/CLI ). SQL/CLI представляет собой набор спецификаций интерфейсов процедур, вызовы которых позволяют выполнять динамически задаваемые операторы SQL . По сути дела, SQL/CLI представляет собой альтернативу динамическому SQL. Интерфейсы процедур определены для всех основных языков программирования: С, Ada, Pascal, PL/1 и т. д. Следует заметить, что стандарт SQL/CLI послужил основой для создания повсеместно распространенных сегодня интерфейсов ODBC (Open Database Connectivity) и JDBC (Java Database Connectivity).
В 1996 г. к стандарту SQL/92 был добавлен еще один компонент – SQL/PSM (Persistent Stored Modules). Основная цель этой спецификации состоит в том, чтобы стандартизировать способы определения и использования хранимых процедур, т. е. специальным образом оформленных программ, включающих операторы SQL, которые сохраняются в базе данных, могут вызываться приложениями и выполняются внутри СУБД.
Незадолго до завершения работ по определению стандарта SQL2 была начата разработка стандарта SQL3. Первоначально планировалось завершить проект в 1995 г. и включить в язык некоторые объектные возможности: определяемые пользователями типы данных, поддержку триггеров, поддержку темпоральных свойств данных и т. д. Реально работу над новым стандартом удалось частично завершить только в 1999 г., и по этой причине (а также в связи с проблемой 2000 года) стандарт получил название SQL:1999.
Приведем краткую характеристику текущего состояния стандарта SQL:1999 и перспектив его развития. Прежде всего, заметим, что каждый новый вариант стандарта языка SQL был существенно объемнее предыдущих версий. Так, если стандарт SQL/89 занимал около 600 страниц, то объем SQL/92 составлял на 300 с лишним страниц больше. Самые первые проекты SQL3 занимали около 1500 страниц. Это вполне естественно, потому что язык усложняется, а его спецификации становятся более детальными и точными. Но разработчики SQL3 пришли к выводу, что при таких объемах стандарта вероятность его принятия и последующей успешной поддержки заметно уменьшается. Поэтому было принято решение разбить стандарт на относительно независимые части, которые можно было бы разрабатывать и поддерживать по отдельности.
В 1999 г. были приняты пять первых частей стандарта SQL:1999. Первая часть (SQL/Framework) посвящена описанию концептуальной структуры стандарта. В этой части приводится развернутая аннотация следующих четырех частей и формулируются требования к реализациям, претендующим на соответствие стандарту.
Вторая часть SQL:1999 (SQL/Foundation) образует базис стандарта. Вводится система типов языка, формулируются правила определения функциональных зависимостей и возможных ключей, определяются синтаксис и семантика основных операторов SQL:
- операторов определения и манипулирования схемой базы данных;
- операторов манипулирования данными;
- операторов управления транзакциями;
- операторов управления подключениями к базе данных и т. д.
Третью часть занимает уточненная по сравнению с SQL/92 спецификация SQL/CLI. В четвертой части специфицируется SQL/PSM – синтаксис и семантика языка определения хранимых процедур. Наконец, в пятой части – SQL/Bindings – определяются правила связывания SQL для стандартных версий языков программирования FORTRAN, COBOL, PL/1, Pascal, Ada, C и MUMPS.
В стандарт SQL:1999 должны были войти еще несколько частей. Среди них спецификации следующих средств:
- управление распределенными транзакциями ( SQL/Transaction );
- поддержка темпоральных свойств данных ( SQL/Temporal );
- управление внешними данными ( SQL/MED );
- связывание с объектно-ориентированными языками программирования ( SQL/OLB );
- поддержка оперативной аналитической обработки ( SQL/OLAP ).
В конце 2003 г. был принят и опубликован новый вариант международного стандарта SQL:2003 . Многие специалисты считали, что в варианте стандарта, следующем за SQL:1999, будут всего лишь исправлены неточности SQL:1999. Но на самом деле, в SQL:2003 специфицирован ряд новых и важных свойств, часть из которых мы затронем в этом курсе.
Претерпела некоторые изменения общая организация стандарта. Стандарт SQL:2003 состоит из следующих частей:
- 9075-1, SQL/Framework;
- 9075-2, SQL/Foundation;
- 9075-3, SQL/CLI ;
- 9075-4, SQL/PSM ;
- 9075-9, SQL/MED ;
- 9075-10, SQL/OLB ;
- 9075-11, SQL/Schemata ;
- 9075-13, SQL/JRT ;
- 9075-14, SQL/XML.
Части 1-4 и 9-10 с необходимыми изменениями остались такими же, как и в SQL:1999 (разд. 7.4). Часть 5 ( SQL/Bindings ) перестала существовать; соответствующие спецификации включены в часть 2. Раздел части 2 SQL:1999, посвященный информационной схеме, выделен в отдельную часть 11. Появились две новые части – 13 и 14. Часть 13 полностью называется "SQL Routines and Types Using the Java Programming Language" ("Использование подпрограмм и типов SQL в языке программирования Java"). Появление такой части стандарта оправдано повышенным вниманием к языку Java со стороны ведущих производителей SQL -ориентированных СУБД. Наконец, последняя часть SQL:2003 посвящена спецификациям языковых средств, позволяющих работать с XML-документами в среде SQL.
На мой взгляд, текущее состояние процесса стандартизации языка SQL отражает текущее состояние технологии SQL -ориентированных баз данных. Ведущие поставщики соответствующих СУБД (сегодня это компании IBM, Oracle и Microsoft) стараются максимально быстро реагировать на потребности и конъюнктуру рынка и расширяют свои продукты все новыми и новыми возможностями. Очевидна потребность в стандартизации соответствующих языковых средств, но процесс стандартизации явно не поспевает за происходящими изменениями.
Структура языка SQL
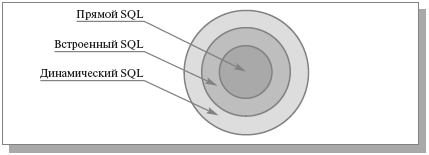
В данной лекции мы начинаем систематически описывать базовые механизмы языка SQL. Чтобы пояснить, о какой части языка пойдет речь в этой и следующих лекциях, обратимся к рис. 11.1.
Язык SQL, соответствующий последним стандартам SQL:2003, SQL:1999 (и даже SQL/92 ), это очень богатый и сложный язык, все возможности которого трудно сразу осознать и тем более понять. Поэтому приходится разбивать язык на уровни, или слои, такие, что каждый уровень языка включает все конструкции, входящие в более низкие уровни. В стандарте определяется несколько способов разбиения языка на уровни. В одной из классификаций язык разбивается на "базовый" (entry), "промежуточный" (intermediate) и "полный" (full) уровни.
Эта классификация ориентирована, прежде всего, на производителей СУБД, в которых поддерживается SQL. Реализация базового уровня языка является обязательным условием хотя бы какого-то соответствия стандарту. Реализация промежуточного уровня желательна, и обычно именно такой уровень языка поддерживается ведущими компаниями-производителями SQL -ориентированных СУБД. Наконец, полный уровень языка является целью, к достижению которой следует стремиться. В данной классификации критерием отнесения той или иной возможности языка к некоторому уровню является оцениваемая создателями стандарта SQL (большая часть которых является сотрудниками ведущих компаний, производящих SQL -ориентированные СУБД) техническая сложность реализации этой возможности. Конечно, такая классификация важна и для программистов приложений баз данных, но только для того, чтобы оценить реальные возможности конкретной СУБД. Для понимания языка SQL это разбиение на уровни несущественно.
Другая классификация показана на рис. 11.1. Среди всех конструкций языка SQL можно выделить такие конструкции, которые можно было использовать при "прямом" (direct) взаимодействии конечного пользователя с СУБД (например, в интерактивном режиме). В некотором смысле этот уровень также является базовым, поскольку соответствующие средства языка в наибольшей степени отражают его ориентированность на работу с множествами. На следующем уровне, уровне "встраиваемого" (embedded) SQL, язык расширяется конструкциями, позволяющими использовать возможности прямого SQL в программах, написанных на традиционных языках программирования. Наконец, на уровне "динамического" (dynamic) SQL во встраиваемый SQL добавляются конструкции, позволяющие приложениям обращаться к СУБД с конструкциями прямого SQL, которые динамически образуются во время выполнения программы.
Нам кажется, что вторая классификация является более полезной для читателя, постигающего основы языка SQL. По нашему мнению, дополнительные возможности, присутствующие во встраиваемом и в динамическом SQL, не слишком сильно влияют на модельное представление языка. Конечно, возможности встраиваемого и динамического SQL необходимо хорошо знать разработчикам приложений SQL -ориентированных баз данных. Но поскольку задачей этого курса не является обучение использованию языка SQL при программировании приложений баз данных, мы не будем затрагивать эти темы. Обратимся к прямому SQL, причем не в полном объеме стандартов SQL:2003 и SQL:1999 (этого не позволяет сделать объем курса). Обсудим только наиболее важные аспекты.
В этой лекции обсуждаются основные аспекты системы типов данных языка SQL и средства определения доменов.
Замечание: Лекции, посвященные языку SQL, опираются, главным образом, на стандарт SQL:1999. В тех случаях, когда будут упоминаться дополнительные возможности, специфицированные в наиболее свежей версии стандарта – SQL:2003, мы будем явно на это указывать. Поэтому здесь мы используем терминологию стандарта (таблицы, строки, столбцы и т. д.). 6К сожалению, приходится использовать термин строка в двух смыслах: строка таблицы (table row) и символьная или битовая строка (character or bit string). Постараемся обеспечить правильное понимание смысла термина в контексте его использования.