
|
Здравствуйте! Записался на ваш курс, но не понимаю как произвести оплату. Надо ли писать заявление и, если да, то куда отправлять? как я получу диплом о профессиональной переподготовке? |
Инспектор
Вы можете этот курс.
Опубликован: 05.03.2005 | Доступ: платный | Студентов: 1153 / 8 | Оценка: 4.11 / 3.63 | Длительность: 13:20:00
ISBN: 978-5-9556-0027-7
Тема: Программирование
Специальности: Тестировщик
Лекция 14:
Регрессионное тестирование: алгоритм и программная система поддержки
< Лекция 13 || Лекция 14 || Практическая работа 1 >
Аннотация: Рассматриваются методики регрессионного тестирования, полный алгоритм регрессионного тестирования и программная система его поддержки.
Ключевые слова: методика регрессионного тестирования, сочетания, ПО, структура системы, файл, список, множества, поиск, макроопределения, функция, запуск, выходные данные, архитектура, модуль, сценарий, автоматизация
Методика регрессионного тестирования
Методика предназначена для эффективного решения задачи выборочного повторного тестирования. Ее исходными данными являются: программа P и ее модифицированная версия P', критерий тестирования C, множество (набор) тестов T, ранее использовавшихся для тестирования P, информация о покрытии элементов P (M(P,C)) тестами из T. Необходимо реализовать эффективный способ, гарантирующий достаточную степень уверенности в правильности P', используя тесты из T .
Методика строится на основе сочетания процедур обычного и регрессионного тестирования
Рассмотрим процедуру обычного тестирования. В ней для получения информации о тестируемых объектах в ходе тестирования необходимо установить соответствие между покрываемыми элементами и тестами для их проверки. Соответственно, процедура тестирования должна включать приведенную ниже последовательность действий:
- Определить требуемые функциональные возможности программы с использованием, например, метода разбиения на классы эквивалентности.
- Создать тесты для требуемых функциональных возможностей.
- Выполнить тесты.
- В случае необходимости - создать и выполнить дополнительные тесты для покрытия оставшихся (еще не покрытых) структурных элементов (предварительно установив их соответствие функциональным требованиям).
- Создать базу данных тестов программы.
По аналогии с обычным тестированием, процедура регрессионного тестирования в процессе сопровождения состоит из следующих этапов:
- Использование функции предсказания целесообразности. Если прогнозируемое количество выбранных тестов больше, чем порог целесообразности, провести повторный прогон всех тестов. В противном случае перейти к шагу 2.
- Идентификация изменений
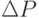 в программе P' (и множества
в программе P' (и множества  измененных покрываемых элементов) и установление взаимно однозначного соответствия между покрываемыми элементами М(P, C) и М(P', C) в соответствии с изменениями:
измененных покрываемых элементов) и установление взаимно однозначного соответствия между покрываемыми элементами М(P, C) и М(P', C) в соответствии с изменениями: 
- Выбор
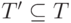 - подмножества исходных тестов, потенциально способных выявить связанные с изменениями ошибки в P', для повторного выполнения на P', с использованием результатов, полученных в пункте 2. Это подмножество можно упорядочить, а также указать число тестов, выполнения которых достаточно для соответствия какому-либо критерию минимизации. Для безопасных методов отбора тестов множество T' удовлетворяет следующим ограничениям:
- подмножества исходных тестов, потенциально способных выявить связанные с изменениями ошибки в P', для повторного выполнения на P', с использованием результатов, полученных в пункте 2. Это подмножество можно упорядочить, а также указать число тестов, выполнения которых достаточно для соответствия какому-либо критерию минимизации. Для безопасных методов отбора тестов множество T' удовлетворяет следующим ограничениям: 
- Применение подмножества T' для регрессионного тестирования измененной программы P' с целью проверки результатов и установления факта корректности P' по отношению к T' (в соответствии с измененным техническим заданием), а также обновления информации о прохождении тестов из T' на P'.
- В случае необходимости - создание дополнительных тестов для дополнения набора регрессионных тестов. Это могут быть новые функциональные тесты, необходимые для тестирования изменений в техническом задании или новых функциональных возможностей измененной программы; новые структурные тесты для активизации оставшихся (непокрытых) структурных элементов (предварительно установив их соответствие проверяемым функциональным требованиям).
- Создание T'' - нового набора тестов для P', применение его для тестирования измененной программы, проверка результатов и установление факта корректности P' по отношению к T'', обновление информации о ходе исполнения теста и создание базы данных тестов измененной программы для хранения этой информации и выходных данных тестов. Удаление устаревших тестов. T'' формируется по следующему правилу:

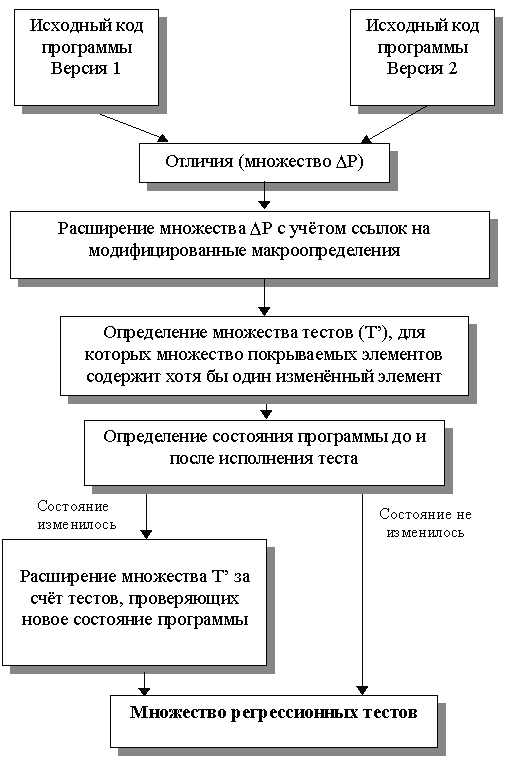
Система поддержки регрессионного тестирования
Структура системы поддержки регрессионного тестирования представлена на
рис.
14.1. Исходный код обеих версий тестируемой программы хранится под управлением системы контроля версий. Для отбора тестов по методу покрытия точек использования неисполняемых определений средствами системы контроля версий создается файл различий, на основании которого вычисляется список добавленных, измененных и удаленных строк исходного кода, который является удобной формой представления множества . Затем производится перебор этого списка. Если какая-либо строка списка представляет собой макроопределение, осуществляется поиск строк кода, содержащих использование этого макроопределения по всему тексту тестируемой программы; найденные строки присоединяются к множеству . Расширенное множество сопоставляется с результатами прогона тестов из множества T на предыдущей версии программы. Если в ходе выполнения какого-либо теста ti получала управление хотя бы одна строка, входящая в множество , тест ti отбирается для повторного запуска.
При создании новых тестов по методу "подозрительных" состояний функция тестируемой программы, содержащая цикл обработки событий, дополняется операторами вывода значений глобальных и видимых локальных переменных. Запуск тестов из множества T' на профилированной версии программы позволяет получить список ее состояний. Этот список анализируется, и для каждого ранее не наблюдавшегося состояния вычисляется список переменных, изменившихся по сравнению с каким-либо известным состоянием. Множество дополняется строками кода, где используются переменные из этого списка. Для каждого состояния указываются тесты, запуск которых необходим. Наконец, создается список рекомендованных новых тестов в форме, удобной для восприятия человеком.
Выходные данные каждой программы-обработчика доступны пользователю, что позволяет контролировать промежуточные результаты работы системы. К примеру, можно исключить из рассмотрения переменные, которые, хотя и изменяются в ходе выполнения программы, на ее состояние не влияют. Архитектура системы позволяет легко расширять функциональность; например, для поддержания какой-либо новой системы контроля версий достаточно создать один новый модуль объемом около 100 строк кода. Остальные модули можно использовать без изменений.
Типовой сценарий проведения регрессионного тестирования программ, написанных на языке C, с применением описанной выше системы состоит из следующих этапов:
- Вычисляется множество строк исходного кода, добавленных, удаленных или измененных по сравнению с предыдущей версией.
- Множество дополняется строками, непосредственно не изменявшимися, но содержащими ссылки на измененные макроопределения
- Вычисляется упорядоченное множество регрессионных тестов T', для которых
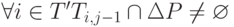 , где Ti, j-1 - множество строк исходного кода продукта, получающих управление в ходе выполнения теста i на версии системы j-1. Тесты упорядочиваются по убыванию количества измененных строк в пути их исполнения.
, где Ti, j-1 - множество строк исходного кода продукта, получающих управление в ходе выполнения теста i на версии системы j-1. Тесты упорядочиваются по убыванию количества измененных строк в пути их исполнения. - Вычисляется список глобальных и локальных переменных, определяющих состояние программы s. Исходный код тестируемой программы модифицируется так, что информация о состоянии s (значения глобальных, статических и локальных переменных) выводится во внешний файл перед запуском теста и после его окончания.
- Новые тесты и тесты из множества T' (регрессионные тесты) исполняются на текущей версии продукта j.
- Тесты, проверяющие нештатные режимы работы продукта, т.е. создающие состояния, в которых дальнейшая работа продукта невозможна в соответствии со спецификацией требований, исключаются из рассмотрения. Если известно, что ни один тест не приводит к возникновению нештатных состояний, данный этап может быть опущен
- Для каждого теста i вычисляется множество Tij.
- Обрабатываются результаты выполнения тестов, и создается множество Sj, состоящее из начального состояния s0 и всех наблюдавшихся конечных состояний. Вычисляется множество Nj= Sj\Sj-1 всех новых по сравнению с предыдущими версиями состояний, которое является "подозрительным" с точки зрения наличия ошибок, и вектора их отличий от исходного состояния s0, т.е. переменные, измененные по сравнению с s0.
- Множество измененных строк исходного кода дополняется номерами строк, где используются заданные переменные
- Если
 , цикл работы завершается. Если
, цикл работы завершается. Если 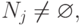 следует перейти к шагу 4 или, если счетчик количества итераций работы системы превышает некоторое заданное предельное значение, известить об этом пользователя. Пользователь может принять решение о прекращении тестирования или пропуске некоторого числа циклов.
следует перейти к шагу 4 или, если счетчик количества итераций работы системы превышает некоторое заданное предельное значение, известить об этом пользователя. Пользователь может принять решение о прекращении тестирования или пропуске некоторого числа циклов.
Если этап 6 выполняется автоматически, а этап 7 можно опустить, возможна полная автоматизация регрессионного тестирования.
< Лекция 13 || Лекция 14 || Практическая работа 1 >