Микроархитектура zSeries
Микроархитектура процессоров
Микроархитектура процессоров моделей z9ХХ, z8XX eServer zSeries [2.17, 2.18] является дальнейшим развитием микроархитектуры процессоров S390 четвертой генерации G4 [2.16]. Процессоры G4 имели 32-разрядную организацию, объединенную КЭШ команд и данных, шестиуровневый конвейер и допускали объединение в многочиповом модуле МСМ по схеме (10+2)-way (10 центральных и 2 вспомогательных процессора). В последующих моделях S390 были добавлены новые архитектурные решения, такие, как операции с плавающей точкой в формате по стандарту IEEE-754 Binary Floating Point -BFP (G5), увеличение числа процессоров в МСМ по схеме (12+2)-way и др. В моделях z9ХХ, z8XX с z/Architecture основными дополнениями являются:
- 64-разрядная организация, включая 64-разрядные регистры общего назначения, 64-разрядные управляющие регистры, 64-разрядную виртуальную и реальную адресацию;
- область префиксации расширена с 4 КB до 8 КB;
- раздельные КЭШ команд и данных;
- 173 новые команды, в том числе 34 команды для режимов ESA/390 и 139 для z/Architecture;
- число процессоров в МСМ увеличено до 20 по схеме (16+4)-way;
- расширение формата слова состояния программы PSW до 128 разрядов и др.
Процессоры серверов z/Architecture имеют дублированную структуру с зеркальным исполнением команд в двух процессорных каналах. Каждый такой канал (рис. 2.23) состоит из последовательно включенных блоков команд (I-unit) и операций (E-unit). Блок команд предназначен для выборки и дешифрации команд из КЭШ команд первого уровня (L1-I), вычисления адресов операндов и запуска процессов их выборки из КЭШ данных первого уровня (L1-D), формирования очереди команд для исполнения в блоке E. Блок Е выполняет операции, заданные в командах, над операндами из регистров или памяти и запись результатов в регистры или память. Дополнительные тракты обработки реализованы в сопроцессоре COP.

КЭШ-память первого уровня реализована в одном чипе с процессорными каналами и в моделях z/Architecture разделена на две независимые КЭШ команд и данных. В предшествующих архитектурах использовалась объединенная КЭШ команд и данных. Обе КЭШ и их контроллеры сосредоточены в блоке управления BCE (buffer control element).
Основные и промежуточные результаты и адреса, формируемые в процессорных каналах, передаются в блок восстановления R (Recovery Unit) для сохранения в дополнительной регистровой памяти - области точек контроля (checkpoint array). Все данные, формируемые блоками I, E каналов, перед записью в регистры или память сравниваются для контроля правильности выполнения операций и обнаружения ошибок в работе каналов. Сохраняемая в регистрах блока R информация может использоваться для восстановления работы каналов в случае сбоев. Для уменьшения вероятности одинаковых ошибок в каналах используется ассиметричное исполнение команд в основном и зеркальном каналах путем временного сдвига на целое число тактов.
Каждый из процессорных каналов имеет конвейерную организацию (рис. 2.24) с оптимальным срабатыванием уровней за один такт. При исполнении сложных команд или в случае конвейерных сбоев отдельные уровни срабатывают за большее число тактов. Основные функции первых трех уровней конвейера реализуются в блоке команд I. Первый уровень (IF) реализует выборку команд за несколько тактов и иногда рассматривается как отдельный блок, а не как уровень конвейера. Выбранные из КЭШ L1-I (КЭШ L2 или основной памяти) команды помещаются в буфер команд, из которого передаются во второй уровень (D) для распаковки и дешифрации. На этой стадии из заданных в адресной части регистров считываются компоненты адреса (база, индекс) операнда, и команда передается в очередь команд для исполнения в блоке обработки. Следующий уровень конвейера (AGEN) используется для вычисления логического адреса операнда путем сложения базы, индекса и смещения. Конвейер оптимизирован для двухадресных команд формата RX с размещением одного операнда в регистре, а второго - в памяти. Вычисленный адрес передается в блок BCE для обращения в память.

В блоке BCE реализуются два уровня конвейера, связанных с выборкой операндов из КЭШ L1-D (КЭШ L2 или основной памяти). Первый из этих уровней запускает одновременные процессы обращения в директорию КЭШ и буфер преобразования адреса TLB, а второй выполняет чтение операнда и размещение его в буфере операндов в блоке обработки E с подстыковкой к ранее считанным операндам.
В блоке обработки Е выполняются операции команд, считываемых из очереди команд, над операндами, находящимися в программно-доступных регистрах и буфере операндов. Для этого используются два уровня, первый из которых (E1) реализует выполнение операции в АЛУ, а второй (WR) - сохранение результата в регистре или памяти. Выполнение большинства операций в АЛУ с фиксированной точкой занимает один такт, а в АЛУ с плавающей точкой - три такта, для сложных операций число тактов может достигать 100 и более. Для ускорения операций в АЛУ используется внутренний конвейер. Запись результата операций осуществляется в регистры или КЭШ-память.
Структурная схема процессора приведена на рис. 2.25.
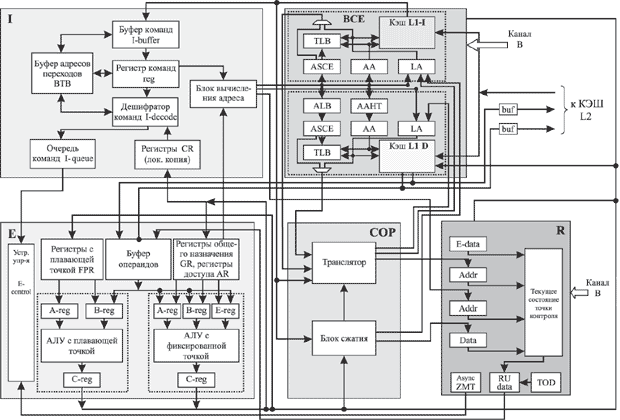
Блок команд I процессора z/Architecture расширен для поддержки трех режимов адресации (24, 31, 64 бит). Буфер команд I-buffer предназначен для хранения последовательных участков исполняемых программ и состоит из нескольких фрагментов, каждый из которых содержит одну строку из КЭШ команд. Каждая из строк в буфере распаковывается и передается покомандно в регистр команд. После завершения распаковки очередной строки запускается чтение новой строки из КЭШ команд. Чтение из КЭШ выполняется с использованием буфера адресов переходов BTB (branch target buffer) емкостью 8К строк для ускорения формирования адресов в командах условного перехода путем их предсказания. BTB представляет собой таблицу, каждая строка которой содержит информацию, занесенную при выполнении команды ветвления: адрес команды ветвления, фактически использованный адрес перехода и другую вспомогательную информацию. При выполнении очередной команды ветвления по адресу этой команды осуществляется поиск в таблице, и при успешном поиске из соответствующей строки BTB считывается предсказываемый адрес перехода. Далее запускается выборка из КЭШ соответствующей ветви программы до момента фактического вычисления адреса ветвления и его сравнения с предсказанным.При совпадении конвейер процессора продолжает функционировать без задержки, в противном случае выполняется восстановление работы конвейера, требующее нескольких дополнительных тактов. Для команд ветвления, завершающих циклические участки программ, вероятность успешного предсказания перехода высока и определяется 1-2 неправильными предсказаниями на все число повторений цикла. Отключение BTB исключает "лишние" обращения в КЭШ и может использоваться для разгрузки КЭШ в пользу других абонентов.
Каждый такт из буфера команд в регистр команд передается одна команда. Декодирование команд, находящихся в регистре команд, осуществляется за один такт в порядке их следования в программе. Помимо определения типа операции и условий ее исполнения на этапе декодирования из регистровой памяти считываются компоненты, необходимые для вычисления адреса. В следующем такте в блоке вычисления адреса реализуется сложение компонентов адреса (в общем случае - базы, индекса и смещения) и полученный адрес используется для обращения в КЭШ данных за операндом. Декодированные команды помещаются в очередь команд, откуда подаются в блок обработки в порядке их следования в программе.
Блок обработки E включает регистровую память и два АЛУ для выполнения операций с фиксированной и плавающей точкой. В качестве источников операндов АЛУ используются программно доступные регистры общего назначения GR и регистры с плавающей точкой FPR, регистры доступа AR, а также буфер операндов, считанных из памяти. Результаты операций могут быть сохранены в регистрах GR, FPR или в памяти.
Основное АЛУ для операций с фиксированной точкой включает три входных 64-разрядных регистра A-reg, B-reg, E-reg, выходной регистр C-reg и следующие тракты обработки:
- 64-разрядный двоичный сумматор с возможность побайтового изменения разрядности и инвертирования входных операндов;
- 64-разрядный блок для выполнения поразрядных логических операций и операций сдвига;
- 64-разрядный десятичный сумматор для выполнения операций над двоично-десятичными числами, включая деление и умножение;
- блок двоично-десятичных преобразований для перехода от одной формы представления к другой.
АЛУ для операций с плавающей точкой (FPU) включает 2 входных A-reg, B-reg и выходной C-reg 64-разрядные регистры с конвейеризированным трактом обработки чисел в форматах HFP, BFP. Конвейер FPU состоит из 5 уровней и выполняет большинство операций с пропускной способностью одна операция за один такт.
Ускорение операций в АЛУ достигается введением конвейерной обработки, дополнительные уровни которой ( E-1, E0 на рис. 2.24) размещены в уровнях основного конвейера, предшествующих выполнению операций в АЛУ. Уровень E-1 формирует многоразрядное управляющее слово для выборки операндов из регистровой памяти и формирования маски. Уровень E0 используется для чтения операндов.
Блок управления обращениями в память BCE включает две независимые КЭШ команд и данных, а также интерфейс с КЭШ второго уровня L2. Обе КЭШ имеют одинаковый объем 256 KB, сходные схемы управления и относятся к частично-ассоциативным (four-way-set-associative) КЭШ с размером строки 256 байт. Разрядность выборки из КЭШ команд - четыре слова (16 байт). КЭШ данных допускает сквозную (write-through) запись и расслоена на два блока, допускающих одновременные обращения двойными словами, например, для выполнения чтения из одного и записи в другой блок. Обмен данными между КЭШ команд и данных, например для записи из КЭШ данных в КЭШ команд, может выполняться через КЭШ L2, допускающую обратную (write-back) запись и реализующую протокол поддержки когерентности содержимого КЭШ команд и данных всех процессоров системы.
Поскольку КЭШ функционирует в абсолютном адресном пространстве, а блок команд формирует логические адреса (LA), необходимо преобразование адреса с использованием в общем случае таблиц из буферов ALB, TLB, региональных, сегментных и страничных таблиц. Уменьшение времени трансляции адреса достигается за счет ее конвейеризации (см. этапы C0, C1, C2 на рис. 2.24). Кроме этого в КЭШ данных предусмотрена таблица AAHT (Absolute Address History Table), содержащая ранее использованные абсолютные адреса (AA) и компоненты соответствующих им логических адресов. При обращении на этапе C0 в блоке команд по содержимому регистров, содержащих компоненты адреса, формируется индекс для поиска в таблице AAHT для предсказания части разрядов абсолютного адреса. При попадании в AAHT на этапе C1 выполняется обращение в директорию и запоминающий массив КЭШ. При промахе на этапе C1 таблица AAHT модифицируется и осуществляется обращение в буфер преобразования адреса TLB с использованием соответствующего кода управления адресным пространством ASCE, получаемого из таблицы ALB на этапе C0 или соответствующим преобразованием. Если поиск в TLB не дает положительного результата, в сопроцессоре COP в блоке транслятора (translator) запускается полное преобразование адреса с использованием соответствующих таблиц в памяти.
В КЭШ команд абсолютные адреса формируются аналогично, однако абсолютные адреса могут быть предсказаны не по таблице AAHT, а из буфера BTB в блоке выборки команд.
При попадании в КЭШ первого уровня обмен данными выполняется за один такт, в противном случае запускается цикл обращения в КЭШ второго уровня L2.
Дополнительные тракты обработки информации, а также аппаратные средства для динамического преобразования адреса реализованы в виде сопроцессора COP, состоящего из двух блоков:
- блок сжатия, предназначенный для упаковки/распаковки данных и преобразования символьной информации;
- блок транслятора, реализующий преобразование виртуальных адресов в реальные с использованием таблиц, размещенных в памяти.
Упаковка/распаковка информации в блоке сжатия осуществляется по команде CMPSC, задающей исходную область памяти, с которой выполняется операция, область размещения результата, адрес словаря, используемого в операции, и дополнительные управляющие биты, уточняющие выполняемую операцию. Для упаковки используется метод Lempel-Ziv 2 (LZ2) со статическими словарями.
Преобразование символьной информации, выполняемое блоком сжатия, определяется командами TR, TRT, TRE и др. и заключается в побайтном преобразовании исходного операнда в операнд результата с использованием таблицы преобразования, индексируемой байтами исходного операнда.
Входные данные для блока поступают в сопроцессор с выходной шины блока обработки E, а результат выдается в блок R с последующей записью в память. В блоке предусмотрены входной и выходной буферы по 256 байт. Кроме этого блок имеет интерфейс с памятью через КЭШ команд для чтения из памяти словарей и таблиц, необходимых для выполнения преобразований. При упаковке/распаковке словарь может достигать объема 64 КВ и считывается построчно. Таблица для команд символьных преобразования имеет объем 256 байт и полностью считывается в имеющийся в блоке дополнительный буфер.
Блок транслятора реализует функции динамического преобразования виртуальных адресов в реальные с использованием трех региональных, сегментной и страничной таблиц. Каждое преобразование запускается в случае промаха при поиске в таблице TLB в блоке BCE и может потребовать до пяти обращений в память. Вместе с виртуальным адресом из блока BCE передается тип адресного пространства, код ASCE и другие параметры, необходимые для формирования базового адреса первой из используемых таблиц преобразования. Выборка строк таблиц из памяти выполняется через КЭШ команд с использованием общего с блоком сжатия интерфейса. Блок транслятора позволяет ускорить преобразования адресов, что особенно важно в случае использования режимов виртуальных ЭВМ, когда одновременно функционируют host-система и несколько guest-систем. В этом случае реальный адрес, полученный в системе более низкого уровня (guest-системе), рассматривается как виртуальный в системе более высокого уровня (host-системе или guest-системе), что может потребовать большого числа обращений в память для каждого преобразования. Например, при двухуровневом преобразовании при каждом обращении guest-системы в одну из пяти таблиц может потребоваться до пяти обращений в таблицы host-системы, что приводит к необходимости выполнять до 25 обращений в память при полном преобразовании.
Блок восстановления R входит в состав двухканального процессора для реализации функций контроля правильности функционирования путем сравнения информации, формируемой процессорными каналами, а также для накопления информации о состояниях процессора в точках контроля с целью восстановления работы процессора в случае сбоев. Для этого в блоке предусмотрена регистровая память, в которую заносятся управляющие коды различных режимов, коды прерываний, адреса и операнды, используемые командах, содержимое всех программно доступных регистров (GR, AR, FPR, CR). Перед записью информация от двух каналов сравнивается, и при обнаружении ошибок под управлением блока R выполняется следующая последовательность мер по восстановлению:
- завершаются все записи в КЭШ L2, инициированные исполненными командами;
- в блоках I, E, BCE выполняется сброс;
- буферы TLB, ALB, директория и массив КЭШ очищаются;
- запоминается прерывание по восстановлению, которое будет исполнено после завершения процесса восстановления;
- все записи из регистровой памяти блока R проверяются на правильность по контрольным кодам и восстанавливаются во всех блоках, откуда они поступили, при наличии неустраняемых ошибок процессор переводится в состояние СБОЙ;
- осуществляется запуск выполнения команды в соответствии с восстановленным состоянием, если в ближайшее после запуска время сбой повторяется, процессор переводится в состояние СБОЙ, иначе продолжается нормальная работа процессора.
Поскольку блоки R, BCE не дублируются, их контроль осуществляется путем использования избыточного кодирования для обнаружения и коррекции ошибок.
Отличительной особенностью процессоров zSeries является использование комбинированного аппаратно-программного способа для реализации многих процессорных функций, в том числе части наиболее сложных команд. Для этого в процессоре введен дополнительный уровень управления, реализующий подмножество команд, называемое милликодом (millicode) [2.19]. Милликод включает часть простейших команд, входящих в базовую систему команд z/Architecture, и вспомогательные команды для прямого управления функциями и аппаратными средствами процессора. В систему команд милликода включены команды адресного чтения-записи для обращения в регистровую память блока R, что делает возможным доступ к кодам состояний процессора и их изменение, тем самым создается эффективный механизм управления процессором. Милликод используется также для обработки прерываний путем приостановки выполнения текущего потока команд и перехода к программе милликода по фиксированному адресу.
Для исполнения команд милликода используются те же аппаратные средства, что и для основных команд. Высокая скорость исполнения обеспечивается ускорением перехода к милликоду и возврата к основной программе, а также оптимизацией аппаратных средств для быстрого выполнения команд милликода. С этой целью в процессоре введен особый режим исполнения команд милликода с использованием дополнительного набора теневых регистров MGR (Millicode General-Purpose Register), адресуемых командами милликода. Для возможности обращения к основным регистрам в состав милликода введены специальные команды. Запуск подпрограммы милликода, реализующей функции команды базовой системы, выполняется как безусловный переход по фиксированному адресу, определяемому кодом операции команды. Такой переход занимает несколько тактов, что обеспечивает высокую скорость перехода. Возврат из милликода также выполняется как безусловный переход к команде по адресу из модифицированного программного счетчика. Все программы милликода размещаются в системной области памяти HSA и при обращении переносятся в КЭШ команд.