|
При попытке исполнения запроса: CREATE DOMAIN EMP_NO AS INTEGER CHECK (VALUE BETWEEN 1 AND 10000); Выдается ошибка: Неизвестный тип объекта "DOMAIN" в интсрукции CREATE, DROP или ALTER. Используется SQL Server MS SQL 2008R2 |
Московский государственный университет имени М.В.Ломоносова
Опубликован: 10.10.2005 | Доступ: свободный | Студентов: 8512 / 662 | Оценка: 3.85 / 3.50 | Длительность: 22:03:00
Тема: Базы данных
Специальности: Администратор баз данных
Теги:
Лекция 5:
Группировка и условия раздела HAVING, порождаемые и соединенные таблицы
Агрегатные функции, группировка и условия раздела HAVING
В этом разделе мы систематически обсудим все аспекты группировки таблиц и вычисления агрегатных функций. Некоторые темы уже затрагивались на неформальном уровне в предыдущих лекциях.
Семантика агрегатных функций
Агрегатные функции (в стандарте SQL они называются функциями над множествами) 2Оба термина являются приемлемыми. Речь идет об агрегатных функциях, поскольку аргументом функции является агрегатное (составное) значение. Речь идет о функциях над множествами, поскольку аргументом функции является множество (в общем случае, мультимножество) значений. Но более правильно было бы говорить о групповых функциях, поскольку в большинстве случаев такие функции работают на значениях столбцов групп строк. определяются следующими синтаксическими правилами:
<set_function_specification> ::=
COUNT(*)
| set_function_type ([DISTINCT | ALL ] value_expression)
| GROUPING (column_reference)
<set_function_type> ::=
{ AVG | MAX | MIN | SUM | EVERY | ANY | SOME | COUNT }Как видно из этих правил, в стандарте SQL:1999 определены пять стандартных агрегатных функций: COUNT - число строк или значений, MAX - максимальное значение, MIN - минимальное значение, SUM - суммарное значение и AVG - среднее значение, а также две "кванторные" функции EVERY и SOME ( ANY ). В последних двух случаях выражение должно иметь булевский тип. Обсуждение функции GROUPING мы отложим до следующей лекции.
Агрегатные функции предназначены для того, чтобы вычислять некоторое значение для заданного мультимножества строк. Таким мультимножеством строк может быть группа строк, если агрегатная функция применяется к сгруппированной таблице, или (в вырожденных случаях) вся таблица. Для всех агрегатных функций, кроме COUNT(*), фактический (т. е. требуемый семантикой) порядок вычислений состоит в следующем. На основании параметров агрегатной функции из заданного мультимножества строк производится список значений. Затем по этому списку значений производится вычисление функции. Если список оказался пустым, то значением функции COUNT для него является 0, значением функции SOME - false, значением функции ALL - true, а значением всех остальных функций - NULL.
Пусть T обозначает тип значений из этого списка (вернее, "наименьший общий" тип, см. раздел "Скалярные выражения" лекции 13). Типы значений агрегатных функций определяются следующими правилами.
- Результат вычисления функции COUNT - это точное число с точностью и шкалой, которые определяются в реализации.
- Тип результата значений функций MAX и MIN совпадает с T. При вычислении функций SUM и AVG тип T не должен быть типом символьных строк.
- Если T представляет собой тип точных чисел, то и типом результата функции является тип точных чисел с определяемыми в реализации точностью и шкалой.
- Если T представляет собой тип приблизительных чисел, то и типом результата функции является тип приблизительных чисел с определяемой в реализации точностью.
- Для функций EVERY и SOME T является булевским типом3Поскольку, как отмечалось в Лекции 11, в SQL к булевскому значению uknown принято относиться точно так же, как и к неопределенному значению, в списке значений для вычисления этих функций не останутся значения uknown ..
- Первая функция принимает значение true в том и только в том случае, когда вычисление выражения-аргумента дает значение true для каждой строки из заданного набора строк, и false, когда значение выражения-аргумента есть false хотя бы для одной строки из заданного набора строк.
- Функция SOME принимает значение false в том и только в том случае, когда значение выражения-аргумента есть false для каждой строки из заданного набора строк, и true, когда значение выражения-аргумента есть true хотя бы для одной строки из заданного набора строк.
Вычисление функции COUNT(*) производится путем подсчета числа строк в заданном мультимножестве. Все строки считаются различными, даже если они состоят из одного столбца со значением null во всех строках. 4Обратите внимание на то, что это еще один вид различения строк в SQL и еще одна скрытая интерпретация неопределенного значения. COUNT(*) работает так, как если бы выполнялось соотношение 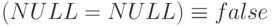 . Тем самым, в SQL применяются все три возможных интерпретации NULL. При вычислении логических выражений полагается
. Тем самым, в SQL применяются все три возможных интерпретации NULL. При вычислении логических выражений полагается  ; при определении строк-дубликатов неявно считается, что
; при определении строк-дубликатов неявно считается, что 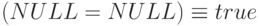 ; наконец, при вычислении агрегатной функции COUNT(*) неявно полагается, что .
Конечно, в такой "тройственности" нет ничего хорошего, но в контексте языка SQL приходится мириться с этими и другими негативными последствиями наличия неопределенных значений.
; наконец, при вычислении агрегатной функции COUNT(*) неявно полагается, что .
Конечно, в такой "тройственности" нет ничего хорошего, но в контексте языка SQL приходится мириться с этими и другими негативными последствиями наличия неопределенных значений.
Если "арифметическая" ( AVG, MAX, MIN, SUM, COUNT ) агрегатная функция специфицирована с ключевым словом DISTINCT, то множество значений, на котором она вычисляется, строится из значений указанного выражения, вычисляемого для каждой строки заданной группы строк. Затем из этого мультимножества удаляются неопределенные значения, и в нем устраняются значения-дубликаты (т. е. образуется множество). После этого вычисляется указанная функция.
Если агрегатная функция специфицирована без ключевого слова DISTINCT (или с ключевым словом ALL ), то мультимножество значений формируется из значений выражения, вычисляемого для каждой строки заданной группы строк. Затем из этого мультимножества удаляются неопределенные значения, и производится вычисление агрегатной функции.
Результаты запросов и агрегатные функции
Об использовании агрегатных функций в разделах HAVING и SELECT оператора выборки упоминалось в разделе "Общие синтаксические правила построения скалярных выражений" лекции 13. В данном подразделе уместно повторить и уточнить этот материал.
Агрегатные функции можно разумным образом использовать в списке выборки (при построении выражений, являющихся элементами выборки) и в логическом выражении раздела HAVING (вернее, в выражениях, входящих в простые условия). Рассмотрим разные случаи применения агрегатных функций в списке выборки в зависимости от вида табличного выражения.
Если результат табличного выражения R не является сгруппированной таблицей (т. е. в табличном выражении отсутствуют разделы GROUP BY и HAVING ), то появление в списке выборки хотя бы одного вызова агрегатной функции от (мульти) множества строк R приводит к тому, что R неявно рассматривается как сгруппированная таблица, состоящая из одной (или нуля, если R пусто) групп с отсутствующими столбцами группирования. Поэтому в данном случае в выражениях списка выборки не допускается прямое использование имен столбцов R: все они должны находиться внутри спецификаций вызова агрегатных функций. Результатом запроса является таблица, состоящая не более чем из одной строки, значения столбцов которой получены путем применения агрегатных функций к R.
Аналогично обстоит дело в том случае, когда R представляет собой сгруппированную таблицу, но табличное выражение не содержит раздела GROUP BY (и, следовательно, содержит раздел HAVING ). В этом случае считается, что результат табличного выражения явно объявлен сгруппированной таблицей, состоящей из одной группы, и результат запроса можно формировать только путем применения агрегатных функций к данной группе строк. Опять результатом запроса является таблица, состоящая не более чем из одной строки, значения столбцов которой получены путем применения агрегатных функций к R.
Наконец, рассмотрим случай, когда R представляет собой "настоящую" сгруппированную таблицу, т. е. табличное выражение содержит раздел GROUP BY, и, следовательно, определен по крайней мере один столбец группирования (т. е. имеется хотя бы один такой столбец, что для любой группы его значения одинаковы во всех строках группы). В этом случае правила формирования списка выборки полностью соответствуют правилам формирования условия выборки раздела HAVING. Другими словами, в выражениях, являющихся элементами списка выборки, допускается прямое использование имен столбцов группирования, а спецификации остальных столбцов R могут появляться только внутри спецификаций агрегатных функций. Результатом запроса является таблица, число строк в которой равно числу групп в R. Значения столбцов каждой строки формируются на основе значений столбцов группирования и вызовов агрегатных функций для соответствующей группы.