Сохранение объектов и базы данных (БД)
Обсуждение: за пределами ОО-баз данных
Завершим этот обзор мечтами о возможных направлениях развития сохраняемости в будущем. Следующие далее наблюдения носят предварительный характер, их цель - побудить дальнейшие размышления, а не предложить конкретные ответы.
Является ли "ОО-база данных" оксюмороном?
Понятие базы данных произошло от взгляда на мир, в центре которого сидят Данные, а расположенным вокруг программам разрешены доступ и модификация этих Данных:
Однако в объектной технологии мы научились понимать данные как сущности, полностью определяемые применяемыми к ним операциями:

Эти два взгляда кажутся несовместимыми! Понятие данных, существующих независимо от обрабатывающих их программ ("независимость данных", догмат, повторяемый на первых страницах любой книги по БД) является проклятием для ОО-разработчика. Должны ли мы считать выражение "ОО-база данных" оксюмороном1Оксюморон (oxymoron) - соединение несовместимых понятий (горячий лед, оглушительная тишина).
Возможно, нет, но, быть может, стоит понять, как в догматическом ОО-контексте можно получить эффект баз данных, реально не имея их. Если мы дадим определение (упрощая до самого существенного данное ранее в этой лекции определение БД)
БАЗА ДАННЫХ = СОХРАНЯЕМОСТЬ + РАЗДЕЛЕНИЕ ДАННЫХ,
то догматический взгляд будет рассматривать второй компонент, разделение данных, как несовместимый с ОО-идеями, и сосредоточится только на сохраняемости. Но тогда можно подойти к разделению данных, используя другой метод - параллелизм! Это показано на следующем рисунке.
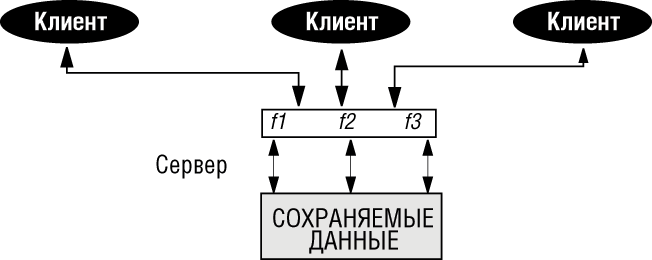
Следуя ОО-принципам, сохраняемые данные реализуются как множество объектов - экземпляров некоторых абстрактных типов данных - и управляются некоторой серверной системой. Системы клиентов, которым требуется работать с данными, будут делать это через сервер. Так как эта схема требует разделения и параллельного доступа, то клиенты будут рассматривать сервер как сепаратный в смысле, определенном при обсуждении параллельности в "Параллельность, распределенность, клиент-сервер и Интернет" . Например:
flights: separate FLIGHT_DATABASE; ...
flight_details (f: separate FLIGHT_DATABASE;
rf: REQUESTED_FLIGHTS): FLIGHT is
do
Result := f.flight_details (rf)
end
reserve (f: separate FLIGHT_DATABASE; r: RESERVATION) is
do
f.reserve (r); status := f.status
endТогда на стороне сервера не требуется никакого механизма разделения, а только общий механизм сохранения. Нам могут также понадобиться средства и методы для поддержки версий объектов, но они, по существу, относятся к вопросам сохраняемости объектов, а не к базам данных.
В этом случае механизм сохранения может стать чрезвычайно простым, отбросив многое из багажа БД. Можно даже считать, что все объекты по умолчанию являются постоянно хранимыми, а временные объекты становятся исключением, обрабатываемым механизмом, обобщающим сбор мусора. Такой подход, который невозможно было представить при изобретении БД, становится менее абсурдным при постоянном уменьшении стоимости памяти и росте доступности 64-битовых виртуальных адресных пространств, в которых, как было уже замечено в [Sombrero-Web], " можно создавать каждую секунду новый 4-гигабайтный объект (вся память обычного 32-битного процессора) в течение 136 лет и все еще не исчерпать доступные адреса. Этого достаточно, чтобы сохранить все данные, связанные с почти любым приложением на протяжении всего его существования ".
Все это весьма умозрительно и нет никаких оснований для того, чтобы отказываться от традиционного понятия БД. Не следует также немедленно мчаться и продавать акции компаний, создающих ОО-БД. Рассматривайте это обсуждение как интеллектуальное упражнение: приглашение прозондировать будущее общепринятого понятия ОО-БД, проверив, может ли существующий подход по-настоящему успешно справиться со страшным сопротивлением несогласованности между методом разработки ПО и механизмами, поддерживающими накопление и хранение данных.
Неструктурированная информация
Последнее замечание о БД. Взрывной рост Интернета и появление средств поиска, основанного на контексте (в момент написания книги наиболее известными примерами таких средств были AltaVista, Web Crawler и Yahoo), показал, что можно получать доступ к данным и при отсутствии БД.
СУБД требуют, чтобы перед сохранением любых данных вы сначала конвертировали их в строго определенный формат схемы БД. Недавние исследования, тем не менее, показали, что 80% электронных данных в компаниях являются неструктурированными (т. е. располагаются вне БД, как правило, в текстовых файлах), несмотря на многолетнее использование баз данных. Сюда и внедряются средства поиска по контексту: по заданным пользователем критериям, включающим ключевые слова и фразы, они могут извлечь данные из неструктурированных или минимально структурированных документов. Почти каждый, кто испробовал эти средства, был ослеплен блеском скорости, с которой они извлекают информацию: секунды или двух достаточно, чтобы найти иголку в стоге байтов размером в тысячи гигабайт. Это неизбежно приводит к вопросу: нужны ли нам на самом деле структурированные БД?
Пока еще ответ - да. Неструктурированные и структурированные данные будут сосуществовать. Но БД больше не являются единственной выбором; все более и более изощренные средства для запросов смогут извлекать информацию, даже если она не имеет формата, требуемого БД. Разумеется, для создания таких средств лучше всего подходит ОО-технология.