Параллельность, распределенность, клиент-сервер и Интернет
Параллельная архитектура
Использование объявлений separate для ответа на важный вопрос "этот объект находится здесь или в другом месте?", оставляя возможности различных физических реализаций параллельности, предполагает двухуровневую архитектуру (рис. 12.4), аналогичную той, которая подходит и для механизмов графики (с библиотекой Vision, находящейся выше библиотек, специфических для разных платформ, см. "ОО-метод для графических интерактивных приложений" ).
На верхнем уровне этот механизм не зависит от платформы. Большая часть приложений, рассматриваемых в этой лекции, использует этот уровень. Для выполнения параллельного вычисления приложения просто используют механизм объявлений separate.
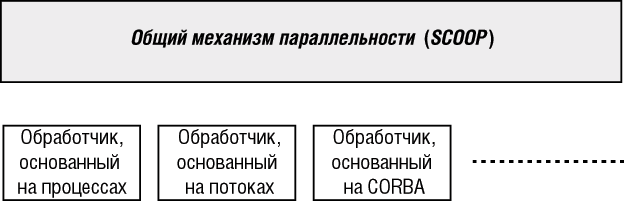
Внутренняя реализация будет опираться на некоторую конкретную параллельную архитектуру (на рис. 12.4 это нижний уровень). На рис. 12.4 показаны следующие возможности:
- Реализация может использовать процессы, предоставляемые операционной системой. Каждый процессор связывается с некоторым процессом. Такое решение поддерживает распределенные вычисления: процесс сепаратного объекта может находиться как на удаленной машине, так и на локальной. Для нераспределенной обработки его преимущество в том, что процессы стабильны и хорошо известны, а недостаток - в том, что оно приводит к интенсивной загрузке ЦПУ, так как и создание нового процесса, и обмен информацией между процессами являются дорогими операциями.
- Реализация может использовать потоки. Как уже отмечалось, потоки - это облегченная версия процессов, минимизирующая стоимость создания и переключения контекстов. Однако потоки должны располагаться на одной машине.
- Возможна также реализация, использующая механизм распределения CORBA в качестве физического уровня для обмена объектами в сети.
- Другими возможными механизмами являются ПВМ (PVM) (параллельная виртуальная машина - Parallel Virtual Machine), язык параллельного программирования Linda, потоки Java...
Как всегда, в случае двухуровневых архитектур соответствие между конструкциями верхнего уровня и реальным распределением на уровне платформы ( описателем (handle) в терминах предыдущей лекции) в большинстве случаев устанавливается автоматически, так что разработчики приложений будут видеть только верхний уровень. Но при необходимости и готовности отказаться от платформенной независимости им также должны быть доступны механизмы нижнего уровня.
Распределение процессоров: файл управления параллелизмом (Concurrency Control File)
Если в программе не задаются физические ЦПУ, то их спецификация должна быть помещена в каком-то другом месте. Вот один из способов позаботиться об этом. Подчеркнем, что это лишь одно из возможных решений, не претендующее на фундаментальность; точный формат здесь несущественен, но любой способ конфигурирования будет так или иначе предоставлять одну и ту же информацию.
В качестве примера мы выбрали "Файл управления параллелизмом" (ФУП) ("Concurrency Control File" (CCF)), описывающий доступные программам ресурсы параллельных вычислений. ФУПы по целям и по виду похожи на файлы Ace, используемые для управления сборкой системы (лекция 7 курса "Основы объектно-ориентированного программирования"). Типичный ФУП выглядит так:
creation
local_nodes:
system
"pushkin" (2): "c:\system1\appl.exe"
"akhmatova" (4): "/home/users/syst1"
Current: "c:\system1\appl2.exe"
end
remote_nodes:
system
"lermontov": "c:\system1\appl.exe"
"tiutchev" (2): "/usr/bin/syst2"
end
end
external
Ingres_handler: "mandelstam" port 9000
ATM_handler: "pasternak" port 8001
end
default
port: 8001; instance: 10
end|
Для всех рассматриваемых свойств имеются значения по умолчанию, поэтому ни одна из трех частей ( creation, external, default ) не является обязательной, как и сам ФУП. |
Часть creation определяет, какие ЦПУ используются для сепаратного создания (инструкций вида create x.make (...) для сепаратной x ). В примере используются две группы ЦПУ: local_nodes, предположительно включающие локальные машины, и remote_nodes. Программа может выбрать группу ЦПУ с помощью вызова вида:
set_cpu_group ("local_nodes")указывающего, что последующие операции сепаратного создания будут использовать ЦПУ группы local_nodes до появления следующего вызова set_cpu_group. Эта процедура описана в классе CONCURRENCY, предоставляющем средства для механизма управления, который мы подробней рассмотрим ниже.
Соответствующие элементы ФУП указывают, какие ЦПУ следует использовать для группы local_nodes: первые два объекта будут созданы на машине pushkin, следующие четыре - на машине akhmatova, а следующие десять - на текущей машине (т. е. на той, на которой выполняются инструкции создания). После этого схема распределения будет повторяться - два объекта на машине pushkin и т. д. Если число процессоров отсутствует, как у Current в примере, то оно извлекается из пункта instance в части default (здесь оно равно 10 ), а если такого пункта нет, то берется равным 1. Система, используемая для создания каждого экземпляра, указывается для каждого элемента, например, для pushkin это будет c:\system1\appl.exe (очевидно, машина работает под Windows или OS/2).
В этом примере все процессоры привязаны к процессам. ФУП также поддерживают назначение процессоров потокам (для описателей, основанных на потоках) и другие механизмы параллельности, хотя мы здесь не будем входить в их детали.
Часть external указывает, где располагаются существующие внешние сепаратные объекты. ФУП ссылается на эти объекты через их абстрактные имена, в примере Ingres_handler и ATM_handler, используемые в качестве аргументов функций при установлении связи с ними. Например, для функции server с аргументами:
server (name: STRING; ... Другие аргументы ...): separate DATABASE
вызов вида server ("Ingres_handler", ...) даст сепаратный объект, обозначающий сервер базы данных Ingres. ФУП указывает, что соответствующий объект расположен на машине mandelstam и доступен через порт 9000. Если порт явно не задан, то его значение извлекается из части defaults, а если и там его нет, то используется некоторое универсальное предопределенное значение.
ФУП существует отдельно от программ. Можно откомпилировать параллельное или распределенное приложение без всякой ссылки на специфическое оборудование и архитектуру сети, а затем во время выполнения каждый отдельный компонент этого приложения будет использовать свой ФУП для связи с другими существующими компонентами (часть external ) и для создания новых компонентов (часть creation ).
Этот набросок соглашений, принятых в ФУП, показал, как можно отобразить абстрактные понятия параллельных ОО-вычислений - процессоры и сепаратные объекты (внешние и создаваемые) - на физические ресурсы. Как уже отмечалось, эти соглашения являются только примером того, как это можно сделать, но не являются частью базового механизма параллельности. Они показывают возможность отделения архитектуры параллельной системы от архитектуры параллельного оборудования.
Библиотечные механизмы
При подходах типа ФУП программа приложения может быть никак не связана с конкретной физической параллельной архитектурой. Однако некоторым разработчикам ПО требуется более тонкий контроль, осуществляемый приложением (ценой возможного удорожания при динамической реконфигурации). Некоторые функции ФУП должны быть доступны непосредственно самому приложению, позволяя ему, например, выбрать для некоторого процессора определенный процесс или поток. Они будут доступны через библиотеки, как часть двухуровневой параллельной архитектуры; это не приведет ни к каким трудным проблемам. Позже в этой лекции мы еще столкнемся с необходимостью дополнительных библиотечных механизмов.
С другой стороны, некоторым приложениям может потребоваться неограниченное реконфигурирование во время исполнения. Тогда недостаточно иметь возможность прочесть ФУП или аналогичную информацию о конфигурации во время старта, а затем ее придерживаться. Но также плохо перечитывать информацию о конфигурации перед выполнением каждой операции, поскольку это убило бы эффективность. Снова разумное решение - использование библиотечного механизма: должна быть доступна процедура для динамического чтения информации о конфигурации, позволяющая приложению адаптироваться к новой конфигурации тогда (и только тогда), когда оно готово это сделать.
Правила обоснования корректности: разоблачение предателей
Так как для сепаратных и несепаратных объектов семантика вызовов различна, то важно гарантировать, что несепаратная сущность (объявленная как x: T для несепаратного T ) никогда не будет присоединена к сепаратному объекту. В противном случае, вызов x.f (a) был бы неверно понят - в том числе и компилятором - как синхронный, в то время как присоединенный объект, на самом деле, является сепаратным и требует асинхронной обработки. Такая ссылка, ошибочно объявленная несепаратной, но хранящая верность другой стороне, будет называться ссылкой-предателем (traitor). Нам нужно простое правило обоснования корректности, чтобы гарантировать отсутствие предателей в ПО, а именно, что каждый представитель или лоббист сепаратной стороны надлежащим образом зарегистрирован как таковой соответствующими властями.
У этого правила будут четыре части. Первая часть устраняет риск создания предателей посредством присоединения, т. е. путем присваивания или передачи аргументов:
|
Правило (1) корректности сепаратности Если источник присоединения (в инструкции присваивания или при передаче аргументов) является сепаратным, то его целевая сущность также должна быть сепаратной. |
Присоединение цели x к источнику y является либо присваиванием x := y, либо вызовом f (..., y, ..), в котором y - это фактический аргумент, соответствующий x. Такое присоединение, в котором y сепаратная, а x нет, делает x предателем, поскольку сущность x может быть использована для доступа к сепаратному объекту (объекту, присоединенному к y ) под несепаратным именем, как если бы он был локальным объектом с синхронным вызовом. Приведенное правило это запрещает.
|
Отметим, что синтаксически x является сущностью, а y может быть произвольным выражением. Поэтому нам следует определить понятие "сепаратного выражения". Простое выражение - это сущность; более сложные выражения являются вызовами функций (напомним, в частности, что инфиксное выражение вида a + b формально рассматривается как вызов: нечто вроде a.plus (b) ). Отсюда сразу получаем определение: выражение является сепаратным, если оно является сепаратной сущностью или сепаратным вызовом. |
Как станет ясно из последующего обсуждения, присоединение несепаратного источника к сепаратной цели безвредно, хотя, как правило, не очень полезно.
Нам нужно еще дополнительное правило, охватывающее случай, когда клиент передает сепаратному поставщику ссылку на локальный объект. Пусть имеется сепаратный вызов:
x.f (a),
в котором a типа T не является сепаратной, а x является. Объявление процедуры f в классе, порождающем x, будет иметь вид:
f (u:SOME_TYPE)
а тип T сущности a должен быть совместен с SOME_TYPE. Но этого недостаточно! Глядя с позиций поставщика (т. е. обработчика x) объект O1, присоединенный к a, расположен на другой стороне - имеет другого обработчика, поэтому, если не объявить соответствующий формальный аргумент u как сепаратный, он станет предателем, так как даст доступ к сепаратному объекту так, как будто он несепаратный:
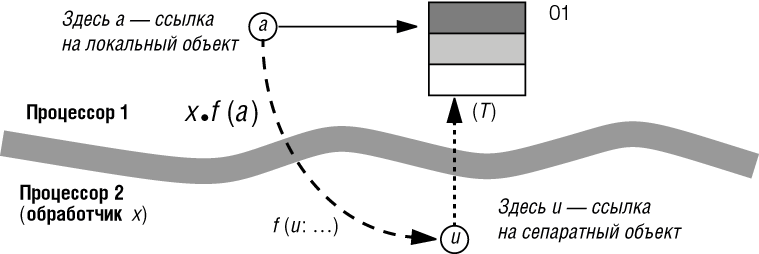
Таким образом, SOME_TYPE должен быть сепаратным, например, это может быть separate T. Отсюда получаем второе правило корректности:
|
Правило (2) корректности сепаратности Если фактический аргумент сепаратного вызова имеет тип ссылки, то соответствующий формальный аргумент должен быть объявлен как сепаратный. |
Здесь рассматриваются только ссылочные аргументы. Случай развернутых типов, включая базовые типы, такие как INTEGER, рассматривается далее.
Иллюстрируя эту технику, рассмотрим объект, порождающий большое число сепаратных объектов, наделяя их возможностью обращаться в дальнейшем к его ресурсам, т. е. говоря им: "Вот вам моя визитная карточка, звоните мне, если потребуется". Типичным примером будет ядро операционной системы, которое создает сепаратные объекты, оставаясь готовым выполнять операции по их запросам. Создание объектов будет иметь вид:
create subsystem.make (Current, ... Другие аргументы ...),
где Current - это визитная карточка, позволяющая subsystem запомнить своего создателя (progenitor) и в случае необходимости попросить у него помощь. Поскольку Current - это ссылка, то соответствующий формальный аргумент в make должен быть объявлен как сепаратный. Чаще всего make будет иметь вид:
make (p: separate PROGENITOR_TYPE; ... Другие аргументы ...) is
do
progenitor := p
... Остальные операции инициализации ...
endпри котором значение аргумента создателя запоминается в атрибуте progenitor объемлющего класса. Второе правило корректности сепаратности требует, чтобы p была объявлена как сепаратная, а первое правило требует того же от атрибута progenitor. Тогда вызовы ресурсов создателя вида progenitor.some_resource (...) будут корректно трактоваться как сепаратные.
Аналогичное правило нужно и для результатов функций.
|
Правило (3) корректности сепаратности Если источник присоединения является результатом вызова функции, возвращающей тип ссылки, то цель должна быть объявлена как сепаратная. |
Поскольку последние два правила относятся к фактическим аргументам и результатам только ссылочных типов, то нужно еще одно правило для развернутых типов.
Иными словами, единственные развернутые значения, которые можно передавать в сепаратный вызов - это "полностью развернутые" объекты, не содержащие никаких ссылок на другие объекты. Иначе можно снова попасть в неприятную ситуацию с предателем, так как присоединение развернутого значения приводит к копированию объекта.
Рис. 12.6 иллюстрирует случай, когда формальный аргумент u является развернутым. Тогда при присоединении поля объекта O1 просто копируются в соответствующие поля объекта O'1, присоединенного к u (см. лекцию 8 курса "Основы объектно-ориентированного программирования"). Если разрешить O1 содержать ссылку, то это приведет к полю-предателю в O'1. Та же проблема возникнет, если в O1 будет подобъект со ссылкой; это отмечено в правиле фразой "непосредственно или опосредовано".
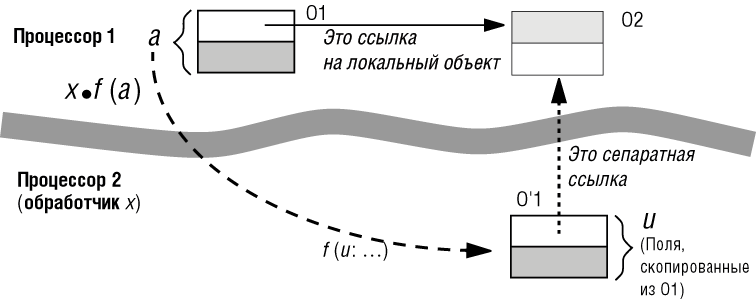
Если формальный аргумент u является ссылкой, то присоединение является клоном; вызов будет создавать новый объект O'1, как показано на последнем рисунке, и присоединять к нему ссылку u. В этом случае можно предложить перед вызовом явно создавать клон на стороне клиента:
a: expanded SOME_TYPE; a1: SOME_TYPE ... a1 := a; -- Это клонирует объект и присоединяет a1 к клону x.f (a1)
Согласно второму правилу корректности формальный аргумент u должен иметь тип, согласованный с типом сепаратной ссылки separate SOME_TYPE. Вызов в последней строке делает u сепаратной ссылкой, присоединенной ко вновь созданному клону на стороне клиента.
Импорт структур объекта
Одно из следствий правил корректности сепаратности состоит в том, что для получения объекта, обрабатываемого другим процессором, нельзя использовать функцию clone (из универсального класса ANY ). Эта функция была объявлена как:
clone (other: GENERAL): like other is
-- Новый объект с полями, идентичными полям other
...Поэтому попытка использовать y := clone (x) для сепаратного x нарушила бы часть 1-го правила: x, которая является сепаратной, не соответствует несепаратной other. Это то, чего мы и добивались. Сепаратный объект, обрабатываемый на машине во Владивостоке, может содержать (несепаратные) ссылки на объекты, находящиеся во Владивостоке. Если же его клонировать в Канзас Сити, то в результирующем объекте окажутся предатели - ссылки на сепаратные объекты, хотя в породившем их классе соответствующие атрибуты сепаратными не объявлялись.
Следующая функция из класса GENERAL позволяет клонировать структуру сепаратного объекта без создания предателей:
deep_import (other: separate GENERAL): GENERAL is
-- Новый объект с полями, идентичными полям other
...Результатом будет структура несепаратного объекта, рекурсивно скопированная с сепаратной структуры, начиная с объекта other. По только что объясненной причине операция поверхностного импорта может приводить к предателям, поэтому нам нужен эквивалент функции deep_clone (см. лекцию 8 курса "Основы объектно-ориентированного программирования"), применяемый к сепаратному объекту. Таковым является функция deep_import. Она будет создавать копию внутренней структуры, делая все встречающиеся при этом копии объектов несепаратными. (Конечно, она может содержать сепаратные ссылки, если в исходной структуре были ссылки на объекты, обрабатываемые другими процессорами).
Для разработчиков распределенных систем функция deep_import является удобным и мощным механизмом, с помощью которого можно передавать по сети сколь угодно большие структуры объектов без необходимости писать какие-либо специальные программы, гарантирующие точное дублирование.