|
В лекции №2 вставляю модуль данных. При попытке заменить name на fDM выдает ошибку: "The project already contains a form or module named fDM!". Что делать? |
Опубликован: 07.05.2010 | Доступ: свободный | Студентов: 3074 / 350 | Оценка: 4.49 / 4.19 | Длительность: 25:58:00
Темы: Базы данных, Программирование
Специальности: Администратор баз данных
Лекция 23:
Стандартные функции InterBase. UDF
Аннотация: На этой лекции мы разберем подробный синтаксис встроенных функций InterBase, а также опробуем их на примерах. Кроме того, мы познакомимся с механизмом UDF (внешние пользовательские функции), создадим DLL-файл с такой функцией и подключим его к базе данных.
Ключевые слова: interbase, UDF, count, условия поиска, MAX, MIN, SUM, CAST, UPPER, GEN_ID, синтаксис, IBConsole, сервер, Interactive SQL, агрегатные функции, значение, множества, AVG, параметр, DISTINCT, функция, выборка, максимум, минимум, тип данных, поле, числовой тип, double precision, регистр, DLL, dynamic linking, файл, программирование, меню, приложение, входной, pchar, строковый, входная строка, UDFS, утилита, база данных, запрос, CSTRING, БД, Disconnect, базы данных
InterBase имеет в своем арсенале весьма незначительный набор стандартных функций, которые можно использовать в запросах. Это связано с тем, что, во-первых, основным достоинством InterBase является малый объем сервера, и низкие требования к аппаратному обеспечению, что позволяет использовать InterBase практически на любом компьютере. А во-вторых, InterBase предоставляет очень привлекательную возможность для программиста создавать собственные функции ( UDF ) и подключать их к серверу, к конкретной базе данных. В рамках лекции мы рассмотрим и эту тему.
Стандартные функции InterBase
Стандартные функции InterBase представлены в таблице 23.1:
С большинством из этих функций мы уже сталкивались, разберем их синтаксис подробней, и опробуем на примерах. Для этого откроем утилиту IBConsole (сервер InterBase должен быть запущен), откроем в нем нашу базу First.gdb и запустим Interactive SQL. Примеры из запросов будем делать в этом окне.
AVG
Агрегатная функция, возвращает среднее арифметическое значение из множества значений в указанном числовом столбце или выражении. Если значение какого-либо столбца равняется NULL, оно автоматически исключается из вычисления, что предотвращает искажение возвращаемого результата.
Если число строк, возвращенных запросом SELECT равно 0, то AVG вернет NULL. Синтаксис:
AVG([ALL] <столбец|выражение> | DISTINCT <столбец|выражение>);
Если указан необязательный параметр ALL (по умолчанию), то среднее арифметическое значение вычисляется из всех столбцов или выражения. Если же указан параметр DISTINCT, то при вычислении будут исключены повторяющиеся значения. Пример:
SELECT AVG(Stoimost) FROM Tovar
COUNT
Функция подсчитывает и возвращает количество записей, удовлетворяющих условию поиска. Если условие не задано, функция возвращает количество всех записей набора данных. Синтаксис:
COUNT ([DISTINCT] <имя_поля>);
Если указан необязательный параметр DISTINCT, из вычисления будут исключены повторяющиеся значения. Примеры (выполняйте их по очереди, а не разом, иначе в окне Interactive SQL вы получите результат только последнего примера - каждая новая выборка будет перекрывать результат работы предыдущей выборки):
/*Количество всех записей:*/ SELECT COUNT(Nazvanie) FROM Tovar; /*То же самое, но исключив повторяющиеся значения:*/ SELECT COUNT(DISTINCT Stoimost) FROM Tovar; /*Количество всех записей, удовлетворяющих условию:*/ SELECT COUNT(Nazvanie) FROM Tovar WHERE Stoimost = 10;
MAX / MIN
Агрегатные функции, которые подсчитывают и возвращают максимальное или минимальное число из множества значений в указанном столбце или выражении. Если какое-то значение из множества равно NULL, оно исключается из вычислений. Если число записей в запросе равно нулю, функции возвращают NULL.
Если MAX / MIN применяются для строковых столбцов CHAR / VARCHAR, то максимум или минимум определяется в зависимости от символьного набора ( CHARACTER SET ) и порядка сортировки ( COLLATION ). Другими словами, функции возвращают максимальный или минимальный текст из всех строк, учитывая, что 'А' меньше, чем 'Я'.
MAX([ALL] <столбец|выражение> | DISTINCT <столбец|выражение>); MIN([ALL] <столбец|выражение> | DISTINCT <столбец|выражение>);
Примеры:
/*Максимальное и минимальное значения из числового столбца стоимости товаров:*/ SELECT MAX(Stoimost), MIN(Stoimost) FROM Tovar; /*Максимальное и минимальное значения из строкового столбца с названием товаров:*/ SELECT MAX(Nazvanie), MIN(Nazvanie) FROM Tovar;
SUM
Функция возвращает сумму всех значений из столбца таблицы или из выражения. Как и в предыдущих примерах, значения NULL автоматически исключаются из расчетов, а если количество строк в указанном наборе данных будет равно нулю, функция вернет NULL.
SUMM([ALL] <столбец|выражение> | DISTINCT <столбец|выражение>);
Пример:
/*Сумма всех значений из числового столбца стоимости товаров:*/ SELECT SUM(Stoimost) FROM Tovar;
CAST
Функция позволяет преобразовывать один тип данных в другой, или трактовать его, как другой тип данных. Функцию удобно использовать в запросах, которые смешивают данные разных типов в одном поле. Также CAST может использоваться в условиях поиска. Следует помнить, что типы данных должны соответствовать преобразованию. То есть, любое число можно превратить в строку, однако не любую строку можно превратить в число. Если строка содержит значение '123', она корректно преобразуется, и функция вернет правильный результат. Если строка содержит значение 'АБВ', то ее невозможно будет преобразовать в числовой тип, и функция вернет ошибку.
Типы данных, преобразуемые функцией CAST, представлены в таблице 23.2:
| Исходный тип данных | Возможный для преобразования тип данных |
|---|---|
| NUMERIC | CHAR, VARCHAR, DATE |
| CHAR, VARCHAR | NUMERIC, DATE |
| DATE | CHAR, VARCHAR, DATE |
Под типом данных NUMERIC подразумеваются целые и вещественные числовые типы.
CAST(<поле | значение> AS <тип_данных>)
Пример:
/*Вывод в одном поле объединенных значений строкового столбца Nazvanie */ /*и числового поля Stoimost, преобразованного в строку:*/ SELECT Nazvanie || ' - ' || CAST(Stoimost AS VARCHAR(25)) FROM Tovar;
В примере использован символ конкатенации (объединения) строк "||", вторая часть строки преобразуется функцией CAST из типа DOUBLE PRECISION.
UPPER
Преобразует все символы строки к верхнему регистру. Если набор символов и порядок сортировки поддерживают такое преобразование, функция UPPER вернет строку с символами в верхнем регистре. Иначе функция вернет строку без изменений.
Как уже говорилось в предыдущей лекции, функция корректно преобразует строки с русскими буквами только в том случае, если установлен набор символов для строки WIN1251, а порядок сортировки PXW_CYRL.
UPPER(<значение>);
Поскольку у нас в базе данных все символьные столбцы создавались с набором WIN1251 и порядком сортировки PXW_CYRL, то функция сработает правильно. Для наглядности в примере ниже мы выведем один и тот же столбец дважды, в первом случае не изменяя порядок сортировки, чтобы функция корректно перевела символы в верхний регистр. А во втором поле порядок сортировки изменим на WIN1251, чтобы функция не смогла сделать преобразование:
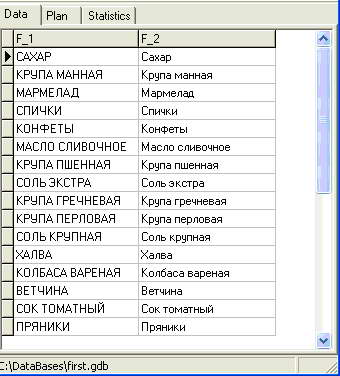
SELECT UPPER(Nazvanie), UPPER(Nazvanie COLLATE WIN1251) FROM Tovar;
В результате мы получим примерно такой набор данных:
Как видно из примера, текст с набором символов WIN1251 и порядком сортировки WIN1251 возвращается функцией UPPER без изменений.
GEN_ID
Функция является механизмом, увеличивающим значение указанного генератора на указанный шаг, и возвращающим текущее значение этого генератора. Если шаг равен 0, увеличения значения не происходит. Синтаксис:
CEN_ID(<генератор>, <шаг>);
Работу этой функции мы достаточно подробно рассмотрели в "Генераторы и триггеры. Реализация автоинкрементного поля" .
Евгений Медведев
Анна Зеленина
|
При вводе типов успешно сохраняется только 1я строчка. При попытке ввести второй тип вылезает сообщение об ошибке "project mymenu.exe raised exception class EOleException with message 'Microsoft Драйвер ODBC Paradox В операции должен использоваться обновляемый запрос'. |