Технология PLINQ
Технология PLINQ (Parallel LINQ) позволяет автоматически распараллеливать LINQ-запросы для обработки локальных структур данных.
IEnumerable<int> numbers = Enumerable.Range(1, 10000);
// Последовательный запрос
var seqQ = from n in numbers
where n % 2 == 0
select Math.Pow(n, 2);
// Объявляем запрос, который выполняется параллельно
var parQ = from n in numbers.AsParallel()
where n % 2 == 0
select Math.Pow(n, 2);
Метод AsParallel преобразуют исходную последовательность типа IEnumerable<TSource> в последовательность типа ParallelQuery<TSource>. Этот тип содержит методы-расширения с теми же именами, как и тип IEnumeralbe<T>, но предполагающие возможное параллельное исполнение на многопроцессорной системе. Другой способ выполнения параллельного запроса связан с использованием объекта ParallelEnumerable, который позволяет сформировать диапазон аналогично объекту Enumerable:
// Альтернативный вызов параллельных запросов
var parQ2 = from n in ParallelEnumerable.Range(1, 1000);
where n % 2 == 0
select Math.Pow(n, 2);
Основные этапы выполнения PLINQ-запроса: разделение данных по рабочим потокам, параллельное исполнение запросов на каждом потоке, агрегирование результатов в конечную последовательность.
numbers.AsParallel().Select(n => Math.Pow(n, 2)).ToArray()
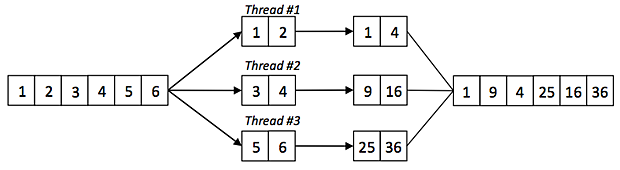
Удобство PLINQ заключается в том, что выполняя несколько запросов к последовательности, разделение элементов по потокам осуществляется по возможности вначале обработки. Элементы, попавшие в один поток при выполнении первого оператора, продолжают обрабатываться в этом потоке.
На рисунке изображено выполнение запроса
ParallelEnumerable.Range(1, 6).Where(n => n % 2 != 0).Select(n => n * n).ToArray();

Как и в случае шаблонов класса Parallel, для обработки элементов используются не только рабочие потоки пула, но и в первую очередь пользовательский поток, в котором осуществляется вызов запроса.
var threads = from n in ParallelEnumerable.Range(1, 1000) select Thread.CurrentThread.ManagedThreadId;
В этом запросе сохраняем номер потока, в котором происходит обработка элементов. Получаем, что половина элементов обрабатывается в основном потоке, другая половина в рабочем потоке пула.
Эффективность распараллеливания
Распараллеливание выполнения запроса связано с накладными расходами на разделение данных, агрегирование результатов. Многие закономерности при обработке PLINQ-запросов сохраняются: чем больше элементов, тем выше эффективность распараллеливания; чем больше вычислительная сложность обработки элемента, те выше эффективность распараллеливания.
Некоторые запросы обладают низкой эффективностью – последовательные аналоги работают быстрее, чем параллельные. Например, запросы, связанные со сравнением элементов (GroupBy, Distinct, Join и др.) разделяют элементы с помощью хэш-секционирования: перед распараллеливанием для каждого элементы вычисляет хэш-код, элементы с одинаковыми хэш-кодами объединяются для обработки в одном потоке. Сложная процедура разделения значительно снижает эффект распараллеливания дальнейшей обработки. Рассмотрим следующий фрагмент:
var threads = from n in ParallelEnumerable.Range(1, 1000) select Thread.CurrentThread.ManagedThreadId; var diff = threads.Distinct().ToArray(); int nThr = diff.Length;
Запрос threads сохраняет номер потока, в котором осуществляется обработка элемента. Для получения массива уникальных номеров diff используем оператор выявления различий Distinct и оператор преобразования в массив ToArray. Если изменить последовательность операторов Distinct и ToArray, то получим более производительный код:
var diff = threads.ToArray().Distinct();
Быстродействие выполнения второго варианта в 2 – 2.5 раза превышает параллельную версию. Разный порядок операторов приводит к тому, что метод Distinct применяется для массива, то есть типа IEnumerable<T>, а не для типа ParallelQuery<T>. Поэтому вызывается последовательная версия поиска различных элементов.
Запросы Take, TakeWhile, Skip, SkipWhile работают только с исходным порядком элементов. Например, запрос Take(5) отбирает первые пять элементов. Анализатор PLINQ не распараллеливает такие запросы. Также не распараллеливаются индексные перегрузки методов Select, Where, если предыдушие операторы привели к изменению индексов элементов в структуре.
var threads = ParallelEnumerable.Range(1, 1000) .Where(n => n % 2 == 0) .Select((int n, int i) => Thread.CurrentThread.ManagedThreadId); int nThr = threads.ToArray().Distinct().Count();
В этом фрагменте получаем число потоков, участвовавших в обработке элементов. Оператор Where выполняет отбор элементов и изменяет индексы элементов в структуре - двойка была вторым элементом, становится первым. Изменения индексов препятствует распараллеливанию индексной версии Select. Поэтому запрос не распараллеливается и число потоков nThr равно одному.
Для обязательного распараллеливания запроса вне зависимости от эффективности применяется модификатор WithExecutionMode с параметром ForceParallelism:
var threads = "abcdef".AsParallel() .WithExecutionMode(ParallelExecutionMode.ForceParallelism) .Where(c => true) .Take(3) .Select(c=> Thread.CurrentThread.ManagedThreadId); int nThr = threads.ToArray().Distinct().Count();
Несмотря на то, что оператор Where фактически пропускает все элементы, анализатор PLINQ-запросов по умолчанию не распараллеливал бы выполнение запроса. Но режим ForceParallelism позволяет включить распараллеливание, например, в отладочных целях.
Если какая-то часть запроса обязательно должна выполняться последовательно, необходимо выполнить обратное преобразование ParallelEnumerable в IEnumerable с помощью метода AsSequential. Такое преобразование может быть полезным, если в запросе используются потоконебезопасные методы, параллельное выполнение которых может привести к ошибкам.
var q = data.AsParallel() .Select(item => DoSome(item)).Where(item => IsValid(item)) .AsSequential().Select(item => DoSomeSeq(item)) .ToArray();
Первые два оператора Select и Where выполняются параллельно. Перед вызовом последнего оператора элементы собираются в одну последовательность.
При выполнении LINQ-запросов элементы обрабатываются последовательно в процессе перебора, отсутствует какая-либо буферизация результатов. Технология PLINQ предоставляет три режима буферизации.
По умолчанию используется авто-буферизация (AutoBuffered) - объем буфера для вычисления результатов определяется исполняющей средой.
var numbers = ParallelEnumerable.Range(1, 10);
var query = numbers.Select(n =>
{
Thread.Sleep(500);
Console.WriteLine("Prepare item {0}, thread {1}", n, Thread.CurrentThread.ManagedThreadId);
return n;
});
foreach(int i in query)
Console.WriteLine("Got item {0}", i);
При обращении к первому элементу запроса осуществляется параллельная обработка части элементов.
Prepare item 1, thread 10 Prepare item 6, thread 11 Prepare item 2, thread 10 Prepare item 7, thread 11 Prepare item 3, thread 10 Prepare item 8, thread 11 Prepare item 4, thread 10 Prepare item 9, thread 11 Prepare item 5, thread 10 Got item 1 Got item 2 Got item 3 Got item 4 Got item 5 Prepare item 10, thread 11 Got item 6 Got item 7 Got item 8 Got item 9 Got item 10
Так как число элементов достаточно небольшое, то практически все элементы были обработаны при первом обращении к запросу.
Полная буферизация (fully-buffered) позволяет выполнить запрос полностью до предоставления результатов вне зависимости от числа элементов.
var numbers = ParallelEnumerable.Range(1, 10);
var q = numbers
.WithMergeOptions(ParallelMergeOptions.FullyBuffered)
{
Thread.Sleep(500);
Console.WriteLine("Prepare item {0}, thread {1}", n, Thread.CurrentThread.ManagedThreadId);
return n;
});
foreach(int i in query)
Console.WriteLine("Got item {0}", i);
Обращение к первому элементу инициирует параллельную обработку всех элементов:
Prepare item 6, thread 10 Prepare item 1, thread 11 Prepare item 7, thread 10 Prepare item 2, thread 11 Prepare item 8, thread 10 Prepare item 3, thread 11 Prepare item 9, thread 10 Prepare item 4, thread 11 Prepare item 10, thread 10 Prepare item 5, thread 11 Got item 1 Got item 2 Got item 3 Got item 4 Got item 5 Got item 6 Got item 7 Got item 8 Got item 9 Got item 10
Режим с полной буферизацией обладает худшим временем получения первого элемента, но получение всей результирующей последовательности может занимать меньше времени, чем другие режимы.
Третий режим не использует буферизацию.
var numbers = ParallelEnumerable.Range(1, 10);
var q = numbers
.WithMergeOptions(ParallelMergeOptions.NotBuffered)
{
Thread.Sleep(500);
Console.WriteLine("Prepare item {0}, thread {1}", n, Thread.CurrentThread.ManagedThreadId);
return n;
});
foreach(int i in query)
Console.WriteLine("Got item {0}", i);
Элементы вычисляются по мере обращения:
Prepare item 1, thread 6 Got item 1 Prepare item 6, thread 11 Got item 6 Prepare item 2, thread 6 Got item 2 Prepare item 7, thread 11 Got item 7 Prepare item 3, thread 6 Got item 3 Prepare item 8, thread 11 Got item 8 Prepare item 4, thread 6 Got item 4 Prepare item 9, thread 11 Got item 9 Prepare item 5, thread 6 Got item 5 Prepare item 10, thread 11 Got item 10