|
Reference = add reference, в висуал студия 2010 не могу найти в вкладке Solution Explorer, Microsoft.Xna.Framework. Его нету. |
Спонсор: Microsoft
Вы можете этот курс.
Опубликован: 28.04.2009 | Доступ: свободный | Студентов: 1840 / 107 | Оценка: 4.36 / 4.40 | Длительность: 16:40:00
Темы: Компьютерная графика, Программирование, Игры
Специальности: Программист
Теги:
Лекция 5:
Вершинные шейдеры
Ничего не напоминает? Правильно, это разложение функции cos(x) в ряд Тейлора до члена десятой степени:
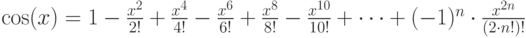
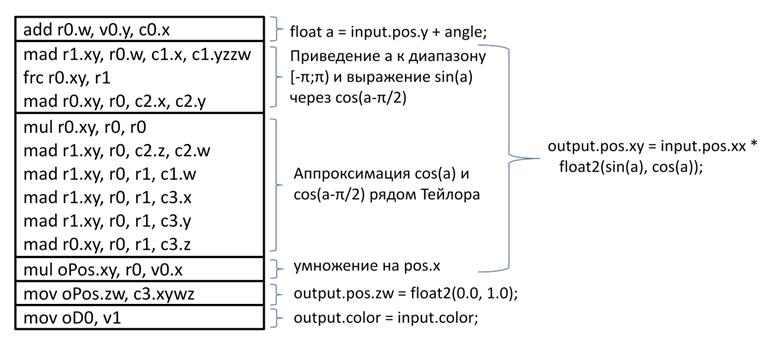
Таким образом, ассемблерные команды с пятой по десятую вычисляют косинус угла. Соответственно, после выполнения десятой команды в компоненте y регистра r0 находится косинус угла, а в компоненте x -синус угла (как вы помните 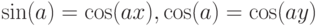 ). При этом векторные регистры вершинного процессора позволили компилятору HLSL параллельно рассчитать значения обоих тригонометрических функций.
). При этом векторные регистры вершинного процессора позволили компилятору HLSL параллельно рассчитать значения обоих тригонометрических функций.
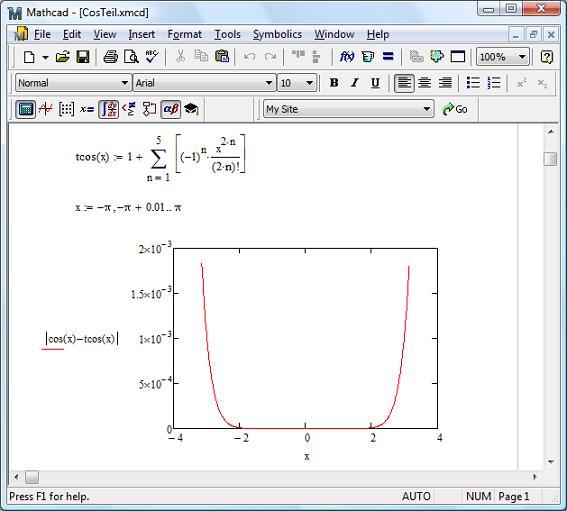
Точность вычисления cos(x)
Приблизительную оценку аппроксимации функции cos рядом Тейлора из пяти членов можно легко выполнить в том же MathCad, построив график модуля разницы между суммой пяти членов ряда Тейлора и встроенной функцией cos (рисунок 5.19). Как видно, по мере приближения модуля угла к 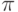 абсолютная погрешность стремительно растет, достигая при угле равном величины порядка
абсолютная погрешность стремительно растет, достигая при угле равном величины порядка  . Если такая точность недостаточна для ваших задач, можно попробовать уменьшить модуль значения аргумента cos, воспользовавшись тождеством
. Если такая точность недостаточна для ваших задач, можно попробовать уменьшить модуль значения аргумента cos, воспользовавшись тождеством  .
.
Остальной код весьма тривиален. Одиннадцатая команда умножает полученные значения синуса и косинуса на расстояние вершины до центра и записывает результат в компоненты x и y регистра oPos . Двенадцатая команда дописывает в компоненты z и w этого регистра значение 0 и 1. И, наконец, тринадцатая команда записывает в выходной регистр цвета цвет текущей вершины из регистра v1 .
Рисунок 5.20 резюмирует весь вышеприведенный анализ кода, устанавливая соответствие между ассемблерным и HLSL кодом шейдера. Однако следует ясно осознавать, что это всего лишь код для виртуального вершинного процессора, который будет скомпилирован драйвером видеокарты в код для конкретного реального вершинного процессора. А архитектура физического вершинного процессора может иметь множество нюансов. Например, все вершинные процессоры современных видеокарт являются суперскалярными и могут запускать несколько ассемблерных инструкций за такт, в частности вершинные процессоры R3xx и R4xx могут выполнить за один такт одну векторную инструкцию над 1-4 компонентным вектором и одну скалярную инструкцию (если они, разумеется, не зависят друг от друга по данным). Поэтому оптимизирующий компилятор драйвера видеокарты может переставлять инструкции местами для достижения большего параллелизма.
Кроме того, многие вершинные процессоры имеют расширенный набор инструкций по сравнению со спецификаций Vertex Shader 1.1 . Так вершинные процессоры R2xx могут аппаратно вычислять дробную часть числа, соответственно если драйвер видеокарты в процессе компиляции эффекта в микрокод вершинного процессора обнаружит последовательности инструкций Vertex Shader 1.1 , соответствующих макросу frc , то он заменит их одной встроенной командой. Другой пример: видеокарты R4xx и выше содержат инструкцию аппаратного вычисления синуса и косинуса угла в диапазоне  поэтому драйвер автоматически подменит разложение в ряд Тейлора вызовом данных встроенных функций.
поэтому драйвер автоматически подменит разложение в ряд Тейлора вызовом данных встроенных функций.
Тем не менее, оптимизирующий компилятор драйвера не всесилен, поэтому чем качественнее код Vertex Shader 1.1 и чем меньше явных атавизмов он содержит (вроде вычисления скалярного произведения серией инструкций add и mul вместо единственной инструкции dp4 ), тем вероятней драйвер видеокарты сможет сгенерировать оптимальный код.
Таким образом, при написании эффекта в FX Composer 2.0 в качестве главного критерия оптимальности шейдера должен выступать не промежуточный код на языке Vertex Shader 1.1 , а количество тактов графического процессора, затрачиваемых на обработку одной вершины. В частности на видеокарте GeForce 7800 GTX обработка одной вершины нашим вершинным шейдером занимает 20 тактов, а всего за одну секунду ее вершинный процессор теоретически может обработать 172.000.000 вершин. Анализ ассемблерного кода тоже весьма полезен, но в первую очередь как средство поиска проблемных мест в коде эффекта, нуждающегося в оптимизации. Но при этом не следует забывать об алгоритмической оптимизации приложения на макроуровне, иначе зациклившись на оптимизации нескольких локальных выражений вы рискуете не увидеть за деревьями леса. В частности, в следующем практическом упражнении демонстрируется, как использование знаний школьного курса тригонометрии позволяет значительно повысить производител ьность приложения.
Практическое упражнение №5.1
Вершинный шейдер, выполняющий вращение диска, рассчитывает для каждой вершины значение тригометрических функций sin и cos . Следовательно, при визуализации множества дисков, содержащих тысячи вершин, нам придется рассчитать для каждого кадра значения тысяч тригонометрических функций. Учитывая, что вычисление тригонометрической функции является весьма трудоемким процессом, данное обстоятельство может негативным образом влиять на производительность.
Примечание
Графические процессоры G8x и R6xx содержат массив универсальных процессоров, которые могут выполнять код как вершинных, так и пиксельных шейдеров. Баланс между процессорами, выполняющих код вершинного шейдера и процессорами, выполняющих пиксельный шейдер, регулируется динамически в зависимости от загруженности соответствующих блоков видеокарты. При этом неоправданно сложный вершинный шейдер неминуемо "оттянет на себя " дополнительное количество универсальных процессоров и замедлит выполнение пиксельных шейдеров.
Обратим внимание на один нюанс. Аргумент функций sin и cos является уникальным для каждой вершины, причем он все время меняется. Но формируется он путем сложения двух компонентов:
float a = input.pos.y + angle;
При этом значение input.pos.y является постоянным для каждой вершины, а значение angle хотя и изменяется, но является общим для всех вершин. Таким образом, значения sin(input.pos.y) и cos(input.pos.y) вполне можно было бы рассчитать заранее в обработчике события Load и передавать в вершинный шейдер как координаты вершины, a sin(angle) и cos(angle) как входные параметры вершинного шейдера. Чтобы это стало возможным, необходимо выразить косинус суммы и синус суммы через синусы и косинусы слагаемых, воспользовавшись известными формулами из школьного курса тригонометрии:
 |
( 5.5) |
Задание: проведите оптимизацию эффекта примера Ch05\Ex06 , реализовав вычисление тригометрических функций посредством выражения 5.5, и выноса большей части бессмысленных трудоемких расчетов за пределы вершинного шейдера. Используя NVIDIA FX Composer 2.0 , оцените потенциальный прирост производительности (который, скорее всего, окажется более чем трехкратным).
Подсказка
Имея вектор с предварительно рассчитанными значениями тригометрических функций, выражение 5.5 можно вычислить всего при помощи двух действий: по парного перемножения значения тригометрических функций и последующего суммирования результатов. Но так как вторая формула использует вычитание, для реализации ее через сумму вам потребуется передать в эффект значение -sin (angle) . При этом чтобы облегчить работу оптимизирующему компилятору HLSL, входные параметры sin (angle), cos (angle), -sin (angle) желательно передавать в шейдер как один трехмерный вектор.
Если у вас возникнут трудности при выполнении данного задания, вы всегда можете ознакомиться с готовым решением, которое можно найти в каталоге \Examples\Ch05\Ex07 .
5.5.2. Оператор if языка HLSL
Следующий этап - перенос расчета полета искр в вершенный шейдер - является гораздо более сложным и запутанным, поэтому, чтобы восстановить силы мы сделаем небольшой привал и поговорим об особенностях оператора if языка HLSL применительно к профилю vs11 .
Подобно подавляющему большинству языков программирования HLSL содержит конструкцию выбора if :
if (логическое условие)
{
блок 1
}
else
{
блок 2
}В принципе, на этом раздел можно было бы окончить, если бы не одна маленький нюанс: язык Vertex Shader 1.1 не содержит команд для управления ходом выполнения программы (условные переходы, циклы и т.п.). Эта особенность имеет далеко идущие последствия. Когда в программе на C# используется конструкцию if , то центральный процессор будет каждый раз выполнять только одну из ветвей блока if , что позволяет значительно сократить объем вычислений и повысить производительность 19Следует отметить, что современные процессоры с длинными конвейерами достаточно болезненно реагируют на хаотичные непредсказуемые условные переходы, поэтому при использовании оператора if следует соблюдать осторожность 85. А вот компилятор HLSL при использовании профиля vs11 вынужден эмулировать условную конструкцию, генерируя код, выполняющий все ветви оператора с последующим комбинированием результатов. С оответственно, в HLSL применение оператора if в принципе не может поднять производительность приложения.
В качестве примера попробуем "оптимизировать " вершинный шейдер, выполняющий закраску диска с использованием оператора if . Координаты вершины, распложенной в центре диска всегда неизменны, поэтому многие начинающие разработчики поддаются соблазну попытаться ускорить выполнение эффекта, отказавшись от трудоемкого расчета координат центральной вершины (листинг 5.13).
// Полный текст эффекта и готовое приложение находятся в каталоге Examples\Ch05\Ex08
VertexOutput MainVS(VertexInput input)
{
VertexOutput output;
if (input.pos.x != 0)
{
// Если вершина не является центральной, рассчитываем
ее координаты float a = input.pos.y + angle;
output.pos.xy = input.pos.xx \cdot float2(sin(a), cos(a));
}
else
// Если вершина расположена в центре круга, то ее
координаты всегда равны (0.0, 0.0) output.pos.xy = float2(0.0, 0.0);
output.pos.zw = float2(0.0, 1.0);
output.color = input.color;
return output; } Ниже приведен отчет FX Composer с
ассемблерным листингом
кода:
// Generated by Microsoft (R) D3DX9 Shader Compiler 9.12.589.0000
//
// Parameters:
//
// float angle;
//
//
// Registers:
//
// Name Reg Size
// ----
// angle c0 1
//
//
// Default values:
//
// angle
// c0 = { 0, 0, 0, 0 };
//
vs_1_1
def c1, 0.159154937, 0.25, 0.5, -0.00138883968
def c2, 6.28318548, -3.14159274, -2.52398507e-007, 2.47609005e-005
def c3, 0.0416666418, -0.5, 1, 0
dcl_position v0
dcl_color v1
add r0.w, v0.y, c0.x
mad r1.xy, r0.w, c1.x, c1.yzzw
frc r0.xy, r1
mad r0.xy, r0, c2.x, c2.y
mul r0.xy, r0, r0
mad r1.xy, r0, c2.z, c2.w
mad r1.xy, r0, r1, c1.w
mad r1.xy, r0, r1, c3.x
mad r1.xy, r0, r1, c3.y
mad r0.xy, r0, r1, c3.z
mul r0.w, v0.x, v0.x
mul r0.xy, r0, v0.x
slt r0.w, -r0.w, r0.w
mul oPos.xy, r0, r0.w
mov oPos.zw, c3.xywz
mov oD0, v1
// approximately 18 instruction slots used
Листинг
5.13.
Для начала отметим, что количество ассемблерных команд возросло с 13 до 16, число микроинструкций с 15 до 18, а время выполнения шейдера с 20 до 21 тактов. Как видите, увеличение числа инструкций на 3 увеличило время выполнения шейдера всего на один такт. Эта "аномалия " имеет простое объяснение: каждый вершинный процессор G7x имеет VLIW - архитектуру 20Very Long Instruction Word (VLIW) – архитектурная особенность процессора с явным параллелизмом, к которых команды состоят из микроинструкций, определяющих операцию для каждого функционального устройства процессора. Примером процессора с VLIW-архитектурой является Intel Itanium и содержит два исполнительных блока 21В действительности исполнительных блоков несколько больше, но ограниченная функциональность Vertex Shader 1.1 позволяет задействовать только эти два блока.: один блок векторных операций ( add, mul, madd и т.п.) и один блок скалярных операций ( rcp, sin, cos и т.п.). Следовательно, в идеальных условиях при отсутствии зависимостей по данным вершинный процессор G7x может за один такт запустить на выполнение одну векторную и скалярную операцию. Поэтому логично предположить, что драйвер NVIDIA при компиляции шейдера в микрокод вершинного процессора успешно спарил добавочные инструкции с остальными инструкциями шейдера. Хотя, конечно, нельзя исключить и влияние недокументированных особенностей микроархитектуры G7x . Таким образом, мы еще раз убедились, что количество инструкций без учета нюансов архитектуры вершинного процессора не может являться универсальным критерием производительности.
Перейдем к собственно ассемблерному коду вершинного шейдера. Первые 10 инструкций хорошо вам знакомы - они вычисляют сумму float a = input.pos.y + angle и значения тригометрических функций путем разложения в ряд Тейлора. По окончанию выполнения десятой команды в r0.x находится значение sin(a), а в r0.y значение cos(a).
Андрей Леонов