Введение в архитектуру ввода/вывода встроенных систем
Программное обеспечения передачи данных в порты В/В
Когда используется операционная система, низкоуровневый код драйвера устройства обычно взаимодействует с портами В/В, и приложения пользователей вызывают эти драйверы устройств с помощью API OC. Для разработки кода драйвера устройства большинство компиляторов C/C++ позволяют использовать встраиваемый язык ассемблера. К сожалению, использование языка ассемблера означает, что код не будет переноситься на другой процессор. Это также затрудняет понимание кода для других разработчиков.
На процессорах X86 должны использоваться две специальные машинные инструкции для передачи данных в порты В/В. Инструкция IN считывает данные из порта В/В, а инструкция OUT записывает данные в порт В/В. Для этих инструкций X86 16-битный регистр адреса В/В (DX) является одним из операндов, а 8-битный регистр (AL), который содержит значение данных является другим операндом. Это единственные две инструкции, которые будут генерировать циклы шины для чтения и записи В/В. Пример встроенного в C/C++ кода языка ассемблера X86 показан в примере 2.1. Ключевое слово _asm указывает на язык ассемблера.
//Процедура ввода В/В X86 // Процедура вывода В/В X86 I/
__asm{ __asm{
mov dx,IO_address mov dx,IO_address
in al, dx mov al,IO_data
mov IO_data,al out dx, al
} }
2.1.
Встроенные в C/C++ инструкции языка ассемблера X86 для передач ввода и вывода порта В/В
На многих процессорах эти инструкции В/В являются также привилегированными и могут перехватываться в оборудовании с помощью задания бита режима процессора, чтобы запретить пользователям непосредственно выполнять В/В вместо использования вызовов API ОС для выполнения В/В. Традиционные настольные операционные системы Windows используют этот бит режима, чтобы сделать инструкции В/В привилегированными, но многие встроенные операционные системы, включая Windows Embedded CE этого не делают. Некоторые RISC-процессоры резервируют специальный диапазон адресов в памяти для устройств В/В (отображенный в память В/В) и затем используют обычные инструкции Load и Store для переноса данных в устройства В/В. Кэширование данных порта В/В отображенной памяти должно быть отключено. C# не допускает встраивание языка ассемблера непосредственно, но может вызывать процедуры C/C++ в динамически подключаемой библиотеке (DLL), используя процедуру, называемую P/invoke.
Для разработки кода драйвера устройства большинство компиляторов C/C++ имеют специальные вызовы функций, которые могут читать и записывать в порты В/В. В Windows Embedded CE, использующей CE Device Driver Kit (CEDDK), две такие функции C предоставлены для 8-битных портов В/В. Функция WRITE_PORT_UCHAR(адрес В/В, данные) записывает значение данных в порт В/В. Функция READ_PORT_UCHAR(адрес В/В) возвращает значение данных, прочитанное из порта В/В. В файле исходного кода требуется заголовочный файл CEDDK.h и код должен быть скомпонован с библиотекой CEDDK.lib.
Эти вызовы функций обычно находятся только в низкоуровневых драйверах устройств В/В. При таком подходе код будет легко переноситься на другие процессоры и будет легче для чтения и понимания (особенно для тех, кто не знает язык ассемблера процессора). C# не имеет таких функций, но может вызывать функции C/C++, которые определены в библиотеке *.dll, с помощью специального средства [DLLIMPORT] P/invoke.
Пример шины микропроцессора второго поколения
Так как ограничения полосы пропускания и размера адресации памяти шин первого поколения, таких как ISA, стали очевидны, были предложены несколько новых стандартов шин. В начале 1990-х компания Intel представила шину PCI (Взаимосвязь Периферийных Компонентов). Эта шина стала наиболее широко используемым стандартом и сегодня развитием стандарта PCI занимается организация PCI Special Interest Group. PCI является синхронной шиной, вся передача данных по которой происходит согласно частоте шины PCI. В начале частота шины PCI была 33 Mhz. Более новые системы PCI-X могут иметь частоту 66, 133, 266 и 533 MHz. Длину, нагрузку и импеданс сигнальных линий шины PCI необходимо тщательно контролировать, чтобы поддерживать эти высокие частоты. К одной шине PCI может быть присоединено только несколько устройств. Сигналы PCI являются даже слишком быстрыми, чтобы правильно функционировать при подключении устройств на студенческой панели для прототипов с длинными соединительными проводами. PCI поддерживает уровни логики 5V и 3.3V. PC/104-Plus является версией платы PCI для стоек, используемой в некоторых встроенных устройствах.
PCI использует 32-битную мультиплексную шину адреса и данных, AD[31:0]. В цикле шины PCI, во время первого такта линии AD содержат данные. Это сокращает число контактов, необходимых на разъемах и снижает стоимость. Это также означает, что целевые устройства должны иметь регистр для хранения адреса и значений команды шины для всего цикла шины и машины состояний, которая знает, какой происходит такт (в отличие от простого интерфейса шины для целей ISA, которым требуется только комбинационная логика (т.е., вентили)).
PCI поддерживает также пересылку пакетов данных. В пакете PCI начальный адрес посылается во время первого такта (фаза адреса), а данные пересылаются из последовательных адресов (фаза данных) при каждом новом такте.
Сигнал кадра PCI (FRAME) сообщает о новой фазе адреса. Посылается только один начальный адрес, поэтому оборудование целевого интерфейса должно увеличивать сохраненное значение адреса.
Данные пересылаются между инициатором и целью. Инициатор управляет сигналами активации команды/байта PCI (C/BE[3:0]) во время фазы адреса для сообщения о типе передачи (чтение памяти, запись памяти, чтение В/В, запись В/В, и т.д.) как показано в таблице 2.2. Во время фазы данных сигналы C/BE[3:0] служат в качестве активации байта для указания, какие байты данных являются действительными. Как инициатор, так и цель могут вставлять состояния ожидания (добавляют дополнительные такты для замедления) в передачу данных, снимая контроль сигналов PCI инициатор готов (IRDY) и цель готова (TRDY).
| Команда шины PCI | C/BE |
|---|---|
| подтверждение прерывания | 0000 |
| специальный цикл | 0001 |
| чтение В/В | 0010 |
| запись В/В | 0011 |
| зарезервировано | 0100 |
| зарезервировано | 0101 |
| чтение памяти | 0110 |
| запись памяти | 0111 |
| зарезервировано | 1000 |
| зарезервировано | 1001 |
| чтение конфигурации | 1010 |
| запись конфигурации | 1011 |
| многократное чтение записи | 1100 |
| цикл двойного адреса | 1101 |
| линия чтения памяти | 1110 |
| чтение памяти и аннулирование | 1111 |
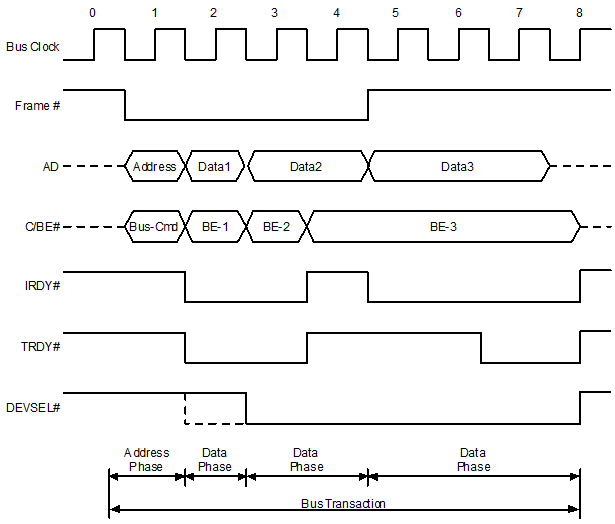
| Такт | Описание операции чтения PCI |
|---|---|
| 0 | Шина простаивает |
| 1 | Инициатор задает FRAME низким, помещая адрес на линии адреса/данных (AD), и команду шины (чтение) на линии команды/активации байта (C/BE) (фаза адреса). |
| 2 | Инициатор определяет три состояния адреса и ожидает от цели возврата значения данных, активируя свои драйверы трех состояний. Низкое состояние Device Select (DEVSEL) указывает, что целевое устройство декодировало свой диапазон адресов и отвечает на команду. Цель переводит TRDY в высокое состояние, чтобы сообщить, что цели требуется еще один такт, чтобы переслать данные (фаза данных) |
| 3 | Цель пересылает значение данных и задает для готовности цели (TRDY) низкое состояние, чтобы сообщить, что данные действительны. Когда оба сигнала IRDY и TRDY имеют состояние низкое, происходит передача данных. |
| 4 | Цель задает для TRDY состояние высокое, чтобы сообщить, что ей требуется дополнительный такт для следующей передачи данных. |
| 5 | Происходит вторая передача данных, когда оба сигнала TRDY и IRDY находятся в низком состоянии. Инициатор сохраняет данные цели. |
| 6 | Цель направляет значение данных, а инициатор запрашивает дополнительный такт, задавая состояние сигнала IRDY высоким. |
| 7 | Инициатор задает сигнал низким, чтобы завершить третью передачу данных. Инициатор сохраняет значение данных цели. Инициатор направляет высокий сигнал FRAME в конце фазы данных. |
| 8 | Все сигналы шины прошли через три состояния или были направлены в неактивное состояние. |
| Такт | Описание операции записи PCI |
|---|---|
| 0 | Шина простаивает |
| 1 | Инициатор задает сигнал FRAME низким, помещает адрес на линии адреса /данных (AD), и команду шины (запись) на линии команды /активации байта (C/BE) (фаза адреса). |
| 2 | Инициатор помещает данные на линии AD и активирует байт на линиях C/BE, низкий сигнал выбора устройства (DEVSEL) указывает, что целевое устройство декодировало свой диапазон адресов, и он отвечает команде. Когда оба сигнала IRDY и TRDY будут низкими, цель сохраняет данные (фаза данных). |
| 3 | Инициатор направляет новые данные и активирует байт. Когда оба сигнала IRDY и TRDY будут низкими, происходит передача данных и цель сохраняет данные. |
| 4 | Инициатор задает сигнал IRDY высоким, а цель задает TRDY запрашивающим дополнительный такт. |
| 5 | Инициатор направляет новые данные и активирует байт и задает сигнал IRDY низким. Инициатор задает сигнал FRAME высоким, указывая на окончание передачи данных. |
| 6 | Цель направляет значение данных, а инициатор запрашивает дополнительный такт для задания сигнала IRDY высоким. |
| 7 | Инициатор задает сигнал IRDY низким, чтобы завершить третью передачу данных. Цель сохраняет значение данных. |
| 8 | Все сигналы шины прошли через три состояния или были направлены в неактивное состояние. |
Синхронизация по времени шины PCI для пакетного цикла часто представляется в формате вида 3-2-2-2. Это означает, что первая передача данных занимает 3 такта (включая фазу адреса), а три следующие передачи данных занимают каждая по 2 такта. Шина PCI поддерживает также прерывания и контроллеры DMA (сигналы INTx, REQ, и GNT). Стандарт CardBus для небольших подключаемых модулей получен из сигналов шины PCI.
В последнее время графические платы начали потреблять большую часть доступной полосы пропускания шины PCI, поэтому они были перенесены на новую шину Accelerated Graphics Port (AGP). AGP основывается на сигналах шины PCI. Так как AGP соединяется только с одним устройством, графической платой, то технически она является портом, а не шиной. AGP 2X, 4X, и 8X содержат дополнительные сигналы и фазы синхронизации, которые увеличивают эффективную частоту работы.
Программное обеспечение для устройств PCI
Для поддержки автоматической конфигурации оборудования, каждое устройство PCI содержит область конфигурации, размером 256 байтов. При включении питания устройства PCI могут самостоятельно сообщать информацию о производителе и типе устройства, чтобы помочь операционной системе найти и загрузить правильные драйверы устройств. Устройства PCI, которые отображают в память и адресное пространство В/В, можно запрограммировать для ответа на различные базовые адреса и прерывания. Это позволяет программному обеспечению операционной системы загружать драйверы и присваивать адреса и прерывания автоматически во время включения питания. Перечисление является термином, который используется для описания этого процесса. Это исключает необходимость устанавливаемых вручную перемычек и переключателей. Операционная система обычно предоставляет драйвер, который обрабатывает перечисление, но драйверы устройств по прежнему нужны для каждого устройства PCI на шине.
Пример шины микропроцессора третьего поколения
Недавно была представлена шина PCI Express, которая предоставляет еще большую полосу пропускания, чем PCI. Увеличение полосы пропускания выше уровней PCI, за счет создания большого числа плотно упакованных высокоскоростных параллельных линий соединения шины на современных монтажных платах было больше невозможно, но это можно было сделать с помощью нового поколения высокоскоростных драйверов, когда используется меньшее количество линий, и длина, нагрузка, перекрестные помехи, и окончание каждой линии тщательно контролируется. В PCI Express используется небольшое число высокоскоростных последовательных линий для передачи сигналов шины PCI. Скорость передачи данных высокоскоростных последовательных линий PCI Express лежат в диапазоне от 2.5 до 10 Гбайт/сек. Для большей полосы пропускания несколько высокоскоростных последовательных линий можно объединять в группу для соединения с устройством (называемую lane (тропинка) в PCI Express). Регистры смещения в интерфейсе PCI каждого устройства преобразуют сигналы из последовательного в параллельный. Так как PCI Express пересылает те же самые сигналы PCI, работа программного обеспечения PCI не изменяется. Новый стандарт ExpressCard для небольших подключаемых модулей основывается на PCI Express. PCI может поддерживать уровни логики 5V и 3.3V. Примерно в это же время стандарт PCI также был обновлен для поддержки более высокой частоты шины.
Существует ряд других стандартов высокоскоростных шин, включая HyperTransport компании AMD, RapidIO компании Freescale, и FlexIO компании Rambus. Многие используют теперь низковольтные дифференциальные сигналы на сигналах шины.
Согласование по времени, длина шины, нагрузка (число соединенных с шиной устройств), и окончание все являются критически важными на современных шинах микропроцессоров, и необходимо понимать и детально проверять требования при проектировании нового оборудования, и даже при прокладке трассировки печатной платы для шины. Многие шины требуют внешнего резистора на каждой сигнальной линии для правильного окончания. Полные спецификации стандартов шин могут занимать несколько сотен страниц и доступны для разработчиков оборудования из различных источников. Полностью совместимый интерфейс PCI требует более десяти тысяч логических вентилей. Базовый дизайн интеллектуальной собственности PCI также доступен у ряда поставщиков для разработчиков оборудования для использования в новых конструкциях.