
|
Здравствуйте, прошел курс "Концептуальное проектирование систем в AnyLogic и GPSS World". Можно ли получить по нему сертификат? У нас в институте требуют сертификаты для создания портфолио. |
Опубликован: 15.02.2013 | Доступ: свободный | Студентов: 256 / 0 | Длительность: 16:52:00
ISBN: 978-5-9556-0146-5
Темы: САПР, Программное обеспечение
Специальности: Архитектор программного обеспечения, Разработчик аппаратуры
Теги:
Лекция 2:
Модель обработки запросов сервером
Ключевые слова: GPSS, прямой, Блок-диаграмма, среднее время, производительность, коэффициенты, время выполнения
Модель в GPSS World
При имитационном моделировании с использованием специальных инструментальных средств, например, GPSS World, в общем случае решаются две задачи. Назовем их прямой и обратной.
Прямая задача заключается в нахождении оценки математического ожидания какого-либо показателя моделируемой системы при заданном времени ее функционирования.
Обратная задача состоит в определении оценки математического ожидания времени функционирования системы, за которое какой-либо её показатель достигает заданного значения.
Решение этих задач, особенно обратной задачи, имеет свои особенности. Рассмотрим эти особенности далее на примере. Начнём построение GPSS-моделей с прямой задачи.
Решение прямой задачи
Постановка задачи
Сервер обрабатывает запросы, поступающие с автоматизированных рабочих мест (АРМ) с интервалами, распределенными по показательному закону со средним значением T1 = 2 мин. Сервер имеет входной буфер ёмкостью 5 запросов.
Вычислительная сложность запросов подчинена нормальному закону с математическим ожиданием  и среднеквадратическим отклонением
и среднеквадратическим отклонением 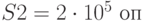 . Производительность сервера
. Производительность сервера 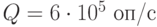 . В случае полной занятости входного буфера поступающий запрос теряется.
. В случае полной занятости входного буфера поступающий запрос теряется.
Построить имитационную модель обработки запросов сервером для определения оценки математического ожидания количества запросов (дальше - количества запросов), обработанных сервером за время функционирования T = 1 час, и оценки математического ожидания вероятности обработки запросов (дальше - вероятности обработки запросов).
Уяснение задачи моделирования
Сервер представляет собой однофазную систему массового обслуживания разомкнутого типа с ожиданием и с отказами.
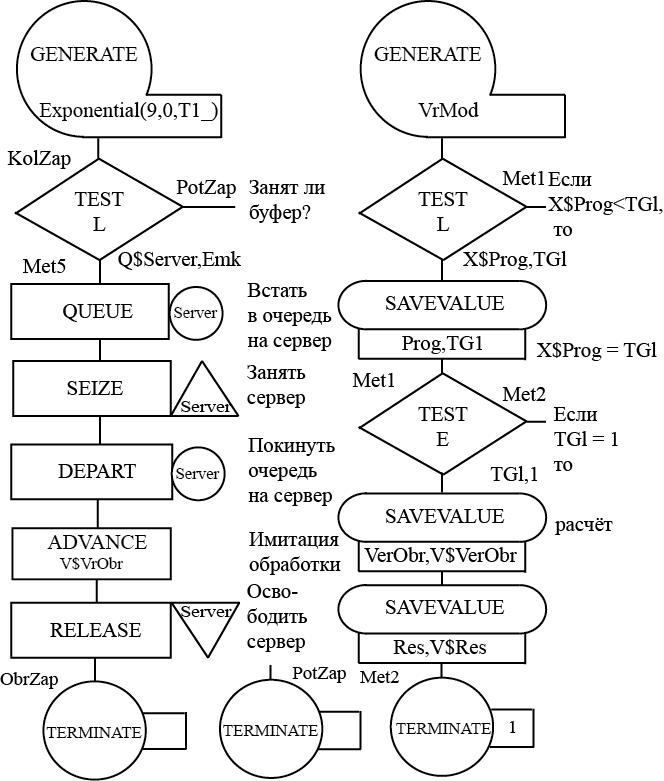
В модели для имитации источника запросов следует использовать блок GENERATE, для имитации сервера как одноканального устройства - блоки SEIZE и RELEASE, для имитации буфера - QUEUE и DEPART, обработки запросов - ADVANCE.
В модели должны быть следующие элементы:
- задание исходных данных;
- описание арифметических выражений;
- сегмент имитации поступления и обработки запросов;
- сегмент задания времени моделирования и расчета результатов моделирования.
Серверу дадим имя Server. Для вывода из модели транзактов, имитирующих обработанные и потерянные запросы, используем блоки TERMINATE с метками ObrZap и PotZap соответственно. Для счета количества всех запросов используем метку KolZap.
Выберем масштаб: 1 единице масштабного времени соответствует 1 с. Так как среднее значение интервалов поступления запросов T1 = 2 мин, то теперь это будет 120 ед. мод. времени.
Рассчитаем количество прогонов, которые нужно выполнить в каждом наблюдении, т. е. проведем так называемое тактическое планирование эксперимента. Пусть результаты моделирования (вероятность обработки запросов) нужно получить с доверительной вероятностью 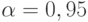 и точностью
и точностью 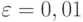 . Расчет проведем для худшего случая, т. е. при вероятности
. Расчет проведем для худшего случая, т. е. при вероятности 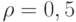 , так как до эксперимента
, так как до эксперимента неизвестно:
неизвестно:

Блок-диаграмма модели
Построим блок-диаграмму модели для решения прямой задачи, т. е. сегмент имитации поступления и обработки запросов и сегмент задания времени моделирования и расчета результатов моделирования (Рис. 1.1).
Блок-диаграмма представляет собой набор стандартных блоков. Она строится так. Из множества блоков выбирают нужные, и далее выстраивают их в диаграмму для того, чтобы в процессе функционирования модели они как бы взаимодействовали друг с другом. Диаграмма сопровождается необходимыми комментариями. Использование блоков при построении моделей зависит от логических схем работы реальных систем, моделируемых на ЭВМ.
Теперь приступим к написанию программы модели.
Программа модели
Для задания исходных данных используем переменные пользователя. Они задаются с помощью команды EQU. Переменным пользователя даны такие же имена, как и в постановке задачи, но добавлен знак подчеркивания. Например, T1_, S1_ и т. д. Время моделирования зададим переменной пользователя VrMod.
Арифметическая переменная для расчета времени обработки VrObr запроса на сервере:
VrObr VARIABLE (Normal(2,(S1_#Koef),(S2_#Koef))))/Q_
Переменная пользователя Koef введена для удобства изменения (пропорционального изменения) характеристик нормального закона распределения, которому подчиняется вычислительная сложность запросов. Особенно целесообразно использование этой переменной при проведении экспериментов.
Вероятность обработки VerObr запросов на сервере будем определять как отношение количества обработанных N$ObrZap запросов к количеству всего поступивших N$KolZap запросов:
VerObr VARIABLE N$ObrZap/N$KolZap
В арифметическом выражении VerObr, например, N$ObrZap - системный числовой атрибут - количество транзактов, вошедших в блок с меткой ObrZap, а N$KolZap - количество транзактов, вошедших в блок с меткой KolZap.
Количество обработанных запросов определяется арифметическим выражением:
Res VARIABLE INT(N$ObrZap/X$Prog)
Все необходимое для написания программы модели имеется. Напишем программу модели для решения прямой задачи.
; Обработка запросов сервером. Прямая задача ; Задание исходных данных T1_ EQU 120 ; Средний интервал поступления запросов, с S1_ EQU 60000000 ; Среднее значение вычислительной сложности запросов, оп S2_ EQU 200000 ; Стандартное отклонение вычислительной сложности запросов, оп Q_ EQU 600000 ; Средняя производительность сервера, оп/с Emk EQU 5 ; Ёмкость входного буфера Koef EQU 1 ; Коэффициент изменения характеристик нормального распределения VrObr VARIABLE (Normal(9,(S1_#Koef),(S2_#Koef)))/Q_ VerObr VARIABLE N$ObrZap/N$KolZap Res VARIABLE INT(N$ObrZap/X$Prog) VrMod EQU 3600 ; Время моделирования, 1 ед. мод. времени = 1 с. ; Сегмент имитации обработки запросов GENERATE (Exponential(2,0,T1_)) ; Источник запросов KolZap TEST L Q$Server,Emk,PotZap ; Занят ли буфер? QUEUE Server ; Встать в очередь к серверу SEIZE Server ; Занять сервер DEPART Server ; Покинуть очередь к серверу ADVANCE V$VrObr ; Имитация обработки запроса SAVEVALUE SumTime+,M1; Время обработки всех запросов RELEASE Server ; Освободить сервер ObrZap TERMINATE ; Обработанные запросы PotZap TERMINATE ; Потерянные запросы ; Сегмент задания времени моделирования и расчета результатов GENERATE VrMod TEST L X$Prog,TG1,Met1 ; Если X$Prog < TG1, SAVEVALUE Prog,TG1 ; то X$Prog = TG1 Met1 TEST E TG1,1,Met2 ; Если TG1 = 1, то SAVEVALUE VerObr,V$VerObr ; расчет и сохранение в ячейке VerObr вероятности обработки запросов SAVEVALUE Res,V$Res ; числа обработанных запросов SAVEVALUE TimeMean,(X$SumTime/N$ObrZap) Met2 TERMINATE 1 START 9604 ; Количество прогонов модели
При расчете количества обработанных запросов Res в арифметическом выражении N$ObrZap/X$Prog используется число прогонов. В арифметическом выражении указано не явное число прогонов, а в виде содержимого ячейки X$Prog. Число прогонов заносится предварительно в эту ячейку по завершении первого прогона модели, но до того момента, когда из счетчика завершений TG1 будет вычтена первая единица. В этом случае арифметическое выражение не зависит от числа прогонов, которое может меняться на различных этапах создания и эксплуатации модели, в том числе и в зависимости от исходных данных, а также от точности и достоверности результатов моделирования. Поскольку количество обработанных запросов не может быть дробным числом, то для получения целого числа, записываемого в ячейку Res, используется процедура INT из встроенной библиотеки.
Среднее время X$TimeMean обработки одного запроса определяется как отношение суммарного времени X$SumTime к количеству обработанных запросов N$ObrZap. В данной модели можно определять X$TimeMean как сумму средних времен обработки одного транзакта на сервере и среднего времени задержки в очереди.
Для уменьшения машинного времени расчет искомых показателей производится не после каждого прогона, а после завершения последнего прогона, т. е. когда содержимое счетчика завершений будет равно единице (TG1 = 1).
Ввод текста программы модели, исправление ошибок и проведение моделирования
- Запустите GPSS World.
- Закройте окно напоминания о необходимости обновления "Заметок". Откроется главное меню.
- Для ввода текста GPSS World имеет текстовый редактор. Откройте окно текстового редактора. Для этого выберите в меню File / New и в появившемся меню выберите Model. Нажмите Ok.
- Наберите текст программы модели, т. е. создайте объект "Модель". При вводе текста следует использовать клавишу [Tab]. Например, после набора Т1_ нужно нажать клавишу [Tab]. Интервалы табуляции установлены по умолчанию.
- После ввода программы модели создайте объект "Процесс моделирования", представляющий собой оттранслированный объект "Модель". Для трансляции выберите Command / Create Simulation. По этой команде транслятор GPSS проверяет программу модели на наличие синтаксических ошибок.
- При наличии синтаксических ошибок система в окне JOURNAL выдаст список сообщений об ошибках трансляции. Перейдите к п. 7. При отсутствии ошибок в окне JOURNAL появится сообщение Model Translation Begun. Ready. Перейдите к п. 9.
- Исправьте ошибки. Для поиска ошибок в тексте программы модели и их исправления используйте команду Search / Next Error, предварительно перейдя из окна JOURNAL в текст программы модели. При первом выполнении этой команды курсор мыши помещается в строке текста модели с ошибкой. После исправления первой ошибки вновь используйте команду Search / Next Error и т.д. столько раз, сколько ошибок в тексте программы.
- После исправления ошибок перейдите к п.5.
- Сохраните модель. Для этого выберите в главном меню File / Save As. Дайте модели имя Модель процессов изготовления изделий и нажмите Ok.
- Откликом в данной модели является вероятность обработки запросов сервером. Ранее вы рассчитали количество прогонов модели для худшего случая при точности , и доверительной вероятности
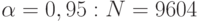 .
.
- Запустите модель. Для этого в главном меню выберите Command / Start и в диалоговом окне вместо 1 наберите 9604. Нажмите Ok.
- При наличии логических ошибок для их поиска в тексте программы модели и исправления используйте команду Search / Goto Line столько раз, сколько ошибок указано в окне JOURNAL. Там же (в окне JOURNAL) указаны номера строк с ошибками.
- При отсутствии логических ошибок в модели по окончании её работы система GPSS World автоматически создает стандартный отчет, который появится в окне Report. В окне будут содержаться следующие данные:
- об именах объектов модели;
- блоках модели;
- ОКУ и МКУ;
- очередях;
- сохраняемых величинах.
В результате решения прямой задачи получим, что за один час сервером будет обработано N = 29 запросов, а вероятность обработки составит VerObr = 0,97. Если не использовать процедуру INT - выделения целого числа с отбрасыванием дробной части, будет обработано 29,161 запроса. Среднее время обработки одного запроса составит TimeMean = 255,262.
Дисперсионный анализ (отсеивающий эксперимент)
Сущность этого эксперимента состоит в проведении многофакторного дисперсионного анализа с целью выявления степени влияния различных факторов и их комбинаций (взаимодействий) на значение целевой функции (функции отклика, представленной в виде уравнения регрессии).
Для каждого фактора необходимо выбрать два уровня - нижний и верхний. Рекомендуется выбирать уровни, значительно отстоящие друг от друга. Это необходимо для получения также значительно отличающихся откликов.
В условиях прямой задачи требуется исследовать зависимость вероятности обработки запросов от трех факторов, например, при следующих их минимальных и максимальных значениях (Табл. 1.1):
| Уровни факторов | Факторы | ||
|---|---|---|---|
| T1_, с | Koef | Q_, оп/c | |
| Нижний | 60 | 0.5 | 300000 |
| Верхний | 180 | 1.5 | 700000 |
Для проведения дисперсионного анализа нужно воспользоваться созданным объектом "Модель". В программе модели удалите последнюю строку.
Откройте модель Прямая задача. Выберите Edit / Insert Experiment / Screening … (Правка / Вставить эксперимент / Отсеивающий …).
Откроется диалоговое окно Screening Experiment Generator (Генератор отсеивающего эксперимента) (Рис. 1.2).
Приступите к заполнению полей диалогового окна.
В поля Experiment Name (Имя эксперимента) и Run Procedure Name (Имя процедуры запуска) введите, например, Dis_Server и Dis_Server_Run соответственно (Рис. 1.3).
Имена эксперименту и процедуре запуска эксперимента даёт пользователь.
Дальше расположена группа полей Factors (Факторы). В рассматриваемом примере определяется вероятность обработки запросов, поступающих на сервер. Факторы, влияние которых необходимо исследовать, были определены нами ранее (см. табл. 1.1).
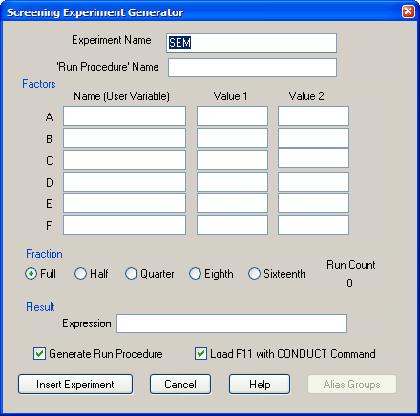
Рис. 1.2. Диалоговое окно (незаполненное) Screening Experiment Generator (Генератор отсеивающего эксперимента)
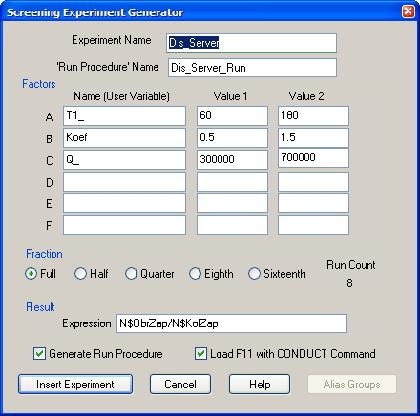
Рис. 1.3. Диалоговое окно (заполненное) Screening Experiment Generator (Генератор отсеивающего эксперимента)
В GPSS World максимальное количество факторов, влияние которых на функцию отклика можно исследовать посредством дисперсионного анализа, равно шести.
Введите ранее выбранные факторы, начиная с фактора А. В поле Name (User Variable) (Имя (Переменная пользователя)) введите имя фактора, в поля Value1 и Value2 - его нижний и верхний уровни соответственно. После ввода всех факторов для дальнейшей работы будем иметь факторы А, В и С.
Ниже идет группа Fraction (Часть полного эксперимента). Эксперимент, проводимый в GPSS World, может быть полным факторным экспериментом (ПФЭ) или дробным факторным экспериментом (ДФЭ). Группа Fraction (Часть дробного эксперимента) позволяет это задавать, т. е. позволяет провести стратегическое планирование эксперимента, цель которого, как вам известно, является определение количества наблюдений и сочетаний уровней факторов в них для получения наиболее полной и достоверной информации о поведении системы.
Установке ПФЭ соответствует кнопка Full, для ДФЭ в 1/2 от ПФЭ - Half, в 1/4 - Quarter, в 1/8 - Eight, в 1/16 - Sixteen.
Установите пока Half (1/2). Справа под Run Count появится число 4, так как 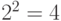 . Это количество наблюдений, которое необходимо сделать. Количество прогонов в каждом наблюдении будет указано позже.
. Это количество наблюдений, которое необходимо сделать. Количество прогонов в каждом наблюдении будет указано позже.
В поле Expression (Выражение) группы Result (Результат) введите выражение, по которому вычисляется вероятность обработки запросов: N$ObrZap/N$KolZap.
После группы Result (Результат) расположены два флажка, позволяющие выбирать опции.
При выборе опции Generate Run Procedure вместе с экспериментом создается стандартная процедура запуска, которую пользователь может корректировать согласно своим требованиям.
Выбор второй опции Load F11 with CONDUCT Command закрепляет команду CONDUCT за функциональной клавишей F11. Тогда после создания объекта "Процесс моделирования" для запуска эксперимента нужно только нажать функциональную клавишу F11. Выберите обе опции.
Перед созданием эксперимента необходимо изучить группы смешивания с целью осуществления стратегического планирования эксперимента. Для этого нужно нажать кнопку Alias Groups (Группы смешивания). Появится диалоговое окно Alias Groups (Группы смешивания) (Рис. 1.4).
При изучении групп смешивания необходимо вначале найти отсутствующие факторы, а затем факторы, которые неразличимы, так как находятся в одной группе смешивания. Например, взаимодействие факторов А и В - АВ.