


|
1 октября отправила на проверку первое задание, до сих пор не проверено, по этой причине не могу пройти последующие тесты. |
Опубликован: 18.11.2015 | Доступ: свободный | Студентов: 2634 / 0 | Длительность: 22:20:00
Специальности: Преподаватель
Лекция 10:
Learning and teaching
Characteristics of a good test
In order to judge the effectiveness of any test, it is sensible to lay down criteria against which the test can be measured, as follows:
- Validity: a test is valid if it tests what it is supposed to test. Thus it is not valid, for example, to test writing ability with an essay question that requires specialist knowledge of history or biology - unless it is known that all students share this knowledge before they do the test. A test is valid if it produces similar results to some other measure - that is if we can show that Test A gives us the same kind of results as Test B (or some other test). A test is only valid if there is validity in the way it is marked; if we score short written answers to a listening test for spelling and grammar, then it is not necessarily a valid test of listening. We are scoring the wrong thing. A particular kind of validity that concerns most test designers is face validity. This means that the test should look, on the face of it, as if it is valid. A test which consisted of only three multiple-choice items would not convince students of its face validity, however reliable or practical teachers thought it to be.
- Reliability: a good test should give consistent results. For example, if the same group of students took the same test twice within two days - without reflecting on the first test before they sat it again - they should get the same results on each occasion. If they took another similar test, the results should be consistent. If two groups who were demonstrably alike took the test, the marking range would be the same. In practice, reliability is enhanced by making the test instructions absolutely clear, restricting the scope for variety in the answers and making sure that test conditions remain constant. Reliability also depends on the people who mark the tests - the scorers. Clearly a test is unreliable if the result depends to any large extent on who is marking it. Much thought has gone into making the scoring of tests as reliable as possible.
Types of test item
Whatever purpose a test or exam has, a major factor in its success or failure as a good measuring instrument will be determined by the item types that it contains.
Direct and indirect test items
A test item is direct if it asks candidates to perform the communicative skill which is being tested. Indirect test items, on the other hand, try to measure a student's knowledge and ability by getting at what lies beneath their receptive and productive skills. Whereas direct test items try to be as much like real-life language use as possible, indirect items try to find out about a student's language knowledge through more controlled items, such as multiple-choice questions or grammar transformation items. These are often quicker to design and, crucially, easier to mark, and produce greater scorer reliability.
Another distinction needs to be made between discrete-point testing and integrative testing.
Whereas discrete-point testing only tests one thing at a time (such as asking students to choose the correct tense of a verb), integrative test items expect students to use a variety of language at anyone given time - as they will have to do when writing a composition or doing a conversational oral test.
In many proficiency tests where students sit a number of different papers, there is a mixture of direct and indirect, discrete-point and integrative testing. Test designers find that this combination gives a good overall picture of student ability. Placement tests often use discrete-point testing to measure students against an existing language syllabus, but may then compare this with more direct and integrative tasks to get a fuller picture.
Indirect test item types
Although there is a wide range of indirect test possibilities, certain types are in common use.
-
Multiple-choice questions: a traditional vocabulary multiple-choice question (MCQ) looks like this:
For many years, MCQs were considered to be ideal test instruments for measuring students' knowledge of grammar and vocabulary. Above all, this was because they were easy to mark. Moreover, since the advent of computers, the answer sheets for these tests can be read by machines, thereby cutting out the possibility of scorer error.
However, there are a number of problems with MCQs. In the first place, they are extremely difficult to write well, especially in terms of the design of the incorrect choices. These 'distractors' may actually put ideas into students' heads that they did not have before they read them. Secondly, while it is possible to train students so that their MCQ abilities are enhanced, this may not actually improve their English. The difference between two student scores may be between the person who has been trained in the technique and a person who has not, rather than being a difference of language knowledge and ability.
MCQs are still widely used, but though they score highly in terms of practicality and scorer reliability, their validity and overall reliability are suspect.
-
Cloze procedures: cloze procedures seem to offer us the ideal indirect but integrative testing item. They can be prepared quickly and, if the claims made for them are true, they are an extremely cost-effective way of finding out about a testee's overall knowledge. Cloze, in its purest form, is the deletion of every nth word in a text (somewhere between every fifth or tenth word). Because the procedure is random, it avoids test designer failings. It produces test items like this:
Cloze testing seems, on the face of it, like a perfect test instrument, since, because of the randomness of the deleted words, anything may be tested (e.g. grammar, collocation, fixed phrases, reading comprehension), and therefore it becomes more integrative in its reach. However, it turns out that the actual score a student gets depends on the particular words that are deleted, rather than on any general English knowledge. Some are more difficult to supply than others, and in some cases there are several possible answers. Even in the short sample text above, it is clear that while there is no doubt about items such as 1 and 8, for example, item 4 is less predictable. Different passages produce different results. Despite such problems of reliability, cloze is too useful a technique to abandon altogether because it is clear that supplying the correct word for a blank does imply an understanding of context and a knowledge of that word and how it operates. Perhaps it would be better, therefore, to use 'rational' or 'modified' cloze procedures where the test designer can be sure that the deleted words are recoverable from the context. This means abandoning the completely random nature of traditional cloze procedure. Instead, every eighth or tenth word is deleted, but the teacher has the option to delete a word to the left or right if the context makes this more sensible. Modified cloze is useful for placement tests since students can be given texts that they would be expected to cope with at certain levels - thus allowing us to judge their suitability for those levels. They are useful, too, as part of a test battery in either achievement or proficiency tests.
-
Transformation and paraphrase: a common test item asks candidates to re- write sentences in a slightly different form, retaining the exact meaning of the original. For example, the following item tests the candidates' knowledge of verb and clause patterns that are triggered by the use of I wish.
I’m sorry that I didn’t get her an anniversary present.
I wish _____________________________________
In order to complete the item successfully, the student has to understand the first sentence, and then know how to construct an equivalent which is grammatically possible. As such, they do tell us something about the candidates' knowledge of the language system.
-
Sentence re-ordering: getting students to put words in the right order to make appropriate sentences tells us quite a lot about their underlying knowledge of syntax and lexico¬grammatical elements. The following example is typical:
Put the words in order to make correct sentences:
Called / I / I’m / in / sorry / wasn’t / when / you
Re-ordering exercises are fairly easy to write, though it is not always possible to ensure only one correct order.
There are many other indirect techniques, too, including sentence fill-ins (Jon __ to the gym every Tuesday morning), choosing the correct tense of verbs in sentences and passages (I have arrived/arrived yesterday), finding errors in sentences (She noticed about his new jacket), and choosing the correct form of a word (He didn't enjoy being on the [lose] __ side). All of these offer items which are quick and efficient to score and which aim to tell us something about a student's underlying knowledge.
Direct test item types
For direct test items to achieve validity and to be reliable, test designers need to do the following:
-
Create a 'level playing field': in the case of a written test, teachers and candidates would almost certainly complain about the following essay question:
Why was the discovery of DNA so important for the science of the twentieth century?
since it unfairly favours candidates who have sound scientific knowledge and presupposes a knowledge of twentieth-century scientific history. However, the following topic comes close to ensuring that all candidates have the same chance of success:
Receptive skill testing also needs to avoid making excessive demands on the student's general or specialist knowledge. Receptive ability testing can also be undermined if the means of testing requires students to perform well in writing or speaking (when it is a test of reading or listening). In such a situation we can no longer be sure that it is the receptive skill we are measuring.
- Replicate real-life interaction: in real life when people speak or write, they generally do so with some real purpose. Yet traditional writing tests have often been based exclusively on general essay questions, and speaking tests have often included hypothetical questions about what candidates might say if they happened to be in a certain situation. More modern test writers now include tasks which attempt to replicate features of real life tests of reading and listening should also, as far as possible, reflect real life. This means that texts should be as realistic as possible, even where they are not authentic. Although there are ways of assessing student understanding (using matching tasks or multiple-choice questions) which do not necessarily satisfy these criteria, test items should be as much like real reading and listening as possible.
Writing and marking tests
At various times during our teaching careers we may have to write tests for the students we are teaching, and mark the tests they have completed for us. These may range from a lesson test at the end of the week to an achievement test at the end of a term or a year.
Writing tests
Before designing a test and then giving it to a group of students, there are a number of things we need to do:
- Assess the test situation: before we start to write the test we need to remind ourselves of the context in which the test takes place. We have to decide how much time should be given to the test - taking, when and where it will take place, and how much time there is for marking.
- Decide what to test: we have to list what we want to include in our test. This means taking a conscious decision to include or exclude skills such as reading comprehension or speaking (if speaking tests are impractical). It means knowing what syllabus items can be legitimately included (in an achievement test), and what kinds of topics and situations are appropriate for our students. Just because we have a list of all the vocabulary items or grammar points the students have studied over the term, this does not mean we have to test every single item. If we include a representative sample from across the whole list, the students' success or failure with those items will be a good indicator of how well they have learnt all of the language they have studied.
- Balance the elements: if we are to include direct and indirect test items, we have to make a decision about how many of each we should put in our test. A 200-item multiple-choice test with a short real-life writing task tacked onto the end suggests that we think that MCQs are a better way of finding out about students than more integrative writing tasks would be. Balancing elements involves estimating how long we want each section of the test to take and then writing test items within those time constraints. The amount of space and time we give to the various elements should also reflect their importance in our teaching.
- Weight the scores: however well we have balanced the elements in our test, our perception of our students' success or failure will depend upon how many marks are given to each section of the test. If we give two marks for each of our ten MCQs but only one mark for each of our ten transformation items, it means that it is more important for students to do well in the former than in the latter.
- Make the test work: it is absolutely vital that we try out individual items and/or whole tests on colleagues and other students before administering them to real candidates. When we write test items, the first thing to do is to get fellow teachers to try them out. Frequently they spot problems which we are not aware of and/or come up with possible answers and alternatives that we had not anticipated. Later, having made changes based on our colleagues' reactions, we will want to try out the test on students. We will not do this with the students who are going to take the test, of course, but if we can find a class that is roughly similar - or a class one level above the proposed test - then we will soon find out what items cause unnecessary problems. We can also discover how long the test takes. Such trialling is designed to avoid disaster and to yield a whole range of possible answers/responses to the various test items. This means that when other people finally mark the test, we can give them a list of possible alternatives and thus ensure reliable scoring.
Marking tests
There are a number of considerations to avoid scorer subjectivity.
- Training: if scorers have seen examples of scripts at various different levels and discussed what marks they should be given, then their marking is likely to be less erratic than if they come to the task fresh. If scorers are allowed to watch and discuss videoed oral tests, they can be trained to 'rate the samples of spoken English accurately and consistently in terms of the pre-defined descriptions of performance' (Saville and Hargreaves 1999).
- More than one scorer: reliability can be greatly enhanced by having more than one scorer.The more people who look at a script, the greater the chance that its true worth will be located somewhere between the various scores it is given. Two examiners watching an oral test are likely to agree on a more reliable score than one. Many public examination boards use moderators whose job it is to check samples of individual scorer's work to see that it conforms with the general standards laid down for the exam.
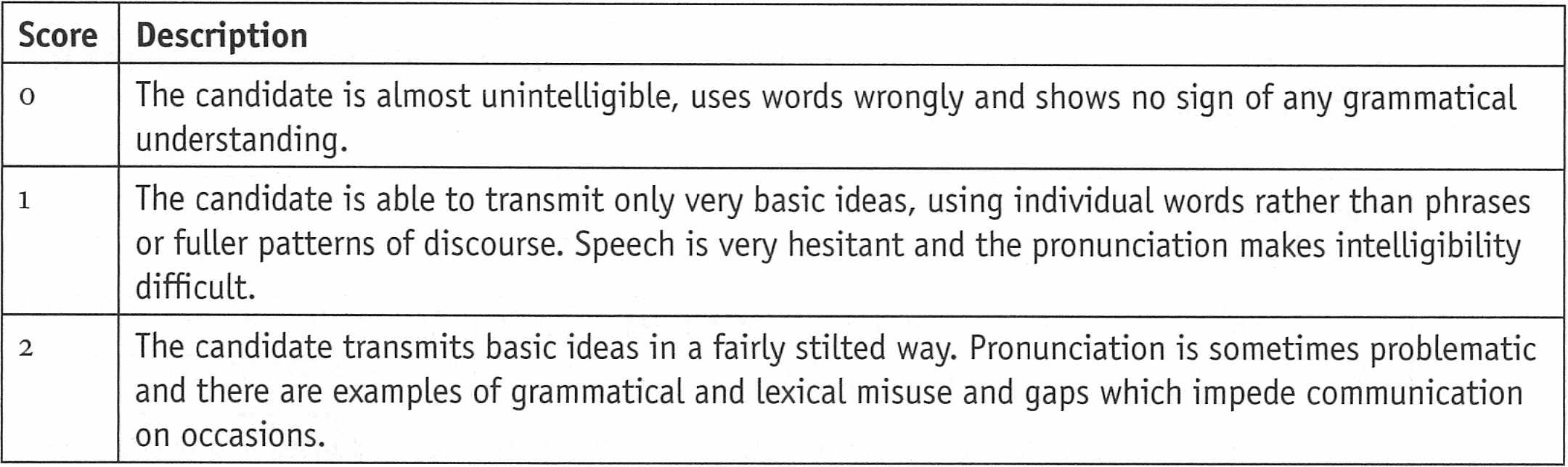
- Global assessment scales: a way of specifying scores that can be given to productive skill work is to create ‘pre-defined descriptions of performance’. Such descriptions say what students need to be capable of in order to gain the required marks, as in the following assessment (or rating) scale for oral ability: Global assessment scales are not without problems, however: perhaps the description does not exactly match the student who is speaking, as would be the case (for the scale above) where he or she had very poor pronunciation but was nevertheless grammatically accurate. There is also the danger that different teachers 'will not agree on the meaning of scale descriptors' (Upshur and Turner 1995: 5). Global assessment, on its own, still falls short of the kind of reliability we wish to achieve.
-
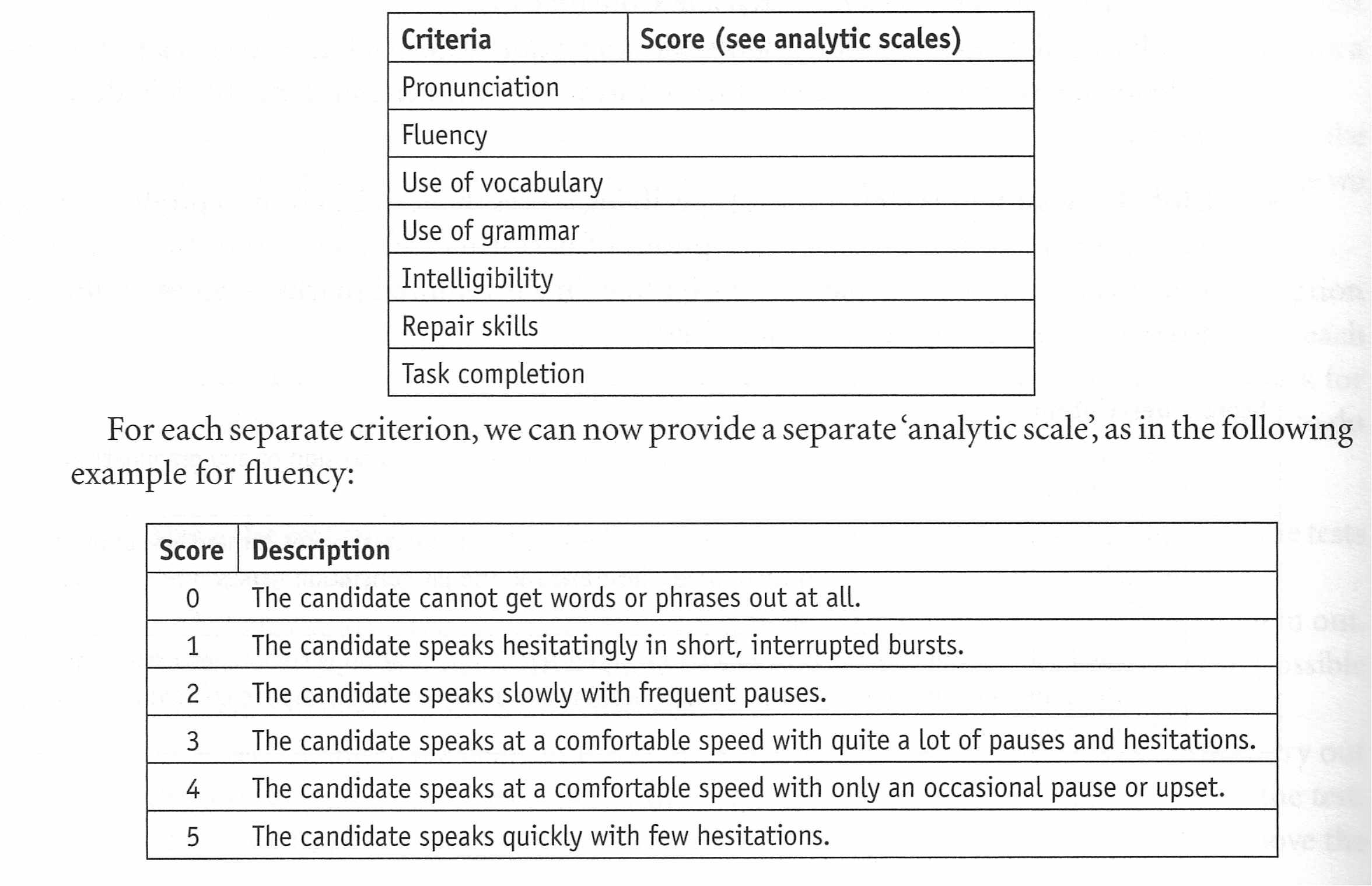
Analytic profiles: marking gets more reliable when a student's performance is analysed in much greater detail. Instead of just a general assessment, marks are awarded for different elements. For oral assessment we can judge a student's speaking in a number of different ways, such as pronunciation, fluency, use of lexis and grammar and intelligibility. We may want to rate their ability to get themselves out of trouble (repair skills) and how successfully they completed the task which we set them. The resulting analytic profile might end up looking like this:
A combination of global and analytic scoring gives us the best chance of reliable marking.
However, a profusion of criteria may make the marking of a test extremely lengthy and cumbersome; test designers and administrators will have to decide how to accommodate the competing claims of reliability and practicality.
- Scoring and interacting during oral tests: scorer reliability in oral tests is helped not only by global assessment scores and analytic profiles but also by separating the role of scorer (or examiner) from the role of interlocutor (the examiner who guides and provokes conversation). This may cause practical problems, but it will allow the scorer to observe and assess, free from the responsibility of keeping the interaction with the candidate or candidates going. In many tests of speaking, students are now put in pairs or groups for certain tasks since it is felt that this will ensure genuine interaction and will help to relax students in a way that interlocutor-candidate interaction might not. However, at least one commentator worries that pairing students in this way leads candidates to perform below their level of proficiency, and that when students with the same mother tongue are paired together, their intelligibility to the examiner may suffer (Foot 1999: 52).
Teaching for tests
One of the things that preoccupies test designers and teachers alike is what has been called the washback or backwash effect. This refers to the fact that since teachers quite reasonably want their students to pass the tests and exams they are going to take, their teaching becomes dominated by the test and, especially, by the items that are in it. Where non-exam teachers might use a range of different activities, exam teachers suffering from the washback effect might stick rigidly to exam-format activities. In such a situation, the format of the exam is determining the format of the lessons.
Two points need to be taken into account when discussing the washback effect, however.
In the first place, modern tests - especially the direct items included in them - are grounded far more in mainstream classroom activities and methodologies than some earlier examples of the genre. In other words, there are many direct test questions which would not look out of place in a modern lesson anyway. But secondly, even if preparing students for a particular test format is a necessity, 'it is as important to build variety and fun into an exam course as it is to drive students towards the goal of passing their exam' (Burgess and Head 2005: 1).
And we can go further: many teachers find teaching exam classes to be extremely satisfying in that where students perceive a clear sense of purpose - and are highly motivated to do as well as possible - they are in some senses 'easier' to teach than students whose focus is less clear. When a whole class has something to aim at, they may work with greater diligence than when they do not. Furthermore, in training students to develop good exam skills (including working on their own, reviewing what they have done, learning to use reference tools - e.g. dictionaries, grammar books, the Internet - keeping an independent learning record or diary, etc.), we are encouraging exactly those attributes that contribute towards autonomous learning.
Good exam-preparation teachers need to familiarise themselves with the tests their students are taking, and they need to be able to answer their students' concerns and worries. Above all, they need to be able to walk a fine line between good exam preparation on the one hand, and not being swept away by the washback effect on the other.
Adapted from The Practice of English Language Teaching, Jeremy Harmer 2007, Longman.