Компиляторы Intel. Возможности автоматической оптимизации
Векторизация
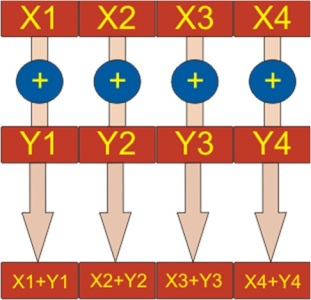
AVX – набор векторных команд
Intel® AVX (Advanced Vector Extensions) расширяет возможности 128-разрядных векторных регистров XMM (16 регистров), позволяя использовать 256-разрядные векторы. 256 разрядов используются в операциях с плавающей точкой.
В других операциях используются младшие 128 разрядов.
В AVX операнды и результат операции отделены друг от друга. Это позволяет оптимизировать использование регистров, генерировать более компактный код, уменьшить количество зависимостей т.д.
AVX для архитектуры Sandy Bridge

Поддержка векторных конструкций в Intel® CilkTM Plus и Array Building Blocks.
Поддержка прагм и "интринсиков" (низкоуровневые возможности).
Поддержка сложных условных выражений.
Улучшенная поддержка смешения типов в одном цикле.
Поддержка операций с насыщением.
Отчёты об оптимизации
Отчёты об оптимизации
- /Qvec-report - генерация протокола векторизации (что векторизовано, что нет и почему).
- /Qpar-report - генерация протокола распараллеливания.
- /Qopt-report - генерация протокола оптимизации.
Профилирование на уровне циклов
Сбор статистики по циклам и функциям
- /Qprofile-loops:all - сбор статистики.
- LoopProfileViewer - утилита для просмотра отчётов.
- GAP - Guided Auto Parallelism (направляемая автопараллелизация).
- /Qguide (-guide) - запуск анализа.
- Не порождает параллельный код, но даёт рекомендации.
Оптимизация в примерах
- Отключение оптимизации
- Подразумевается в режиме Debug в MS Visual Studio
- Глобальная оптимизация
- Не увеличивает размер кода
- Увеличивает размер кода
- Оптимизация времени выполнения
- Опция по умолчанию
- Подстановки в коде
- Развертывание циклов
- Векторизация
- Высокоуровневая оптимизация.
- Оптимизирующие преобразования уровня /O2 + более агрессивные методы.
- Улучшенная векторизация.
- Более полный учёт свойств циклов и массивов.
- Оптимизация циклов: разделение циклов (loop distribution), перестановка циклов (loop interchange), слияние циклов (loop fusion), развёртка циклов (loop unrolling).
- Подстановка кода в ветвлениях.
- Оптимизация под размер кэша.
- Предвыборка и предсказания ветвления.
- Возможна большая эффективность в приложениях, включающих обработку больших массивов.
Пример 1
Matrices.cpp
#include <ctime>
#include <iostream>
#include "stdlib.h"
#include "conio.h"
#include "math.h"
using namespace std;
const int SIZE = 1000;
void matrixMultiply(double ** matrA, double ** matrB, double ** matrC, int matrSize);
double sinCosMultiply(double i, double j);
int main()
{
time_t t1, t2;
double trace(0);
double ** matrixA = new double*[SIZE];
double ** matrixB = new double*[SIZE];
cout << "We will construct the square matrix " << SIZE << "x" << SIZE << endl;
cout << "of pseudo-random values" << endl;
cout << "and multiply it by itself. Then we will find the trace of the matrix." << endl;
for(int i = 0; i < SIZE; i++)
{
matrixA[i] = new double[SIZE];
matrixB[i] = new double[SIZE];
}
t1 = clock();
for(int i=0; i<SIZE; i++)
{
for(int j=0; j<SIZE; j++)
{
matrixA[i][j]=sinCosMultiply(rand()%10/3, rand()%10/3);
}}
matrixMultiply(matrixA, matrixA, matrixB, SIZE);
for(int i=0; i<SIZE; i++)
{
for(int j=0; j<SIZE; j++)
{
if(i==j) trace += matrixB[i][j];
}
}
t2 = clock();
cout << "\nTrace is " << trace << endl;
cout << "\nInitial clock ticks value is " << t1 << endl;
cout << "Final clock ticks value is " << t2 << endl;
cout << "Difference in clock ticks is " << difftime(t2,t1) << endl;
cout << "Clock ticks per second value is " << CLOCKS_PER_SEC << endl;
cout << "\nActual time of calculations is " << ((t2-t1)/CLOCKS_PER_SEC) << " sec" << endl;
for(int i = 0; i < SIZE; i++)
{
delete [] matrixA[i];
delete [] matrixB[i];
}
delete [] matrixA;
delete [] matrixB;
return 0;
}
void matrixMultiply(double ** matrA, double ** matrB, double ** matrC, int matrSize)
{
for(int i=0; i<matrSize; i++)
{
for(int j=0; j<matrSize; j++)
{
matrC[i][j] = 0;
for(int k=0; k<matrSize; k++)
{
matrC[i][j] += matrA[i][k]*matrB[k][j];
}
}
}
}
double sinCosMultiply(double i, double j)
{
return sin(i)*cos(j);
}
Подготовим тест:
- icl /FeMatricesOd /Od Matrices.cpp
- icl /FeMatricesO1 /O1 Matrices.cpp
- icl /FeMatricesO2 /O2 Matrices.cpp
- icl /FeMatricesO3 /O3 Matrices.cpp
Intel Core 2 Duo T3700 2.00 ГГц, 2 Гб RAM
Среднее значение времени выполнения:
- MatricesOd . . . 21.76 с.
- MatricesO1 . . . 14.05 с.
- MatricesO2 . . . 9.63 с.
- MatricesO3 . . . 9.57 с.
Вопрос. Объясните результаты теста.