Опубликован: 06.09.2005 | Доступ: свободный | Студентов: 12780 / 1211 | Оценка: 3.98 / 3.46 | Длительность: 12:50:00
ISBN: 978-5-9556-0025-3
Тема: Программирование
Специальности: Программист, Архитектор программного обеспечения
Теги:
Лекция 12:
Алгоритмы на графах и деревьях
Аннотация: Примеры алгоритмов обработки деревьев и графов. Сравнение рекурсивных и итеративных алгоритмов, решающих некоторые классические задачи теории графов.
Ключевые слова: арифметическое выражение, инфиксный порядок записи, префиксный порядок записи, постфиксный порядок записи, дерево синтаксического анализа, приоритет операций, очередной символ, левое поддерево, обход дерева, обход графа, корневое дерево, бинарное дерево, прямой обход, обход в глубину, матрица смежности, SM, линейный массив, mark, обратный обход, синтаксический обход, корень дерева, удаление вершины, дерево двоичного поиска, nil, компонента связности, связность, вершины графа, изолированная вершина, полный граф, итеративность, Связный граф, оптимальный каркас, алгоритм Краскала, расстояние, кратчайший путь, выделенная вершина, длина пути, параметр-значение, алгоритм Дейкстры
В этой лекции мы рассмотрим некоторые классические алгоритмы, использующие графы и деревья, приведем и сравним рекурсивные и итеративные их варианты.
Используемая здесь терминология полностью совпадает с терминологией, введенной в предыдущей лекции.
Генерация дерева синтаксического анализа
Одно и то же арифметическое выражение может быть записано тремя способами:
-
Инфиксный способ записи (знак операции находится между операндами):
((a / (b + c)) + (x * (y - z)))
Все арифметические операции, привычные нам со школьных лет, записываются именно таким образом.
-
Префиксный способ записи (знак операции находится перед операндами):
+( /(a, +(b,c)), *(x, -(y,z)))
Из знакомых всем нам функций префиксный способ записи используется, например, для sin(x), tg(x), f(x,y,z) и т.п.
-
Постфиксный способ записи (знак операции находится после операндов):
((a,(b,c)+ )/ ,(x,(y,z)- )* )+
Этот способ записи менее распространен, однако и с ним многим из нас приходилось сталкиваться уже в школе: примером будет n! (факториал).
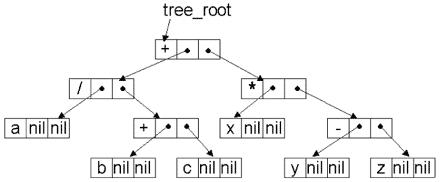
Разумеется, вид дерева синтаксического анализа (ДСА)1См. лекцию 11. арифметического выражения не зависит от способа записи этого выражения (см. рис. 12.1), поскольку определяет его не форма записи, а порядок выполнения операций. Но процесс построения дерева, конечно же, зависит от способа записи выражения. Далее мы разберем все три варианта алгоритма построения ДСА.
type ukaz = ^tree;
tree = record
symbol: char;
left: ukaz;
right: ukaz;
end;Построение из инфиксной записи
Для простоты мы будем считать, что правильное арифметическое выражение подается в одной строке, без пробелов, а каждый операнд записан одной буквой. Приоритет операций определяется расставленными скобками: ими должна быть снабжена каждая операция.
Алгоритм Infix
Если не достигнут конец строки ввода, прочитать очередной символ.
Если этот символ - открывающая скобка, то:
- создать новую вершину дерева;
- вызвать алгоритм Infix для ее левого поддерева;
- прочитать символ операции и занести его в текущую вершину;
- вызвать алгоритм Infix для правого поддерева;
- прочитать символ закрывающей скобки (и ничего с ним не делать).
Иначе:
- создать новую вершину дерева;
- занести в нее этот символ.
Реализация
Мы воспользуемся здесь описанием типа данных ukaz, приведенным на рис. 12.1:
procedure infix(var p: ukaz);
var c: char;
begin
read(c);
if c = '('
then begin
new(p);
infix(p^.left);
read(p^.symbol); {'+', '-', '*', '/'}
infix(p^.right);
read(c); {')'}
end
else begin {'a'..'z','A'..'Z'}
new(p);
p^.symbol:= c;
p^.right:= nil;
p^.left:= nil
end;
end;
begin
...
infix(root);
...
end.Построение из префиксной записи
Для простоты предположим, что правильное арифметическое выражение подается в одной строке, без пробелов, а каждый операнд записан одной буквой. Кроме того, будем считать, что из записи удалены все скобки: это вполне допустимо, так как операция всегда предшествует своим операндам, следовательно, путаница в порядке выполнения невозможна.
Алгоритм Prefix
- Если не достигнут конец строки ввода, прочитать очередной символ.
- Создать новую вершину дерева, записать в нее этот символ.
- Если символ - операция, то:
Реализация
Вновь воспользуемся описанием типа данных ukaz, приведенным на рис. 12.1:
procedure prefix(var p: ukaz); begin new(p); read(p^.symbol); if p^.symbol in ['+','-','*','/'] then begin prefix(p^.left); prefix(p^.right); end else begin p^.left:= nil; p^.right:= nil; end end; begin ... prefix(root); ... end.
Ольга Стебакова
|
Вот фрагмент лекции 5 (статья 4): Проверка множества на пустоту может быть осуществлена довольно просто: pusto:= true; for i:= 1 to N do if set_arr[i] then begin pusto:= false; break end; {мне кажется здесь должно быть так: if set_arr[i]<>0 then begin pusto:= false; break end;} Хотелось бы знать это ошибка в теории или я просто не поняла лекцию? |