|
Здравствуйте! Записался на ваш курс, но не понимаю как произвести оплату. Надо ли писать заявление и, если да, то куда отправлять? как я получу диплом о профессиональной переподготовке? |
Опубликован: 19.03.2004 | Доступ: свободный | Студентов: 2801 / 417 | Оценка: 3.98 / 3.79 | Длительность: 17:50:00
ISBN: 978-5-9556-0008-6
Тема: Программирование
Специальности: Программист, Архитектор программного обеспечения
Теги:
Лекция 9:
Реализационные решения
Реализация динамической памяти и структур данных
После обсуждения схемы функционирования Лисп-интерпретатора и его сборки из машинно-зависимого конструктива пришло время поговорить о структурах данных, используемых при реализации списков и атомов.
Обычно при обработке программ в памяти располагаются разносортные результаты, возникающие при разборе и анализе текста программы и ее данных, при построении ее внутреннего кода и при формировании результата. В Лисп-системах традиционно при всех этих видах работ принято придерживаться принципов логики здравого смысла:
- новые значения строятся на новом месте,
- предпочитаются интересы малых программ,
- автоматизируется повторное использования памяти, что на первых шагах разработки освобождает программиста от необходимость уделять внимание вторичным проблемам распределения памяти.
Кроме того, почти исключается необходимость присваиваний, они в программах заменяются именованием.
Память обычно распределена по блокам, содержащим ряд слов, образующих структуры данных. Физический объем памяти, логическая длина данных и состав информации, полезной для продолжения вычислений, могут существенно различаться. Минимальные потери в результативности работы с памятью дает динамическая обработка бинарных деревьев — нет простоев из-за незаполненности части полей. Каждый узел такого дерева имеет небольшой объем, достаточный для хранения двух типизированных указателей ( CAR и CDR, левый и правый). Типизация указателей нужна для динамического контроля соответствия данных и операций по их обработке. NIL, атомы, списки, числа, строки — все это реализационно различимые типы данных. (Утверждение о бестиповости Лиспа имеет отношение лишь к отсутствию статического связывания в тексте программы имен переменных с типами их значений. Для компиляции приходится дополнять Лисп-программы сведениями о типах значений свободных переменных, но далеко не каждая программа доживает до компиляции.) Лиспу свойственна функциональная классификация значимых типов данных, т.е. именно реализационно различимых.
Реализация бинарных деревьев или односвязных списков описана в классических курсах по программированию, а реализацию атомов мы рассмотрим подробнее. Эффективность приведенного выше определения интерпретатора с использованием ассоциативного списка существенно зависит от числа различимых атомов в программе. Такая зависимость обычно смягчается механизмом функций расстановки (хэш-функций), обеспечивающим доступ к информации по ключу. В качестве ключа используется имя атома. В результате вся связанная с атомом уникальная информация становится легко и быстро достижимой. Структура такой информации называется списком свойств атома. Она представляет собой чередование так называемых "индикаторов" и "значений" свойств. Число свойств атома не ограничено. Свойства бывают встроенные, системные или вводимые программистом. Значения атомов, адреса встроенных операций, определяющие выражения функций — примеры встроенных свойств. Встроенные операции типа LET, LABELS в системе Clisp обычно используют списки свойств. Обработка таблицы, связывающей атомы и их списки свойств, как правило, зависит от реализации. Методы задания и изменения свойств работают подобно обычным присваиваниям. Псевдо-функция PUT задает индикатор и соответствующее ему новое значение свойства атома, а функция GET обеспечивает доступ к свойству атома, соответствующему заданному индикатору. Теперь с помощью списков свойств мы могли бы добиться точного соответствия семантики констант и определений функций их спецификации в базовом Лиспе, но не будем отвлекаться на это.
Самым интересным, можно сказать революционным, механизмом работы с памятью в Лиспе, бесспорно, стала "сборка мусора". С начала 1960-х годов методам такой работы посвящены многочисленные исследования, которые продолжаются до наших дней и сильно активизировались в связи с включением похожего механизма в реализацию языка Java.
Общая идея всех таких методов достаточно проста:
- пока памяти хватает, о ней можно не беспокоиться и располагать новые данные в новых блоках памяти;
- если памяти вдруг не оказалось, то надо выполнить "сборку мусора", в процессе которой, возможно, найдутся ставшие бесполезными для программы блоки;
- если память нашлась, ее снова можно тратить.
Специальная программа "Сборщик мусора" выполняет анализ достижимости всех блоков памяти просто пометкой узлов, видимых из конечного числа рабочих регистров системы программирования. К таким регистрам относятся промежуточные результаты вычислений, активная часть стека, ассоциативный список, таблица атомов и др. После пометки все непомеченные узлы объединяются в список свободной памяти, передающий их для повторного использования новым вызовам функции CONS. Такая автоматизация не лишена недостатков, но они обнаруживаются лишь в сравнительно сложных процессах, требования которых мы сейчас не учитываем.
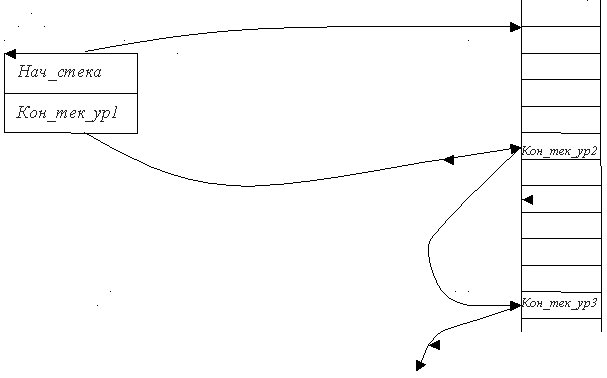
Обычно с машиной связывается представление о блоках информации фиксированного объема, таких как слова, байты, регистры. Функциональное программирование нацелено на более крупные построения — структуры данных не ограниченной заранее длины. Такие структуры достаточно эффективно реализуются посредством специального стека, приспособленного к обработке произвольного числа компонентов текущего уровня иерархической структуры данных.
От обычного стека он отличается выделением указателя на конец текущего уровня.
При переходе на новый внутренний уровень Кон_тек_ур записывается в стек, Нач_стека переписывается в Кон_тек_ур, а адрес новой вершины стека становится значением Нач_стека.
В результате стек хранит ссылки на границы уровней, что обеспечивает возможность возврата на любой нужный уровень, в частности, восстановления процесса обработки в случае неожиданных ситуаций.
Значительный резерв производительности функциональных программ дают деструктивные функции, являющиеся формальными аналогами чистых функций: