Этапы проведения интеллектуального анализа данных
Рассмотрим теперь этапы проведения интеллектуального анализа данных. Специалисты Майкрософт предлагают следующий вариант декомпозиции данной задачи [7]:
- постановка задачи;
- подготовка данных;
- изучение данных;
- построение моделей;
- исследование и проверка моделей;
- развертывание и обновление моделей.
На рисунке 3.1 схематично представлены перечисленные этапы и указаны средства MS SQLServer,с помощью которых они выполняются.Указанные этапы не обязательно будут пройдены один за другим. Например, на одном из промежуточных этапов может выясниться, что в текущей постановке для решения задачи не хватает данных и понадобится снова вернуться к первому этапу.
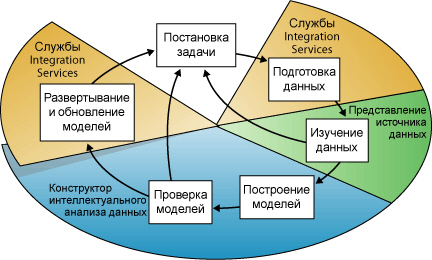
На этапе постановки задачи нужно определить, что является целью анализа. В частности, требуется ответить на ряд вопросов, главный из которых - что именно необходимо определить в результате анализа. Также в этом списке:
- Нужно ли будет делать прогнозы на основании модели интеллектуального анализа данных или просто найти содержательные закономерности и взаимосвязи?
- Если требуется прогноз, какой атрибут набора данных необходимо спрогнозировать?
- Как связаны столбцы? Если существует несколько таблиц, как они связаны?
- Каким образом распределяются данные? Являются ли данные сезонными? Дают ли данные точное представление о предметной области?
Как правило, в процессе постановки задачи аналитик работает совместно со специалистами в предметной области.
Этап подготовки данных включает определение источников данных для анализа, объединение данных и их очистку. Используемые данные могут находиться в различных базах и на разных серверах. Более того, какие-то данные могут быть представлены в виде текстовых файлов, электронных таблиц, находиться в других форматах. В процессе объединения и преобразования данных часто используются возможности служб SQLServerIntegrationServices (рис.1). Это позволяет существенно автоматизировать процесс подготовки.
Собранные таким образом данные, как правило, нуждаются в дополнительной обработке, называемой очисткой. В процессе очистки при необходимости может производиться удаление "выбросов" (нехарактерных и ошибочных значений), обработка отсутствующих значений параметров, численное преобразование (например, нормализация) и т.д.
Следующим этапом является изучение данных, которое позволит понять, насколько адекватно подготовленный набор представляет исследуемую предметную область. Здесь может проводиться поиск минимальных и максимальных значений параметров, анализ распределений значений и других статистических характеристик, сравнение полученных результатов с представлениями о предметной области.
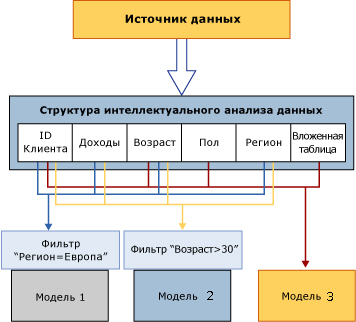
Четвертый этап - построение моделей. Как уже разбиралось в предыдущей лекции, сначала создается структура данных, а потом для структуры создается одна или несколько моделей. Модель включает указание на алгоритм интеллектуального анализа данных и его параметры, а также анализируемые данные. При определении модели могут использоваться различные фильтры.Таким образом, не все имеющиеся в описании структуры данные будут использоваться каждой созданной для нее моделью. На рисунке 3.2 показан пример, в котором для одной структуры создается несколько моделей, использующие различные наборы столбцов и фильтров.
Модель может проходить обучение, заключающееся в применении выбранного алгоритма к обучающему набору данных. После этого в ней сохраняются выявленные закономерности.
Новую модель можно определить с помощью мастера интеллектуального анализа данных в среде BI DevStudio или с помощью языка DMX. Нередко для решения задачи создается несколько моделей, основанных на разных алгоритмах, чтобы была возможность сравнить результаты и выбрать наилучшую.
Пятый этап - проверка модели. Здесь целью является оценка качества работы созданной модели перед началом ее использования в "производственной среде". Если создавалось несколько моделей, то на этом этапе делается выбор в пользу той, что даст наилучший результат.
При решении предсказательных задач интеллектуального анализа качество выдаваемого моделью прогноза можно оценить на проверочном наборе данных, для которого известно значение прогнозируемого параметра. В MSSQLServer 2008 службы AnalysisServices предоставляют средства, упрощающие разделение данных на обучающий и проверочный наборы. Такое секционирование можно выполнить автоматически во время построения модели интеллектуального анализа данных. Точность прогнозов, создаваемых моделями, можно проверить при помощи таких средств, как диаграмма точности прогнозов и матрица классификации.
Другой подход, называемый перекрестной проверкой, заключается в том, что создаются подмножества данных и сравниваются результаты работы модели на каждом подмножестве. Такой подход может использоваться как при решении предсказательных, так и описательных задач. Средства автоматизации перекрестной проверки доступны при использовании MSSQLServer 2008 версии Enterprise или Developer.
Наиболее эффективные модели развертываются в производственной среде. При этом, возможны сценарии интеграции средств интеллектуального анализа данных и пользовательских приложений. И конечный пользователь, в ответ на сформированный запрос, будет получать результаты анализа в виде отчета. При формировании отчетов о результатах проведенного анализа могут использоваться возможности службы SQLServer ReportingServices.
Со временем характеристики предметной области могут меняться, что потребует и изменения шаблонов интеллектуального анализа данных. Может потребоваться переобучение существующих моделей или создание новых. В ряде случаев SQLServer позволяет автоматизировать процесс обновления моделей за счет использования служб IntegrationServices.