Опубликован: 11.04.2007 | Доступ: свободный | Студентов: 6127 / 2371 | Оценка: 4.37 / 4.24 | Длительность: 11:19:00
Тема: Безопасность
Специальности: Специалист по безопасности
Лекция 7:
Подстановочные или словарно-ориентированные алгоритмы сжатия информации. Методы Лемпела-Зива
Если механически чрезмерно увеличивать размеры словаря и буфера, то это приведет к снижению эффективности кодирования, т.к. с ростом этих величин будут расти и длины кодов для смещения и длины, что сделает коды для коротких подстрок недопустимо большими. Кроме того, резко увеличится время работы алгоритма-кодера.
В 1978 г. авторами LZ77 был разработан алгоритм LZ78, лишенный названных недостатков.
LZ78 не использует "скользящее" окно, он хранит словарь из уже просмотренных фраз. При старте алгоритма этот словарь содержит только одну пустую строку (строку длины нуль). Алгоритм считывает символы сообщения до тех пор, пока накапливаемая подстрока входит целиком в одну из фраз словаря. Как только эта строка перестанет соответствовать хотя бы одной фразе словаря, алгоритм генерирует код, состоящий из индекса строки в словаре, которая до последнего введенного символа содержала входную строку, и символа, нарушившего совпадение. Затем в словарь добавляется введенная подстрока. Если словарь уже заполнен, то из него предварительно удаляют менее всех используемую в сравнениях фразу.
Ключевым для размера получаемых кодов является размер словаря во фразах,
потому что каждый код при кодировании по методу LZ78 содержит номер фразы в
словаре. Из последнего следует, что эти коды имеют постоянную длину, равную
округленному в большую сторону двоичному логарифму размера словаря 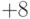 (это количество бит в байт-коде расширенного ASCII).
(это количество бит в байт-коде расширенного ASCII).
Пример. Закодировать по алгоритму LZ78 строку "КРАСНАЯ КРАСКА", используя словарь длиной 16 фраз.

Указатель на любую фразу такого словаря - это число от 0 до 15, для его кодирования достаточно четырех бит.
В последнем примере длина полученного кода равна  битам.
битам.
Алгоритмы LZ77, LZ78 и LZSS разработаны математиками и могут использоваться свободно.
В 1984 г. Уэлчем (Welch) был путем модификации LZ78 создан алгоритм LZW.
Пошаговое описание алгоритма-кодера.
Шаг 1. Инициализация словаря всеми возможными односимвольными фразами (обычно 256 символами расширенного ASCII). Инициализация входной фразы w первым символом сообщения.
Шаг 2. Считать очередной символ K из кодируемого сообщения.
Шаг 3. Если КОНЕЦ_СООБЩЕНИЯ
Выдать код для w
Конец
Если фраза wK уже есть в словаре
Присвоить входной фразе значение wK
Перейти к Шагу 2
Иначе
Выдать код w
Добавить wK в словарь
Присвоить входной фразе значение K
Перейти к Шагу 2.
Как и в случае с LZ78 для LZW ключевым для размера получаемых кодов является размер словаря во фразах: LZW-коды имеют постоянную длину, равную округленному в большую сторону двоичному логарифму размера словаря.
Пример. Закодировать по алгоритму LZW строку "КРАСНАЯ КРАСКА". Размер словаря - 500 фраз.

В этом примере длина полученного кода равна 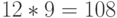 битам.
битам.
При переполнении словаря, т.е. когда необходимо внести новую фразу в полностью заполненный словарь, из него удаляют либо наиболее редко используемую фразу, либо все фразы, отличающиеся от одиночного символа.
Алгоритм LZW является запатентованным и, таким образом, представляет собой интеллектуальную собственность. Его безлицензионное использование особенно на аппаратном уровне может повлечь за собой неприятности.
Любопытна история патентования LZW. Заявку на LZW подали почти одновременно две фирмы - сначала IBM и затем Unisys, но первой была рассмотрена заявка Unisys, которая и получила патент. Однако, еще до патентования LZW был использован в широко известной в мире Unix программе сжатия данных compress.
Упражнение 30 Закодировать сообщения "AABCDAACCCCDBB", "КИБЕРНЕТИКИ" и "СИНЯЯ СИНЕВА СИНИ", вычислить длины в битах полученных кодов, используя алгоритмы,
- LZ77 (словарь - 12 байт, буфер - 4 байта),
- LZ78 (словарь - 16 фраз),
- LZSS (словарь - 12 байт, буфер - 4 байта),
- LZW (словарь - ASCII+ и 16 фраз).
Упражнение 31 Может ли для первого символа сообщения код LZ78 быть короче кода LZW при одинаковых размерах словарей? Обосновать. Для LZW в размер словаря не включать позиции для ASCII+.