|
Добрый день. Я сейчас прохожу курс повышения квалификации - "Профессиональное веб-программирование". Мне нужно получить диплом по этому курсу. Я так полагаю нужно его оплатить чтобы получить диплом о повышении квалификации. Как мне оплатить этот курс?
|
Опубликован: 17.08.2006 | Доступ: свободный | Студентов: 5397 / 712 | Оценка: 4.49 / 3.94 | Длительность: 20:58:00
ISBN: 978-5-9556-0078-9
Специальности: Программист, Архитектор программного обеспечения, Разработчик интернет-проектов
Лекция 7:
Текст, строки и символы
Функции для работы с символами
Иногда требуется работать не со строками и словами текста, а с его отдельными символами. В Perl есть необходимые средства работы с символами, хотя в нем нет специального типа данных, представляющих один символ, подобно типу char в других языках. Один символ из строки можно скопировать функцией substr($string, $index, 1).
С помощью заимствованных из языка Pascal функций ord() и chr() выполняются преобразования символа (а точнее односимвольной строки) в его ASCII-код и наоборот:
$code = ord($char); # ord('M') вернет число 77
$char = chr($code); # chr(77) вернет строку 'M'
# синоним: $char = sprintf("%c", $code);Разбить строку на отдельные символы и поместить их в массив можно с помощью уже знакомой функции split() с пустой строкой в качестве разделителя:
@array_of_char = split('', $string);С помощью списков и нескольких вызовов функции substr() можно поменять в строке местами символы с указанными индексами, например, 1 и 11:
$s = 'кОт видел кИта'; (substr($s, 1, 1), substr($s, 11, 1)) = (substr($s, 11, 1), substr($s, 1, 1)); # в $s будет 'кИт видел кОта'
Известная по лекции о списках функция reverse() в скалярном контексте возвращает значение текстового выражения, в котором символы переставлены в обратном порядке, например:
$palindrom = 'А РОЗА УПАЛА НА ЛАПУ АЗОРА'; $backwards = reverse($palindrom); # в $backwards будет 'АРОЗА УПАЛ АН АЛАПУ АЗОР А'
Обрабатывать отдельные байты, в том числе и символы, можно также при помощи функций pack() и unpack(), которые предназначены для преобразования любых данных и будут рассмотрены в лекции, посвященной вводу-выводу.
Поддержка Unicode
В современном мире уже не работает формула "один символ - это один байт". Необходимость представления текстов, одновременно содержащих символы разных естественных языков, привела к появлению ряда стандартов, часто объединяемых под общим названием Unicode и разработанных международным Консорциумом Unicode. Многочисленные национальные символы языков мира кодируются последовательностями из нескольких байтов. Unicode предлагает несколько форм представления символов в виде форматов преобразования Unicode (Unicode Transformation Format, UTF) и наборов символов Unicode (Unicode Character Set, UCS). Стандарты UCS-2 и UCS-4 представляют из себя кодировки фиксированной длины по два и четыре байта. Из кодировок переменной длины самым популярным стал стандарт UTF-8, использующий для кодирования одного символа от одного до шести байт. Начиная с версии 5.6, Perl поддерживает обработку символов в кодировках Unicode. В Perl применяется кодирование символов последовательностями чисел переменной длины на основе представления UTF-8. Есть возможность записывать многобайтовые (multi-byte) символы в виде литералов, а также выполнять ввод-вывод Unicode-символов.
Для записи в исходной программе символов Unicode в представлении UTF-8 нужно включить обработку строк в этом формате прагмой use utf8. После этого многобайтовые символы могут использоваться наравне с однобайтовыми, например, в качестве ключей в хэшах:
use utf8; # включить поддержку UTF-8
$hash{' 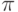 '} = 3.141592653; # пи (код \x{03C0})
print "$hash{' '}\n"; # будет выведено: 3.141592653
'} = 3.141592653; # пи (код \x{03C0})
print "$hash{' '}\n"; # будет выведено: 3.141592653Можно даже использовать национальные алфавиты для записи идентификаторов переменных. Например, кириллицу или греческий:
use utf8; $скаляр = 25; # имя скаляра на русском $= $скаляр + 53; # имя скаляра на греческом print "$скаляр $
Для ввода текста подобной программы понадобится редактор, поддерживающий работу с Unicode. Например, в операционной системе MS Windows это можно сделать с помощью программы Notepad. А в ОС GNU/Linux для редактирования этого текста можно воспользоваться редактором KWrite или Kate. Если такой возможности нет, то символы Unicode можно записывать в программе с помощью escape-последовательностей, о чем было рассказано в "лекции 2" . Примеры escape-кодов для записи символов Unicode приведены во фрагменте программы далее в этой лекции.
Скалярные значения в Perl имеют специальный "признак utf8" (utf8 flag), который устанавливается, когда значение представлено в UTF-8. В этом случае правильно выполняется обработка многобайтовых символов встроенными функциями chr(), index(), length(), ord(), rindex(), substr(). Это видно на таком примере:
use utf8;
$u = "€500"; # знак евро (escape-код \x{20AC})
print "Длина=", length($u), "\n"; # Длина=4
$u = ' 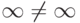 '; # коды \x{221E}, \x{2260}, \x{221E}
print "Бесконечности не равны\n" if $u eq reverse 'infin';
'; # коды \x{221E}, \x{2260}, \x{221E}
print "Бесконечности не равны\n" if $u eq reverse 'infin';Переключить встроенные функции на работу не с символами, а с байтами можно с помощью прагмы use bytes. Снова переключиться на работу функций не с байтами, а с символами можно с помощью прагмы no bytes. Подключив прагмой use Encode стандартный модуль преобразования можно преобразовать обычную строку в строку символов Unicode с помощью функции encode(), возвращающей символьную строку в представлении UTF-8. Обратное преобразование выполняет функция decode():
use Encode;
my $cp1251 = 'Привет!'; # строка в кодировке windows-1251
my $utf8 = encode('utf8', $cp1251); # преобразуется в UTF-8
my $win_ru = decode('utf8', $utf8); # и наоборотПоддержка наборов символов Unicode в Perl имеет свои особенности, связанные с обеспечением совместимости со старыми байт-ориентированными программами, но эти особенности заслуживают отдельного продолжительного разговора за рамками данного учебного курса.
В этой лекции рассмотрены средства работы с символьной информацией в Perl, достаточные для решения типичных задач обработки текста. Но вся прелесть языка Perl и его мощь открываются только тем, кто освоит регулярные выражения, о которых пойдет речь в следующей лекции.
Сергей Крупко
Галина Башкирова
|
Здравствуйте, недавно закончила курс по проф веб программиованию, мне прислали методические указания с примерами тем, однако темы там для специальности Системный администратор информационно-коммуникационных» систем.
|