Инспектор
Вы можете этот курс.
Опубликован: 22.04.2006 | Доступ: платный | Студентов: 7 / 4 | Оценка: 4.27 / 3.83 | Длительность: 26:24:00
ISBN: 978-5-9556-0064-2
Тема: Базы данных
Специальности: Администратор баз данных
Лекция 22:
Рынок инструментов Data Mining
Аннотация: В лекции рассматривается рынок инструментов Data Mining, в частности, его развитие, поставщики инструментов, классификация инструментов. Описаны критерии, по которым можно сравнивать и выбирать инструмент Data Mining.
Ключевые слова: Data, ПО, enterprise data, guide, group, готовое программное обеспечение, библиотека, компонент, поставщик, OLAP, приложение, Дополнение, SAS, SAS Enterprise Miner, СУБД, SQL, server, Oracle, IBM, intelligent, поставщик Data Mining, коммерческий, инструмент, сервер, процент, механизмы, KXEN, cart, forest, свободно распространяемое программное обеспечение, технические характеристики, деление, интуитивный интерфейс, интерфейс, среда передачи, меню, интуитивный, пользователь, экспорта/импорт данных, текстовые файлы, импорт, экспорт, программа, предметной области, Wizard, поддержка, сортировка, функция, конфиденциальная информация, PC, client, рынок инструментов Data Mining, коммерческий инструмент, группа, Text Mining, retrieval, CRISP-DM, PMML, ODM, анализ связей, DCOM, SEMMA, STATISTICA Data Miner, свободно распространяемый, Java, intelligent database, очистка данных, Video Mining, рыночная корзина, визуализатор, свободно распространяемый инструмент, список, персептрон, e-business intelligence
На рынке программного обеспечения Data Mining существует огромное разнообразие продуктов, относящихся к этой категории. И не растеряться в нем достаточно сложно. Для выбора продукта следует тщательно изучить задачи, поставленные перед Вами, и обозначить те результаты, которые необходимо получить.
Приведем цитату из Руководства по приобретению продуктов Data Mining (Enterprise Data Mining Buying Guide) компании Aberdeen Group: "Data Mining - технология добычи полезной информации из баз данных. Однако в связи с существенными различиями между инструментами, опытом и финансовым состоянием поставщиков продуктов, предприятиям необходимо тщательно оценивать предполагаемых разработчиков Data Mining и партнеров".
Существуют различные варианты решений по внедрению инструментов Data Mining, например:
- покупка готового программного обеспечения Data Mining;
- покупка программного обеспечения Data Mining, адаптированного под конкретный бизнес;
- разработка Data Mining-продукта на заказ сторонней компанией;
- разработка Data Mining-продукта своими силами;
- различные комбинации вариантов, описанных выше, в том числе использование различных библиотек, компонентов и инструментальные наборы для разработчиков создания встроенных приложений Data Mining.
В этой лекции мы рассмотрим, что предлагает рынок готового программного обеспечения, в частности, оценим рынок в разрезе задач Data Mining.
Поставщики Data Mining
В начале 90-х годов прошлого столетия рынок Data Mining насчитывал около десяти поставщиков. В средине 90-х число поставщиков, представленных компаниями малого, среднего и большого размера, насчитывало более 50 фирм.
Сейчас к аналитическим технологиям, в том числе к Data Mining, проявляется огромный интерес. На этом рынке работает множество фирм, ориентированных на создание инструментов Data Mining, а также комплексного внедрения Data Mining, OLAP и хранилищ данных. Инструменты Data Mining во многих случаях рассматриваются как составная часть BI-платформ, в состав которых также входят средства построения хранилищ и витрин данных, средства обработки неожиданных запросов (ad-hoc query), средства отчетности (reporting), а также инструменты OLAP.
Разработкой в секторе Data Mining всемирного рынка программного обеспечения заняты как всемирно известные лидеры, так и новые развивающиеся компании. Инструменты Data Mining могут быть представлены либо как самостоятельное приложение, либо как дополнения к основному продукту.
Последний вариант реализуется многими лидерами рынка программного обеспечения. Так, уже стало традицией, что разработчики универсальных статистических пакетов, в дополнение к традиционным методам статистического анализа, включают в пакет определенный набор методов Data Mining. Это такие пакеты как SPSS (SPSS, Clementine), Statistica (StatSoft), SAS Institute (SAS Enterprise Miner). Некоторые разработчики OLAP-решений также предлагают набор методов Data Mining, например, семейство продуктов Cognos. Есть поставщики, включающие Data Mining решения в функциональность СУБД: это Microsoft (Microsoft SQL Server), Oracle, IBM (IBM Intelligent Miner for Data).
Рынок поставщиков Data Mining активно развивается. Постоянно появляются новые фирмы-разработчики и новые инструменты.
Интересными являются данные опроса "Инструменты Data Mining, которые Вы регулярно используете", проведенного в мае 2005 года на Kdnuggets. Его результаты представлены на рис. 22.1.
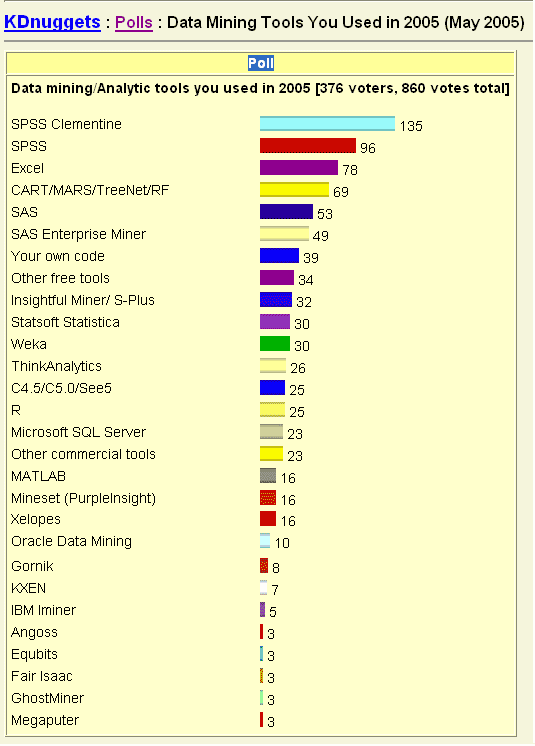
Сравнивая данные этого опроса с подобными опросами 2002 и 2003 годов, можно сказать, что популярность некоторых продуктов возрастает, а некоторых - падает. Это касается как коммерческих, так и свободно распространяемых инструментов. Например, что касается бесплатного инструментария: в 2003 году, по сравнению с 2002 годом, часть голосов от инструмента Weka ушли к инструментам Prudsys Xelopes и R, в 2005 же году количество голосов за инструмент Weka увеличилось, а за Xelopes проголосовало существенно меньше пользователей. Подобный пример можно привести и из коммерческого программного обеспечения: популярность Microsoft Сервер SQL для Data Mining в 2003 году, по сравнению с 2002 годом, возросла, а в 2005 году - снизилась.
Таким же образом изменялись позиции большинства инструментов, но результаты всех трех опросов представлены практически одним и тем же списком поставщиков.
Как видно из опроса, число респондентов вдвое меньше числа голосов, и каждый голосовавший мог выбрать несколько инструментов. Числа, представленные в опросе, означают фактическое число голосов. Процент по каждому инструменту не определяется, поскольку он будет отличаться в зависимости от того, вычислен ли он относительно числа респондентов или от числа голосов.
В комментариях к этому опросу по поводу участия в нем продавцов, редактор сайта отмечает, что при голосовании были использованы механизмы против двойного голосования, но его нельзя считать научным, поскольку за некоторые продукты представители компаний разработчиков голосовали намного более активно, чем за другие (некоторые очевидные двойные голоса продавцов были удалены). Однако эти опросы, по оценкам редактора, действительно дают ощущение разнообразия существующих инструментов Data Mining.
Относительно цен на инструменты, редактор отмечает, что они имеют тенденцию изменяться, а также отличаются по стоимости для бизнес-пользователей и научных работников, так как последние иногда могут получить бесплатную лицензию для исследований.
Представленные выше продукты, согласно предполагаемой цене для бизнес-пользователей на май 2005 года, сгруппированы следующим образом:
- Уровень предприятия: (US $10000 и больше)
- Уровень отдела: (от $1000 до $9999)
Angoss, CART/MARS/TreeNet/Random Forests, Equbits, GhostMiner, Gornik, Mineset, MATLAB, Megaputer, Microsoft SQL Server, Statsoft Statistica, ThinkAnalytics.
- Личный уровень: (от $1 до $999): Excel, See5.
- Свободно распространяемое программное обеспечение: C4.5, R, Weka, Xelopes.
Инструменты Data Mining можно оценивать по различным критериям. Оценка программных средств Data Mining с точки зрения конечного пользователя определяется путем оценки набора его характеристик. Их можно поделить на две группы: бизнес-характеристики и технические характеристики. Это деление является достаточно условным, и некоторые характеристики могут попадать одновременно в обе категории.
Характеристика № 1. Интуитивный интерфейс.
Интерфейс - среда передачи информации между программной средой и пользователем, диалоговая система, которая позволяет передать человеку все необходимые данные, полученные на этапе формализации и вычисления.
Интерфейс подразумевает расположение различных элементов, в т.ч. блоков меню, информационных полей, графических блоков, блоков форм, на экранных формах.
Для удобства работы пользователя необходимо, чтобы интерфейс был интуитивным.
Интуитивный интерфейс позволяет пользователю легко и быстро воспринимать элементы интерфейса, благодаря чему диалог "программная среда-пользователь" становится проще и доступней.
Понятие интуитивного интерфейса включает также понятие знакомой окружающей среды и наличие внятной нетехнической терминологии (например, для сообщения пользователю о совершенной ошибке).
Характеристика № 2. Удобство экспорта/импорта данных.
При работе с инструментом Data Mining-пользователь часто применяет разнообразные наборы данных, работает с различными источниками данных. Это могут быть текстовые файлы, файлы электронных таблиц, файлы баз данных. Инструмент Data Mining должен иметь удобный способ загрузки ( импорта ) данных. По окончании работы пользователь также должен иметь удобный способ выгрузки ( экспорта ) данных в удобную для него среду. Программа должна поддерживать наиболее распространенные форматы данных: txt, dbf, xls, csv и другие.
Дополнительное удобство для пользователя создается при возможности загрузки и выгрузки определенной части (по выбору пользователя) импортируемых или экспортируемых полей.
Характеристика № 3. Наглядность и разнообразие получаемой отчетности
Эта характеристика подразумевает получение отчетности в терминах предметной области, а также в качественно спроектированных выходных формах в том количестве, которое может предоставить пользователю всю необходимую результативную информацию.
Характеристика № 4. Легкость обучения работы с инструментарием
Характеристика № 5. Прозрачные и понятные шаги Data Mining-процесса
Характеристика № 6. Руководство пользователя.Существенно упрощает работу пользователя наличие руководства пользователя, с пошаговым описанием шагов генерации моделей Data Mining.
Характеристика № 7. Удобство и простота использования. Существенно облегчает работу начинающего пользователя возможность использовать Мастер или Визард (Wizard).
Характеристика № 8. Для пользователей, не владеющих английским языком, важной характеристикой является наличие русифицированной версии инструмента, а также документации на русском языке.
Характеристика № 9. Наличие демонстрационной версии с решением конкретного примера.
Характеристика № 10. Возможности визуализации. Наличие графического представления информации существенно облегчает интерпретируемость полученных результатов.
Характеристика № 11. Наличие значений параметров, заданных по умолчанию. Для начинающих пользователей - это достаточно существенная характеристика, так как при выполнении многих алгоритмов от пользователя требуется задание или выбор большого числа параметров. Особенно много их в инструментах, реализующих метод нейронных сетей. В нейросимуляторах чаще всего заранее заданы значения основных параметров, иной раз неопытным пользователям даже не рекомендуется изменять эти значения. Если же такие значения отсутствуют, пользователю приходится перепробовать множество вариантов, прежде чем получить приемлемый результат.
Характеристика № 12. Количество реализуемых методов и алгоритмов. Во многих инструментах Data Mining реализовано сразу несколько методов, позволяющих решать одну или несколько задач. Если для решения одной задачи (классификации) предусмотрена возможность использования нескольких методов (деревьев решений и нейронных сетей), пользователь получает возможность сравнивать характеристики моделей, построенных при помощи этих методов.
Характеристика № 13. Скорость вычислений и скорость представления результатов.
Характеристика № 14. Наличие квалифицированного ассистента (консультации по выбору методов и алгоритмов), консультационная поддержка.
Характеристика № 15. Возможности поиска, сортировки, фильтрации.
Такая возможность полезна как для входных данных, так и для выходной информации. Применяется сортировка по различным критериям (полям), с возможностью накладывания условий.
При условии фильтрации входных данных появляется возможность построения модели Data Mining на одной из выборок набора данных. Необходимость и польза от проведения такого анализа была описана в одной из лекций, посвященных процессу Data Mining. Фильтрация выходной информации полезна с точки зрения интерпретации результатов. Так, например, иногда при построении деревьев решений результаты получаются слишком громоздкими, и здесь могут оказаться полезными функция как фильтрации, так и поиска и сортировки. Дополнительное удобство для пользователя - цветовая подсветка некоторых категорий записей.
Характеристика № 16. Защита, пароль. Очень часто при помощи Data Mining анализируется конфиденциальная информация, поэтому наличие пароля доступа в систему является желательной характеристикой для инструмента.
Характеристика № 17. Платформы, на которых поддерживается работа инструмента, в частности: PC Standalone (95/98/2000/NT), Unix Server, Unix Standalone, PC Client, NT Server.
Описанные характеристики являются критериями функциональности, удобства, безопасности инструмента Data Mining. При выборе инструмента следует руководствоваться потребностями, а также задачами, которые необходимо решить.
Так, например, если точно известно, что фирме необходимо решать исключительно задачи классификации, то возможность решения инструментом других задач совсем не является критичной. Однако, следует учитывать, что внедрение Data Mining при серьезном подходе требует серьезных финансовых вложений, поэтому необходимо учитывать все возможные задачи, которые могут возникнуть в перспективе.