|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Вы можете этот курс.
Опубликован: 20.12.2010 | Доступ: платный | Студентов: 64 / 5 | Оценка: 4.27 / 3.91 | Длительность: 39:39:00
ISBN: 978-5-9963-0353-3
Тема: Базы данных
Специальности: Администратор баз данных
Лекция 9:
Создание физической модели хранилища данных
Аннотация: В настоящей лекции рассматриваются вопросы формирования физической модели хранилища данных, кратко описываются объекты физической базы данных, представлен алгоритм формирования физической модели хранилища данных из логической модели на примере схемы "звезда".
Ключевые слова: таблица, спецификация колонок, ограничения, физические модели данных, команда CREATE TABLE, команда CREATE INDEX, команда ALTER TABLE, индекс, представление, триггер, базовые таблицы, referential integrity, поддержка ссылочной целостности, пользователь, производительность транзакций, стандарт SQL/92, синоним, схема, каталог, кластер, хранимая процедура, synonym, определенные пользователем типы данных, user-defined data type, секция, денежный тип, vary, CHARACTER VARYING, national characters, администратор данных, идентификатор сущности, первичный ключ отношения, таблица-потомок (дочерняя таблица), таблица-родитель (родительская таблица), SET NULL, многомерная модель, префикс номера, database engineering, Типы данных столбцов, CREATE TYPE, sparse, SET DEFAULT, функция секционирования, ограничения на уровне колонки, ограничения на уровне таблицы, ограничения целостности данных, integrity constraints, индекс первичного ключа, составной ключ, БД, СУБД, информация, предметной области, подмножество, SQL, DDL, data definition language, физическая модель, алгоритм
Цель лекции
Изучив материал настоящей лекции, вы будете знать:
- основные объекты, из которых состоит физическая реляционная база данных;
- какие стандартные типы данных предусмотрены для реляционных баз данных;
- как создать таблицу реляционной базы данных;
- как определить спецификацию колонки;
- какие ограничения поддерживаются в реляционных базах данных;
сможете:
- построить физическую модель данных для хранилища данных;
- применять команды SQL CREATE TABLE, CREATE INDEX, ALTER TABLE ;
- определять спецификации колонок ;
и научитесь:
- создавать физическую модель хранилища данных.
Литература: [2], [3], [37], [38].
Объекты физической модели данных
Введение
В предыдущих лекциях мы изучали различные аспекты методов логического проектирования ХД. Методы логического проектирования основываются на абстрактном рассмотрении данных. Логическая модель никак не связана с конкретной реализацией модели в БД СУБД.
На практике ХД создаются и эксплуатируются как БД под управлением конкретной СУБД. БД, реализующие ХД, создаются на основе физической модели данных, разработанной проектировщиком ХД и реализованной в виде объектов БД.
Физическая модель данных, напротив, зависит от конкретной СУБД, в ней содержится информация обо всех объектах базы данных. Поскольку стандартов на объекты базы данных не существует (например, нет стандарта на типы данных), физическая модель зависит от конкретной реализации СУБД и ее диалекта SQL. Следовательно, одной и той же логической модели данных могут соответствовать несколько разных физических моделей.
Основными объектами логической модели данных являются сущности, атрибуты и взаимосвязи. Физическая модель данных, как правило, создается на основе логической, поэтому каждому объекту логической модели соответствует объект физической модели (хотя соответствие может быть неоднозначным). В физической модели данных сущности логической модели данных соответствует таблица, экземпляру сущности – строка в таблице, а атрибуту – колонка таблицы. Кроме перечисленных выше объектов, физическая модель может содержать объекты, тип которых зависит от СУБД: индексы, представления, последовательности, триггеры, процедуры и т.п. Если в логической модели данных не имеет большого значения, какой конкретно тип данных у атрибута, то в физической важно описать всю информацию о конкретных объектах.
Далее, при изложении материала, мы будем предполагать, что имеем дело с реляционными или объектно-реляционными СУБД и соответствующими им диалектами SQL.
Можно выделить два этапа создания физической модели данных [48]. Основными целями первого этапа являются:
- удовлетворение потребности в хранении данных предметной области в рамках реляционной модели данных, т.е. должны быть созданы базовые таблицы для хранения информации обо всех сущностях предметной области;
- удовлетворение требования целостности данных, т.е. должны быть определены типы колонок и наложены ограничения на значения колонок базовых таблиц, которые бы следовали из бизнес-правил предметной области;
- удовлетворение требования ссылочной целостности (referential integrity, RI), т.е. в случае принятия решения о поддержки ссылочной целостности встроенными средствами СУБД должны быть наложены ограничения ссылочной целостности на таблицы, исходя из бизнес-правил ссылочной целостности предметной области;
- удовлетворение (частично) требования независимости представления данных для конечного пользователя от характера физического хранения данных.
На первом этапе в рамках требований реляционной модели создаются объекты хранения данных, соответствующие сущностям и взаимосвязям логической модели данных — таблицы, индексы, представления и т.д.
Главной целью второго этапа является обеспечение требуемого уровня производительности. Для достижения этой цели необходимо учитывать как особенности реализации СУБД, для которой создается физическая модель, так и особенности функционирования будущей информационной системы в целом. Обычно производительность БД измеряется в терминах производительности транзакций (transaction performance).
Для повышения производительности транзакций могут быть модифицированы объекты, созданные на первом этапе, или созданы новые объекты БД. Другими словами, разработка физической модели представляет собой итерационный процесс, причем итераций (создание объектов – анализ транзакций – модификация объектов – анализ транзакций) может быть несколько. Вопросы повышения производительности транзакций будут рассмотрены в одной из следующих лекций.
Иерархия объектов реляционной базы данных
Одной из главных задач, которые обязан решить проектировщик на стадии проектирования физической модели ХД, является задача превращения объектов логической модели данных в объекты реляционной БД. Для решения этой задачи проектировщику необходимо знать: а) какими объектами располагает реляционная база данных в принципе; б) какие объекты поддерживает конкретная СУБД, которая выбрана для реализации базы данных.
Таким образом, мы предполагаем, что решение о выборе СУБД уже принято руководителем ИТ-проекта и согласовано с заказчиком базы данных, т.е. СУБД задана. Проектировщик ХД должен ознакомиться с документацией, в которой описан диалект SQL, поддерживаемый выбранной СУБД. В настоящей лекции предполагается, что была выбрана СУБД семейства MS SQL Server компании Microsoft, хотя подавляющая часть материала охватывает объекты в любой промышленной реляционной СУБД.
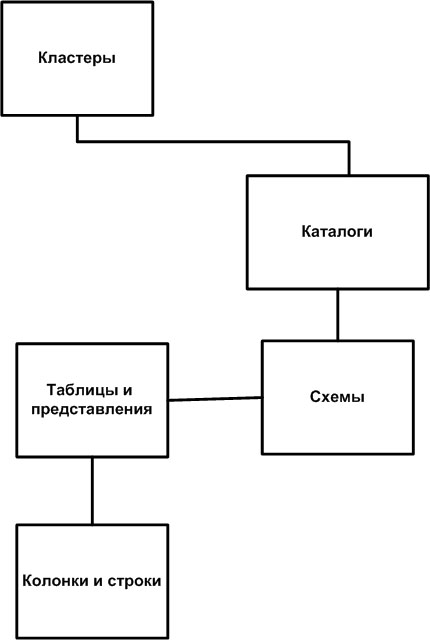
Иерархия объектов реляционной БД прописана в стандартах по SQL, в частности, в стандарте SQL-92, на который мы будем ориентироваться при изложении материала настоящей лекции. Этот стандарт поддерживается практически всеми современными СУБД. Иерархия объектов БД показана на рис. 11.1.
увеличить изображение
Рис. 11.1. Иерархия объектов реляционной базы данных, соответствующая стандарту SQL-92
На самом нижнем уровне находятся объекты, с которыми работает реляционная БД, — столбцы (колонки) и строки. Они, в свою очередь, группируются в таблицы и представления. Заметим, что в контексте лекции атрибуты, колонки, столбцы и поля считаются синонимами. То же относится и к терминам "строка", "запись" и "кортеж".
Таблицы и представления, которые представляют физическое отражение логической структуры БД, собираются в схему. Несколько схем собираются в каталоги, которые затем могут быть сгруппированы в кластеры.
Следует отметить, что ни одна из групп объектов стандарта SQL-92 не связана со структурами физического хранения информации в памяти компьютеров.
Помимо указанных на рисунке объектов в реляционной базе данных могут быть созданы индексы, триггеры, события, хранимые команды, хранимые процедуры и ряд других. Теперь перейдем к определению объектов БД.
Основные объекты реляционной базы данных
Кластеры, каталоги > и схемы не являются обязательными элементами стандарта и, следовательно, программной среды БД.
Под кластером понимается группа каталогов, к которым можно обращаться через одно соединение с сервером базы данных (программная компонента СУБД).
Обычно процедура создания каталога определяется реализацией СУБД на конкретной операционной платформе. Под каталогом понимается группа схем. На практике каталог часто ассоциируется с физической базой данных как набором физических файлов операционной системы, которые идентифицируются ее именем.
Для проектировщика БД схема – это общее логическое представление отношений законченной базы данных. С точки зрения SQL, схема – это контейнер для таблиц, представлений и других структурных элементов реляционной базы данных. Принцип размещения элементов БД в каждой схеме полностью определяется проектировщиком. На практике схема часто ассоциируется с объектами определенного пользователя — владельца физической БД.
Далее объекты БД будут определяться в контексте СУБД MS SQL Server 2005/2008. Такой подход принят потому, что проектирование физической модели БД выполняется для конкретной среды ее реализации.
На MS SQL Sever 2005 схема (Schema) представляет собой коллекцию объектов базы данных: таблиц, представлений, хранимых процедур, триггеров, – формирующих единое пространство имен. Схемы и пользователи являются различными объектами физической БД. У каждой схемы есть владелец – пользователь, или роль (см. ниже).
К числу основных объектов реляционных БД относятся таблица, представление и пользователь.
Таблица (Table) является базовой структурой реляционной БД. Она представляет собой единицу хранения данных — отношение. Таблица представляет собой двумерный массив данных, в котором колонка определяет значение, а строки содержат данные. Таблица идентифицируется в БД своим уникальным именем, которое включает в себя идентификацию пользователя. Таблица может быть пустой или состоять из набора строк.
Представление (View) — это поименованная динамически поддерживаемая СУБД выборка из одной или нескольких таблиц базы данных. Оператор выборки ограничивает видимые пользователем данные. Обычно СУБД гарантирует актуальность представления: его формирование производится каждый раз, когда представление используется. Иногда представления называют виртуальными таблицами.
Пользователь (User) — это объект, обладающий возможностью создавать или использовать другие объекты базы данных и запрашивать выполнение функций СУБД, таких как организация сеанса работы, изменение состояние базы данных и т.д.
Для упрощения идентификации и именования объектов в базе данных поддерживаются такие объекты, как синоним, последовательность и определенные пользователем типы данных.
Синоним (Synonym) — это альтернативное имя (псевдоним) объекта реляционной базы данных, которое позволяет иметь доступ к данному объекту. Синоним может быть общим и частным. Общий синоним позволяет всем пользователям базы данных обращаться к соответствующему объекту по его псевдониму. Синоним позволяет скрыть от конечных пользователей полную квалификацию объекта в базе данных.
Определенные пользователем типы данных (User-defined data types) представляют собой определенные пользователем типы атрибутов (домены), которые отличаются от поддерживаемых (встроенных) СУБД типов. Они определяются на основе встроенных типов.
Правила (Rules) – это декларативные выражения, ограничивающие возможные значения данных. Для формулировки правила используются допустимые предикатные выражения SQL.
Для обеспечения эффективного доступа к данным в реляционных СУБД поддерживается ряд других объектов: индекс, табличная область, кластер, секция.
Индекс (Index) — это объект базы данных, создаваемый для повышения производительности выборки данных и контроля уникальности первичного ключа (если он задан для таблицы).
Секция (Partition) — это объект базы данных, который позволяет представить объект с данными в виде совокупности подобъектов, отнесенных к различным табличным пространствам. Таким образом, секционирование позволяет распределять очень большие таблицы на нескольких жестких дисках.
Для обработки данных специальным образом или для реализации поддержки ссылочной целостности базы данных используются объекты: хранимая процедура, функция, команда, триггер. С помощью этих объектов базы данных можно выполнять так называемую построчную обработку (record processing) данных. С точки зрения приложений баз данных построчная обработка — это последовательная выборка данных по одной строке, ее обработка и переход к обработке следующей строки.
Данные объекты реляционной базы данных представляют собой программы, т.е. исполняемый код. Этого код обычно называют серверным кодом (server-side code), поскольку он выполняется компьютером, на котором установлено ядро реляционной СУБД. Планирование и разработка такого кода является одной из задач проектировщика реляционной базы данных.
Хранимая процедура (Stored procedure) — это объект базы данных, представляющий поименованный набор команд SQL и/или операторов специализированных языков обработки программирования базы данных.
Функция (Function) — это объект базы данных, представляющий поименованный набор команд SQL и/или операторов специализированных языков обработки программирования базы данных, который при выполнении возвращает значение — результат вычислений.
Триггер (Trigger) — это объект базы данных, который представляет собой специальную хранимую процедуру. Эта процедура запускается автоматически, когда происходит связанное с триггером событие (например, вставка строки в таблицу ).
Для эффективного управления разграничением доступа к данным поддерживается объект роль.
Роль (Role) – объект базы данных, представляющий собой поименованную совокупность привилегий, которые могут назначаться пользователям, категориям пользователей или другим ролям.
Домены в физической модели данных
В логической модели данных среда реализации не учитывается. В ней определяются атрибуты и их возможные значения, такие как строка, число или дата, в идеале атрибуту может назначаться домен. Домен — это просто тип атрибута, например, "Деньги" или "Рабочий день". Проектировщик может включить ряд проверок допустимости или правил обработки, например, требование, что значение должно быть положительным, ненулевым и иметь максимум два десятичных разряда (это полезно для вычисления сумм рублевых платежей, выставляемых банком на другой банк).
Использование доменов упрощает задачу обеспечения непротиворечивости на стадии логической модели данных. При переходе к проектированию физической модели данных проектировщику необходимо знать возможности выбранной СУБД по назначению типов данных колонок. В логической модели данных значения, которые может принимать атрибут отношения, также задаются доменом, который наследуется из информационной модели. В физической модели базы данных требуется, чтобы каждый атрибут отношения в базе данных обладал рядом свойств, которые диктуют, что в нем может храниться и что не может. Этими свойствами являются тип, размер и ограничения, которые могут еще более ограничивать допустимый набор значений столбца. Задача состоит в преобразовании домена в подходящий тип данных, поддерживаемый СУБД. Таким образом, проектировщик должен знать, какими типами данных он располагает при решении вышеуказанной задачи.
В контексте проектирования физической модели реляционной БД домен – это выражение, определяющее разрешенные значения для колонок (атрибутов) отношения. При описании таблицы реляционной БД каждой колонке назначается определенный тип данных. Практически, основу определения домена составляет тип данных, содержащихся в колонке, поскольку большинство встроенных типов задают разрешенный интервал значений данных.
Пример 11.1. Колонку в базе данных можно описать следующим образом:
amount NUMBER (8,2) NOT NULL CONSTRAINT cc_limit_amnt CHECK (amount > 0)
В колонке "Сумма платежа" ( Amount ) можно размещать только числовые данные; точность этого значения — два значащих десятичных разряда ( NUMBER (8,2) ); она должна быть заполнена для каждой строки таблицы ( NOT NULL ); ее значение должно быть положительным CONSTRAINT cc_limit_amnt CHECK (amount > 0). Максимальное значение, которое может храниться в этом столбце, — 999999.99. В этом простом определении колонки мы фактически определили ряд неявных правил, проверку которых MS SQL Server принудительно включает при вводе данных в БД.
Как видно, дальнейшее определение домена колонки (после присвоения ей типа) выполняется проектировщиком с помощью уточнений правил изменения значений. Такие уточнения поддерживаются в SQL с помощью механизма ограничений в спецификации колонки в таблице.
В стандарт SQL-92 введено понятие доменов, определенных пользователем. Определение таких доменов базируется на встроенных типах данных СУБД.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|