Основные конструкции OpenMP
Основные принципы OpenMP
OpenMP - это интерфейс прикладного программирования для создания многопоточных приложений, предназначенных в основном для параллельных вычислительных систем с общей памятью. OpenMP состоит из набора директив для компиляторов и библиотек специальных функций. Стандарты OpenMP разрабатывались в течение последних 15 лет применительно к архитектурам с общей памятью. Описание стандартов OpenMP и их реализации при программировании на алгоритмических языках Fortran и C/C++ можно найти в [2.1-2.6]. Наиболее полно вопросы программирования на OpenMP рассмотрены в монографиях [2.7-2.8]. В последние годы весьма активно разрабатывается расширение стандартов OpenMP для параллельных вычислительных систем с распределенной памятью (см., например, работы [2.9]). В конце 2005 года компания Intel анонсировала продукт Cluster OpenMP, реализующий расширение OpenMP для вычислительных систем с распределенной памятью. Этот продукт позволяет объявлять области данных, доступные всем узлам кластера, и осуществлять передачу данных между узлами кластера неявно с помощью протокола Lazy Release Consistency.
OpenMP позволяет легко и быстро создавать многопоточные приложения на алгоритмических языках Fortran и C/C++. При этом директивы OpenMP аналогичны директивам препроцессора для языка C/C++ и являются аналогом комментариев в алгоритмическом языке Fortran. Это позволяет в любой момент разработки параллельной реализации программного продукта при необходимости вернуться к последовательному варианту программы.
В настоящее время OpenMP поддерживается большинством разработчиков параллельных вычислительных систем: компаниями Intel, Hewlett-Packard, Silicon Graphics, Sun, IBM, Fujitsu, Hitachi, Siemens, Bull и другими. Многие известные компании в области разработки системного программного обеспечения также уделяют значительное внимание разработке системного программного обеспечения с OpenMP. Среди этих компаний отметим Intel, KAI, PGI, PSR, APR, Absoft и некоторые другие. Значительное число компаний и научно-исследовательских организаций, разрабатывающих прикладное программное обеспечение, в настоящее время использует OpenMP при разработке своих программных продуктов. Среди этих компаний и организаций отметим ANSYS, Fluent, Oxford Molecular, NAG, DOE ASCI, Dash, Livermore Software, а также и российские компании ТЕСИС, Центральную геофизическую экспедицию и российские научно-исследовательские организации, такие как Институт математического моделирования РАН, Институт прикладной математики им. Келдыша РАН, Вычислительный центр РАН, Научно-исследовательский вычислительный центр МГУ, Институт химической физики РАН и другие.
Принципиальная схема программирования в OpenMP
Любая программа, последовательная или параллельная, состоит из набора областей двух типов: последовательных областей и областей распараллеливания. При выполнении последовательных областей порождается только один главный поток (процесс). В этом же потоке инициируется выполнение программы, а также происходит ее завершение. В последовательной программе в областях распараллеливания порождается также только один, главный поток, и этот поток является единственным на протяжении выполнения всей программы. В параллельной программе в областях распараллеливания порождается целый ряд параллельных потоков. Порожденные параллельные потоки могут выполняться как на разных процессорах, так и на одном процессоре вычислительной системы. В последнем случае параллельные процессы (потоки) конкурируют между собой за доступ к процессору. Управление конкуренцией осуществляется планировщиком операционной системы с помощью специальных алгоритмов. В операционной системе Linux планировщик задач осуществляет обработку процессов с помощью стандартного карусельного ( round-robin ) алгоритма. При этом только администраторы системы имеют возможность изменить или заменить этот алгоритм системными средствами. Таким образом, в параллельных программах в областях распараллеливания выполняется ряд параллельных потоков. Принципиальная схема параллельной программы изображена на рис.2.1.
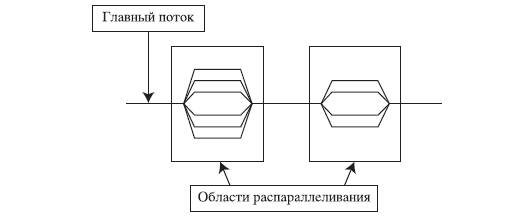
При выполнении параллельной программы работа начинается с инициализации и выполнения главного потока (процесса), который по мере необходимости создает и выполняет параллельные потоки, передавая им необходимые данные. Параллельные потоки из одной параллельной области программы могут выполняться как независимо друг от друга, так и с пересылкой и получением сообщений от других параллельных потоков. Последнее обстоятельство усложняет разработку программы, поскольку в этом случае программисту приходится заниматься планированием, организацией и синхронизацией посылки сообщений между параллельными потоками. Таким образом, при разработке параллельной программы желательно выделять такие области распараллеливания, в которых можно организовать выполнение независимых параллельных потоков. Для обмена данными между параллельными процессами (потоками) в OpenMP используются общие переменные. При обращении к общим переменным в различных параллельных потоках возможно возникновение конфликтных ситуаций при доступе к данным. Для предотвращения конфликтов можно воспользоваться процедурой синхронизации ( synchronization ). При этом надо иметь в виду, что процедура синхронизации - очень дорогая операция по временным затратам и желательно по возможности избегать ее или применять как можно реже. Для этого необходимо очень тщательно продумывать структуру данных программы.
Выполнение параллельных потоков в параллельной области программы начинается с их инициализации. Она заключается в создании дескрипторов порождаемых потоков и копировании всех данных из области данных главного потока в области данных создаваемых параллельных потоков. Эта операция чрезвычайно трудоемка - она эквивалентна примерно трудоемкости 1000 операций. Эта оценка чрезвычайно важна при разработке параллельных программ c помощью OpenMP, поскольку ее игнорирование ведет к созданию неэффективных параллельных программ, которые оказываются зачастую медленнее их последовательных аналогов. В самом деле: для того чтобы получить выигрыш в быстродействии параллельной программы, необходимо, чтобы трудоемкость параллельных процессов в областях распараллеливания программы существенно превосходила бы трудоемкость порождения параллельных потоков. В противном случае никакого выигрыша по быстродействию получить не удастся, а зачастую можно оказаться даже и в проигрыше.
После завершения выполнения параллельных потоков управление программой вновь передается главному потоку. При этом возникает проблема корректной передачи данных от параллельных потоков главному. Здесь важную роль играет синхронизация завершения работы параллельных потоков, поскольку в силу целого ряда обстоятельств время выполнения даже одинаковых по трудоемкости параллельных потоков непредсказуемо (оно определяется как историей конкуренции параллельных процессов, так и текущим состоянием вычислительной системы). При выполнении операции синхронизации параллельные потоки, уже завершившие свое выполнение, простаивают и ожидают завершения работы самого последнего потока. Естественно, при этом неизбежна потеря эффективности работы параллельной программы. Кроме того, операция синхронизации имеет трудоемкость, сравнимую с трудоемкостью инициализации параллельных потоков, т. е. эквивалентна примерно трудоемкости выполнения 1000 операций.
На основании изложенного выше можно сделать следующий важный вывод: при выделении параллельных областей программы и разработке параллельных процессов необходимо, чтобы трудоемкость параллельных процессов была не менее 2000 операций деления. В противном случае параллельный вариант программы будет проигрывать в быстродействии последовательной программе. Для эффективной работающей параллельной программы этот предел должен быть существенно превышен.
Синтаксис директив в OpenMP
Основные конструкции OpenMP - это директивы компилятора или прагмы (директивы препроцессора) языка C/C++. Ниже приведен общий вид директивы OpenMP прагмы.
#pragma omp конструкция [предложение [предложение] … ]2.2. Общий вид OpenMP прагмы языка C/C++
В языке Fortran директивы OpenMP являются строками-комментариями специального типа. Ниже в примере 2.3 приведены примеры таких строк в общем виде. Для обычных последовательных программ директивы OpenMP не изменяют структуру и последовательность выполнения операторов. Таким образом, обычная последовательная программа сохраняет свою работоспособность. В этом и состоит гибкость распараллеливания с помощью OpenMP.
Большинство директив OpenMP применяется к структурным блокам. Структурные блоки - это последовательности операторов с одной точкой входа в начале блока и одной точкой выхода в конце блока.
c$omp конструкция [предложение [предложение] … ] !$omp конструкция [предложение [предложение] … ] *$omp конструкция [предложение [предложение] … ]2.3. Общий вид директив OpenMP в программе на языке Fortran
В примерах 2.4 и 2.5 показаны примеры структурного и неструктурного блоков соответственно во фрагментах программ, написанных на языке Fortran. Видно, что в первом примере рассматриваемый блок является структурным, поскольку имеет одну точку входа и одну точку выхода. Во втором примере рассматриваемый блок не является структурным, поскольку имеет две точки входа. Следовательно, использование конструкций OpenMP для его распараллеливания некорректно. Из этих примеров видно, что директивы OpenMP, применяемые к структурным блокам, аналогичны операторным скобкам begin и end в алгоритмических языках Algol и Pascal.
c$omp parallel
10 wrk (id) = junk (id)
res (id) = wrk (id)**2
if (conv (res)) goto 10
c$omp end parallel
print *, id
2.4.
Пример структурного блока в программе на языке Fortran
c$omp parallel
10 wrk (id) = junk (id)
30 res (id) = wrk (id)**2
if (conv (res)) goto 20
goto 10
c$omp end parallel
if (not_done) goto 30
20 print *, id
2.5.
Пример неструктурного блока в программе на языке Fortran
В следующем фрагменте программы (Пример 2.6) показан общий вид основных директив OpenMP на языке Fortran.
c$omp parallel
c$omp& shared (var1, var2, …)
c$omp& private (var1, var2, …)
c$omp& firstprivate (var1, var2, …)
c$omp& lastprivate (var1, var2, …)
c$omp& reduction (operator | intrinsic: var1, var2, …)
c$omp& if (expression)
c$omp& default (private | shared | none)
[Структурный блок программы]
c$omp end parallel
2.6.
Общий вид основных директив OpenMP на языке Fortran
В рассматриваемом фрагменте предложение OpenMP shared используется для описания общих переменных. Как уже отмечалось ранее, общие переменные позволяют организовать обмен данными между параллельными процессами в OpenMP. Предложение private используется для описания внутренних (локальных) переменных для каждого параллельного процесса. Предложение firstprivate применяется для описания внутренних переменных параллельных процессов, однако данные в эти переменные импортируются из главного потока. Предложение reduction позволяет собрать вместе в главном потоке результаты вычислений частичных сумм, разностей и т. п. из параллельных потоков. Предложение if является условным оператором в параллельном блоке. И, наконец, предложение default определяет по умолчанию тип всех переменных в последующем параллельном структурном блоке программы. Далее механизм работы этих предложений будет рассмотрен более подробно. В заключение отметим, что символ амперсанд &в шестой позиции строки используется для продолжения длинных директив OpenMP, не умещающихся на одной строке в программах на Fortran (см. рис.2.6).
Ниже во фрагменте программы (Пример 2.7) приведен общий вид основных директив OpenMP на языке C/C++.
# pragma omp parallel \
private (var1, var2, …) \
shared (var1, var2, …) \
firstprivate (var1, var2, …) \
lastprivate (var1, var2, …) \
copyin (var1, var2, …) \
reduction (operator: var1, var 2, …) \
if (expression) \
default (shared | none) \
{
[ Структурный блок программы]
}
2.7.
Общий вид основных директив OpenMP на языке C/C++
По сравнению с предыдущим, в рассматриваемом фрагменте появилось еще одно дополнительное предложение OpenMP - copyin. Оно позволяет легко и просто передавать данные из главного потока в параллельные. В Fortran также существует аналогичная возможность, однако механизм ее реализации несколько иной. Подробнее эти возможности будут рассмотрены далее. Кроме того, отметим, что вместо Fortran-директивы OpenMP
c$omp end parallel
в C/C++ используются обычные фигурные скобки. Для продолжения длинных директив на следующих строках в программах на C/C++ применяется символ "обратный слэш" в конце строки (см. пример 2.7).
Рассмотренные в настоящем разделе директивы OpenMP не охватывают весь спектр директив. В следующих разделах рассмотрим более подробно основные директивы OpenMP и механизм их работы.