|
Видеокурс выложен на сайте Altube.ru вместо Youtube и плеер Altube не поддерживает субтитры. Прошу решить вопрос о предоставлении русских субтитров в этом англоязычном видеокурсе. |
Опубликован: 14.06.2015 | Доступ: свободный | Студентов: 7805 / 1316 | Длительность: 09:49:00
Авторские права: Creative Commons Attribution 3.0
Специальности: Программист, Разработчик интернет-проектов, Преподаватель
Самостоятельная работа 12:
Использование Веб-служб
Ключевые слова: ПО, HTTP, HTML, сеть, XML, markup, language, тег, phone, программа, представление, дерево, функция, hide, анализ, синтаксис, список, USER, имя пользователя, идентификатор, значение, протокол передачи гипертекста, обмен данными, определение, документирование, application programming, API, доступ, service, architecture, SOA, приложение, stand-alone, сайт, пользователь, сетевой сервис, архитектура, производительность, twitter, команда, интерфейс, браузер, URL, status, очередь, application program, interface, язык разметки, State, transfer
По ссылке youtube выложено видео с русскими титрами.
Поскольку несложно получать HTTP-документы по сети и осуществлять их разбор с помощью специальных программ, естественно применить подход, при котором создаются документы, предназначенные для других программ (не имеется в виду HTML, который показывается браузером). Чаще всего, когда две сетевые программы обмениваются данными через сеть, они используют формат данных, который называется "Расширяемым языком разметки" или XML (eXtensible Markup Language).
26.1. Расширяемый язык разметки – XML
XML похож на HTML, но более четко структурирован. Вот пример XML-документа:
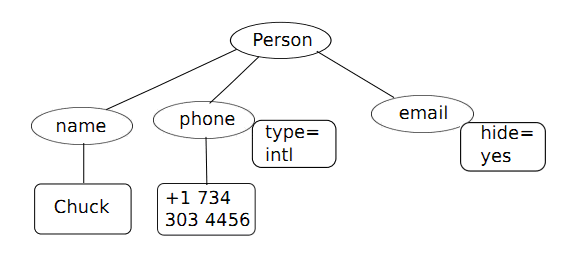
<person> <name>Chuck</name> <phone type="intl"> +1 734 303 4456 </phone> <email hide="yes"/> </person>
Часто полезно представлять XML-документ как имеющий структуру дерева, например, в данном случае тег верхнего уровня (корневой тег) – это person, остальные теги, такие, как phone, изображаются как дети своих родительских узлов.
26.2. Разбор XML
Ниже приведена несложная программа, которая осуществляет разбор XML-документа и извлекает из него некоторые элементы:
import xml.etree.ElementTree as ET
data = '''
<person>
<name>Chuck</name>
<phone type="intl">
+1 734 303 4456
</phone>
<email hide="yes"/>
</person>'''
tree = ET.fromstring(data)
print 'Name:',tree.find('name').text
print 'Attr:',tree.find('email').get('hide')
Метод fromstring преобразует строковое представление XML-документа в дерево XML-узлов. Когда XML-документ уже представлен в виде дерева, есть целая серия методов для извлечения порций данных из него.
Функция find просматривает дерево XML и извлекает узел, который соответствует указанному тегу. Каждый узел может иметь некоторый текст, а также атрибуты (например, аттрибут "hide" – "скрыть") и "детские" узлы.
Каждый узел можно рассматривать как корень поддерева, выходящего из него.
Name: Chuck Attr: yes
Использование XML-парсера (т.е. программы, осуществляющей разбор и синтаксический анализ XML-текста), такого, как ElementTree, имеет то преимущество, что, несмотря на простоту рассмотренного примера, синтаксис XML подчиняется множеству правил, и использование ElementTree позволяет нам извлекать данные из XML-документа, не тратя время на изучение синтаксиса XML.
26.3. Циклы по узлам
Часто XML имеет многочисленные однотипные узлы, и нам приходится писать циклы, чтобы обрабатывать их. В следующем примере в цикле перебираются все узлы, соответствующие тегу user:
import xml.etree.ElementTree as ET
input = '''
<stuff>
<users>
<user x="2">
<id>001</id>
<name>Chuck</name>
</user>
<user x="7">
<id>009</id>
<name>Brent</name>
</user>
</users>
</stuff>'''
stuff = ET.fromstring(input)
lst = stuff.findall('users/user')
print 'User count:', len(lst)
for item in lst:
print 'Name', item.find('name').text
print 'Id', item.find('id').text
print 'Attribute', item.get('x')
Метод findall извлекает из документа, представленного в виде XML-дерева, список поддеревьев, корни которых являются узлами, соответствующими тегу user. Затем мы используем цикл for, который для каждого узла user печатает имя пользователя (имя содержится в узле name, который является непосредственным потомком узла user) и идентификатор (узел id), а также значение атрибута x узла user.
User count: 2 Name Chuck Id 001 Attribute 2 Name Brent Id 009 Attribute 7
Алексей Виноградов
Петр Олейников
|
Данные файлы неоходимы не только для самостоятельных работ, но и для тестов. А по ссылкам в лекциях они не доступны, выдает ошибку 404. |