Инспектор
Вы можете этот курс.
Опубликован: 22.04.2006 | Доступ: платный | Студентов: 427 / 49 | Оценка: 4.27 / 3.83 | Длительность: 26:24:00
ISBN: 978-5-9556-0064-2
Тема: Базы данных
Специальности: Администратор баз данных
Лекция 27:
Инструмент KXEN
Аннотация: Рассматривается программное обеспечение KXEN. Указываются отличия подхода KXEN от традиционного подхода Data Mining. Исследуются предпосылки создания системы KXEN и ее технические характеристики. Описаны ключевые компоненты системы KXEN. Разобрана технология IOLAP.
Ключевые слова: Data Mining, KXEN, knowledge, извлечение знаний, эволюция Data Mining, реинжиниринг аналитического процесса, бизнес-моделирование KXEN , анализ, операции, PMML, AWK, SAS, minimize, data manipulation, партнерство, компонентная архитектура, переобучение, IOLAP
Мы продолжаем изучение ведущих мировых производителей программного обеспечения Data Mining. В этой лекции мы остановимся на программном обеспечении KXEN, которое является разработкой одноименной французско-американской компании [116], работающей на рынке с 1998 года. Аббревиатура KXEN означает "Knowledge eXtraction Engines" - инструменты ("движки") для извлечения знаний.
Сразу следует сказать, что разработка KXEN имеет особый подход к анализу данных [117]. В KXEN нет деревьев решений, нейронных сетей и других популярных техник.
KXEN - это инструмент для моделирования, который позволяет говорить об эволюции Data Mining и реинжиниринге аналитического процесса в организации в целом.
В основе этих утверждений лежат достижения современной математики и принципиально иной подход к изучению явлений в бизнесе.
Следует отметить, что все происходящее внутри KXEN сильно отличается (по крайней мере, по своей философии) от того, что мы привыкли считать традиционным Data Mining.
Бизнес-моделирование KXEN - это анализ деятельности компании и ее окружения путем построения математических моделей. Он используется в тех случаях, когда необходимо понять взаимосвязь между различными событиями и выявить ключевые движущие силы и закономерности в поведении интересующих нас объектов или процессов.
KXEN охватывает четыре основных типа аналитических задач:
- Задачи регрессии/классификации (в т.ч. определение вкладов переменных);
- Задачи сегментации/кластеризации;
- Анализ временных рядов;
- Поиск ассоциативных правил (анализ потребительской корзины).
Построенная модель в результате становится механизмом анализа, т.е. частью бизнес-процесса организации. Главная идея здесь - на основе построенных моделей создать систему "сквозного" анализа происходящих процессов, позволяющую автоматически производить их оценку и строить прогнозы в режиме реального времени (по мере того, как те или иные операции фиксируются учетными системами организации).
Реинжиниринг аналитического процесса
Использование в качестве инструмента для моделирования программного обеспечения KXEN предлагает усовершенствовать аналитический процесс, устранив трудности, часто возникающие в процессе поиска закономерностей, среди которых: трудоемкость подготовки данных; сложность выбора переменных, включенных в модель; требования к квалификации аналитиков; сложность интерпретации полученных результатов; сложность построения моделей. Эти и другие проблемы были нами рассмотрены на протяжении курса лекций.
Особенность KXEN заключается в том, что заложенный в него математический аппарат (на основе Теории минимизации структурного риска Владимира Вапника) позволяет практически полностью автоматизировать процесс построения моделей и на порядок увеличить скорость проводимого анализа. Отличия традиционного процесса Data Mining и подхода KXEN приведены на рис. 27.1.
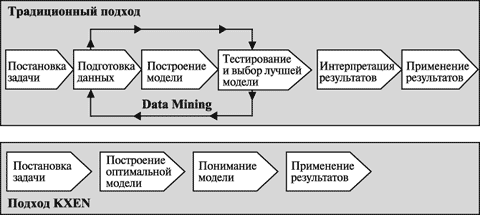
Таким образом, построение модели в KXEN из исследовательского проекта превращается в функцию предсказательного анализа в режиме on-line в формате "вопрос-ответ". Причем ответы даются в тех же терминах, в которых был сформулирован вопрос, и задача пользователя сводится к тому, чтобы задавать нужные вопросы и указывать данные для анализа.
Среди преимуществ KXEN можно назвать:
- Удобная и безопасная работа с данными: данные никуда не перегружаются, KXEN обрабатывает их строка за строкой (текстовые файлы или интеграция с DB2, Oracle и MS SQL Server, в т.ч. через ODBC);
- Наглядность результатов моделирования, легкость для понимания: графическое отображение моделей + score-карты;
- Широкие возможности применения моделей: автоматическая генерация кода моделей на языках С++, XML, PMML, HTML, AWK, SQL, JAVA, VB, SAS, при этом модель сможет работать автономно.
Технические характеристики продукта
KXEN Analytic FrameworkTM представляет собой набор описательных и предсказательных аналитических модулей, которые можно скомбинировать в зависимости от задачи заказчика. KXEN не является закрытым приложением, он встраивается в существующие системы организации, благодаря открытым программным интерфейсам. Поэтому форма представления результатов анализа, с которой будут работать сотрудники на местах, может определяться пожеланиями Заказчика и особенностями его бизнес-процесса.
Средства KXEN представляют собой приложения в архитектуре Клиент/сервер. Сервер KXEN осуществляет жизненный цикл модели - построение, обучение, корректировку, использование новых данных. С Клиентов осуществляется управление указанными процессами. Могут быть использованы стандартные клиентские рабочие места, поставляемые KXEN, или разработаны новые под конкретные задачи. Клиентское программное обеспечение KXEN поставляется с исходными кодами и может быть модифицировано или взято в качестве основы для собственной разработки.
Цель дальнейшего материала - познакомить студента с логическими доводами и соображениями, которые легли в основу создания KXEN.
Этот материал будет, в первую очередь, полезен с точки зрения выбора инструментов и методов предсказательного анализа для решения бизнес-задач. Он поможет произвести оценку KXEN и сопоставить его с традиционными решениями в области Data Mining.
Следует отметить, что для работы с KXEN от пользователя не требуется специальной квалификации и знаний в области анализа и статистики. От него требуются данные, которые требуется проанализировать, и определение типа задачи, которую нужно решить. Имеются в виду задачи описательного или предсказательного анализа или, говоря техническим языком, задачи классификации, регрессии или кластеризации.