![Внутренняя архитектура транспьютера IMS T800 и формат инструкции [267]](/EDI/04_03_16_3/1457043730-16689/tutorial/594/objects/2/files/02_01.gif)
![Связный список процессов [267]](/EDI/04_03_16_3/1457043730-16689/tutorial/594/objects/2/files/02_02.gif)
![Нисходящее иерархическое проектирование матричных структур [70]](/EDI/04_03_16_3/1457043730-16689/tutorial/594/objects/2/files/02_03.gif)
![Структура инструментальных платформ пользователя матричных процессоров [70]](/EDI/04_03_16_3/1457043730-16689/tutorial/594/objects/2/files/02_04.gif)
|
Добрый день!
Скажите, пожалуйста,планируется ли продолжение курсов по нанотехнологиям? Спасибо, Евгений
|
Инспектор
Вы можете этот курс.
Опубликован: 01.10.2013 | Доступ: платный | Студентов: 24 / 2 | Длительность: 24:58:00
ISBN: 978-5-9963-0223-9
Темы: САПР, Аппаратное обеспечение, Нанотехнологии
Специальности: Разработчик аппаратуры
Лекция 3:
Особенности использования программных инструментальных платформ параллельных вычислительных систем общего назначения
Аннотация: В лекции раскрыты особенности построения и использования программных инструментальных платформ параллельных вычислительных систем общего назначения.
Ключевые слова: последовательный алгоритм, место, архитектура, язык высокого уровня, Лисп-процессор, реконфигурация, алгоритм, систолическая матрица, транспьютер, ВС, запуск, ОЗУ, регистр, поле, операнд, инструкция, дополнительный код, транспьютерная технология, процессор, планировщик , ПО, транспьютерная сеть, указатель, счетчик команд, процессорное время, режим ожидания, таймер, список, IMS, адресная арифметика, адрес, стек, диаграмма, декомпозиция, физическая система, цикл разработки, конфигурирование, сеть, компоновка, связь, время выполнения, конструирование, фирма, режим реального времени, модульность, параллелизм, вывод, стоимость, точность, компилятор, граф, восходящее проектирование, верифицируемость, отображение, пространство, поток, массив, опыт, предметной области, обработка сигналов, Sisal, AND, assignment, language, цикла, информация, интерактивный режим, оператор присваивания, анализ, прагматика, квазипараллелизм, исполнение, программа, разбиение, механизмы, Java, программирование, многозадачность, планировщик задач, единица, поддержка, многопоточная система, класс, приоритет потока, значение, доступ, файл, управление доступом, объект, тип данных, определение, делегаты, вызов метода, роли сотрудников, операции, плоскость, статический метод, очереди сообщений, диаграммы классов, компонент, enterprise, library, интерфейс, представление, блок-схема, структура данных, состояние процесса, активный, моделирование
2.1. Методы и средства представления и поддержки параллелизма
Использование параллельных вычислительных систем сопряжено с целым рядом проблем, связанных с представлением и поддержкой параллелизма, потому что пока не удалось найти формальные методы, способные эффективно вскрывать имеющийся в последовательном алгоритме потенциальный уровень распараллеливания каждой фазы вычислений, а тем более распределять между процессорами вытекающую из него вычислительную нагрузку. Поэтому процесс проектирования параллельных программ и реализующих их систем был и пока остается интерактивным. В таких условиях остается только предоставить программисту эффективные языковые средства и инструментальные платформы, обеспечивающие отладку и загрузку параллельных программ в существующую или создаваемую многопроцессорную систему. Языки параллельного программирования и их инструментальные платформы отталкиваются от архитектурных особенностей поддержки параллелизма в аппаратной платформе и поэтому не могут быть универсальными, так как выразительные и исполнительные средства - две стороны одной медали. Отсюда, либо аппаратная платформа разрабатывается под заранее заданный язык параллельного программирования, как это имеет место в транспьютерах [267], архитектура которых ориентирована на язык высокого уровня ОККАМ, либо для аппаратной платформы пишется узкоспециализированный язык, что характерно для спецпроцессоров. Аналогичная с ОККАМ ситуация складывалась и в случае ПРОЛОГ- и ЛИСП-процессоров, процессоров баз данных и баз знаний, которая была характерна для японской микроэлектроники 80-х годов прошлого столетия [278].
Все инструментальные платформы для параллельных вычислителей можно разбить на две группы: одни ориентированы на использование уже существующих аппаратных платформ, а вторые - на их создание. В первом случае допускается только специфицированная реконфигурация аппаратной платформы под требования вычислительного алгоритма пользователя, что характерно для транспьютерных систем [267], а во втором случае вычислительный алгоритм известен и требуется методами и средствами (полу)заказного проектирования синтезировать аппаратуру его поддержки, что характерно для систолических матриц [70].
Типичная архитектура транспьютера (рис. 2.1) ориентирована на многопроцессорные ВС МКМД-типа с массовыми пересылками данных и управляемыми потоками данных, в которых запуск инструкции осуществляется при наличии обрабатываемых операндов. При этом для выравнивания скоростей обработки и пересылки данных каждый транспьютер, исполненный в виде отдельной СБИС, содержит встроенное ОЗУ, функции которого сходны с функциями кеш-памяти в современных процессорах общего назначения. Объясняется это тем, что внутренняя пересылка ОЗУ - регистр выполняется гораздо быстрее любой внешней пересылки, что характерно для всех без исключения микроэлектронных технологий.
Ассемблерные инструкции транспьютера рассчитаны на разработку программ, написанных на языке высокого уровня ОККАМ. Как и в RISC -технологиях, для эффективной компиляции программ набор ассемблерных инструкций сокращен до минимума и все они имеют одинаковый формат (см. рис. 2.1), в котором выделено поле для кода функции и для данных. Для увеличения разрядности преобразуемых операндов в языке ОККАМ предусмотрены две префиксные конструкции: prefix и negative prefix, первая из которых сдвигает влево на четыре разряда четырехбитный операнд, загруженный в регистр операнда. Вторая инструкция делает то же самое, но предварительно преобразует содержимое пересылаемых данных в дополнительный код.
Одна из главных особенностей аппаратной платформы транспьютерных технологий состоит в том, что каждый процессор имеет микропрограммный планировщик, который позволяет выполнить любое число процессов в режиме разделения времени. Такая распределенная по транспьютерной сети система управления позволяет обходиться без ядра операционной системы, но налагает на программиста ряд дополнительных функций, связанных с организацией параллельных процессов.
В одном из первых транспьютеров IMS T800 каждый последовательный процесс поддерживался всего шестью регистрами (рис. 2.2), что упростило логику управления и повысило скорость работы каналов при обмене с внутренним ОЗУ. Три регистра A, B и C реализуют механизм аппаратного стека с "вершиной" в A и являются приемниками и источниками для большинства арифметико-логических операций транспьютера. В трех оставшихся регистрах хранятся соответственно указатель области памяти с локальными переменными, указатель на следующую команду (счетчик команд) и наращиваемый с помощью prefix и negative prefix операнд. Все команды оперируют только с вершиной стека, и поэтому нет необходимости переопределять положение операндов инструкций по ходу вычислений.
Каждый последовательный процесс, включенный в состав параллельного, может находиться в следующих состояниях:
- активен: выполняется или находится в очереди на выполнение;
- пассивен: готов к вводу, готов к выводу, ожидает, когда наступит ука занное время.
Микропрограммный планировщик IMS T800 устроен так, что пассивные процессы не занимают процессорное время, а активные, ожидающие процессы находятся в списке рабочих областей процессов, который поддерживается двумя регистрами (см. рис. 2.2): один указывает на первый процесс из списка, а второй - на последний. В нашем случае процесс S исполняется, а процессы P, Q и R активны, но ожидают выполнения.
Каждый последовательный процесс выполняется до тех пор, пока не перейдет в режим ожидания ввода, вывода или таймера, что как раз и соответствует идеологии управления потоками данных. Как только процесс не может исполняться, его счетчик команд сохраняется в рабочей области и выбирается следующий процесс из списка для выполнения. Как видно из схемы рис. 2.2, "цена" такого прерывания - 12 пересылок, обновляющих содержимое 6 регистров с сохранением предыдущего содержимого в ОЗУ, которое расположено на том же кристалле, то есть можно считать, что в штатном режиме  (см. раздел
"Методы оценки вычислительных характеристик задач предметной области и поддерживающих их аппаратных платформ"
).
(см. раздел
"Методы оценки вычислительных характеристик задач предметной области и поддерживающих их аппаратных платформ"
).
Управление потоками данных в параллельных транспьютерных системах поддерживается альтернативными конструкциями языка ОККАМ в составе: enable channel, enable timer, alternative wait, disable channel, disable timer (соответственно допустимый канал (таймер), альтернативное ожидание и вышел из строя канал (таймер)). Механизм реализации следующий. Сначала выполняются инструкции enable channel или enable timer каждой программной компоненты, включенной в список диспетчеризации. Затем с помощью инструкции alternative wait из списка диспетчеризации исключается процесс, если ни один канал или таймер не готов. После этого выполняется инструкция disable channel или disable timer. Процесс возвращается в список диспетчеризации, если любой из обслуживающих его каналов или таймеров станет готовым.
При работе транспьютера с данными формата плавающей точки в IMS T800 использована традиционная адресная арифметика, когда адрес операнда хранится в стеке центрального процессора, а операнд загружается в стек процессора плавающей точки из адресуемой ячейки памяти (см. рис. 2.1). Формат float и double задаются специальным тегом, что сокращает число инструкций. В частности, вместо двух инструкций типа float add single и float add double достаточно одной доопределяемой тегом инструкции float add.
В программе, написанной на языке ОККАМ, программист должен в явном виде указать одно из двух ключевых слов: SEQ или PAR, первое из которых является директивой последовательного, а второе - параллельного выполнения нижележащих процессов. Но перед этим программист должен осуществить декомпозицию всей задачи на составляющие процессы, причем сделать это надо так, чтобы равномерно распределить вычислительную нагрузку между транспьютерами сети.
Наиболее общим методом проектирования программ реального времени является метод потока данных, в рамках которого конструируется диаграмма потоков данных, показывающая потоки, входящие в систему и выходящие из нее, а также преобразования над данными во время их прохождения через систему. Результатом такого конструирования является декомпозиция вычислительного алгоритма на составляющие процессы, которые можно выполнить либо последовательно, либо параллельно. Такую декомпозицию называют алгоритмической. Существуют также декомпозиции, основанные на структуре данных, на естественных свойствах фазового пространства физической системы ( геометрическая декомпозиция ) и т. п.
Во всех случаях цикл разработки программ практически одинаков и включает: редактирование текста программы, проверку текста программы на ошибки, компиляцию программных секций, отвечающих последовательным участкам программы, в машинные коды, компоновку отдельно скомпилированных секций кода, конфигурирование программы для ее выполнения в целевой сети, загрузку программы в целевую сеть и выполнение программы.
Главная особенность технологии конструирования параллельных ОККАМ-программ сосредоточена:
- в компоновке независимо скомпилированных фрагментов программ;
- в конфигурировании, в рамках которого программист готовит описание конфигурации, отображающее процессы на процессоры и каналы на реальные линии связи.
Компоновка независимо скомпилированных фрагментов программ удобна тем, что позволяет оперативно вносить дополнения и изменения в проект без его полной перекомпиляции.
Конфигурирование отдельных секций программы для транспьютерной сети сопряжено с появлением зацикливаний и тупиков, которые невозможно обнаружить при локальной отладке отдельных секций. Зацикливание приводит к тому, что несколько процессов замыкаются сами на себя и не выходят на связь с внешним миром. Тупики возникают в ситуациях "буриданова осла", когда каждый процесс ждет некоторого действия со стороны другого процесса. Устранение зацикливаний и тупиков требует наглядного отображения значений переменных и структур данных во время выполнения процесса. Но и в инструментальных, и в целевых аппаратных платформах в лучшем случае доступны только периферийные транспьютеры. Поэтому при отладке ОККАМ-программ, прошедших конфигурирование, программисту приходится встраивать модули, обеспечивающие прямую передачу данных от интересующих его периферийных к внутренним транспьютерам, и наоборот. Такое манипулирование структурой ОККАМ-программ уже предопределяет и нтерактивный режим работы инструментальной платформы на этапе конфигурирования и комплексной отладки.
Специфические особенности целевых аппаратных платформ вынуждают их производителей создавать инструментальные платформы, способные подержать программное конструирование только производимого ряда процессоров. Так, фирма Inmos, производящая транспьютеры, поставляет и систему разработки программ TDS ( Transputer Development System ), которая представляет собой интегрированную однопользовательскую среду разработки на базе компиляторов ОККАМ и инструментальной ЭВМ типа IBM PS с встроенной транспьютерной платой. На плате расположен один или несколько транспьютеров и блок буферной памяти, симулирующий режим реального времени процессов обмена данными с внешней средой.
Аналогичные по структуре и функциям инструментальные платформы поставляют производители ЦПОС и RISC -процессоров [70], при создании которых уже учтены базовые принципы разработки СБИС-архитектур: модульность, регулярность, локальность связей, массовый параллелизм и минимизированный ввод-вывод. Все эти принципы ориентированы на максимальное использование СБИС-технологий, для которых основным ограничением является аппаратно-временная стоимость межсоединений, которые занимают большую часть пространства кристалла и снижают тактовую частоту.
В идеале ЦПОС, RISC - и систолические проекты должны заканчиваться созданием кристалла матричной СБИС или системы на целой пластине, для чего требуется интегрированная программная среда проектирования. Входом такой среды является вычислительный и, как правило, рекурсивный алгоритм с параметрами потоков преобразуемых данных: количество операндов, обрабатываемых в одном цикле, период и точность обработки и т. п. Основу интегрированный среды составляет кремниевый компилятор, а интеллектуальная надстройка над ним призвана отобразить исходный алгоритм на матричную или иную структуру, адекватную граф-потоку сигналов. Совокупность кремниевого и структурного компиляторов представляет собой матричный компилятор, который должен удовлетворять следующим требованиям:
- дружественный интерфейс, основанный на графике;
- вход, описывающий поведение на языке высокого уровня;
- интерактивное взаимодействие с пользователем;
- иерархическая итерационная методология нисходящего и/или восходящего проектирования;
- согласованная база данных для всех уровней иерархии проекта;
- многоуровневое и смешанное моделирование;
- верифицируемость каждого уровня и конечный результат.
Иерархическая итерационная методология нисходящего и/или восходящего проектирования (рис. 2.3) предполагает выбор одной из альтернатив реализации: программируемые ЦПОС, RISC -процессоры или алгоритмически ориентированные систолические структуры и отображение алгоритма на структуру выбранных элементов, что требует методов и средств вскрытия и выражения векторно-конвейерного параллелизма, присущего исходному вычислительному алгоритму.
Методология поиска такого отображения сводится к следующему [70]. Сначала строится граф зависимости, что проще всего сделать для рекурсивных алгоритмов, для которых проще всего построить пространственно-временное индексное пространство, которое и отображается с помощью дуг. Затем строится граф-поток сигналов, который состоит из узлов обработки, ребер связи и задержек и который, как правило, представляет собой проекцию трехмерного индексного пространства на двумерный массив граф-потока сигналов. Для этого этапа разработана методология канонического и обобщенного отображения [70], отвечающая рис. 2.3. Наконец на завершающем этапе осуществляется разработка матричного процессора, где в силу вступает кремниевый компилятор, для которого синтезированный граф-поток сигналов является почти директивой.
Разработка матричного процессора заканчивается созданием среды программирования для пользователя (рис. 2.4), главная задача которого - вскрыть потенциальный параллелизм выбранного рекурсивного алгоритма.
Как показал опыт, для представления потенциального параллелизма больше подходят функциональные языки, так как традиционные процедурные языки типа Фортран контекстно соответствуют фон-неймановской модели вычислений, основанной на операторе присваивания и связанного с ним состояния процессора. Поэтому на таких языках, даже снабженных оптимизирующими и векторизирующими компиляторами, трудно выразить параллелизм, что требует преобразования исходного алгоритма в форму с однократным присваиванием. В языках типа ОККАМ программист в явном виде должен указать процессы, выполняемые последовательно и параллельно. Поэтому для достаточно обширной предметной области типа цифровая обработка сигналов и изображений были разработаны специальные языки типа SISAL (Streams and Iterations in a Single Assignment Language - потоки и итерации в языке с однократным присваиванием). SISAL имеет две формы цикла 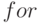 , одна из которых традиционна, а другая генерирует все пары индексов дл
я вычисления как декартова, так и скалярного произведения.
, одна из которых традиционна, а другая генерирует все пары индексов дл
я вычисления как декартова, так и скалярного произведения.
Однако для генерации кода возможностей функциональных языков недостаточно, так как граф зависимости оперирует абстрактными функциями узла, в то время как заранее изготовленные аппаратные платформы способны реализовать ограниченный список реальных функций. Для согласования затребованных и реализуемых функций в узле необходима информация о графе и о функциях, что требует синтеза графа структуры программы, в котором отражено распределение программных модулей между процессорами. Чтобы получить такое промежуточное представление вычислительного алгоритма, используются языки, основанные на ациклических графах типа IF1 [70].
Таким образом, приведенные данные позволяют заключить:
- Интерактивный режим является неотъемлемой частью как пользовательских инструментальных платформ, так и инструментальных платформ "собственных нужд", и он должен быть поддержан дружественным графическим интерфейсом.
- Центральную проблему представления, извлечения и реализации потенциального параллелизма, заложенного в вычислительный алгоритм, можно решить поэтапно и с помощью характерных для этого формальных средств, заложенных в специализированные языки программирования.
- Во всех без исключения параллельных вычислительных технологиях распределение нагрузки между процессорами или процессорными элементами фактически сводится к конструированию тела программы, загружаемой в целевую аппаратную платформу.
- Чем шире алгоритмическая база предметной области, тем более интенсивно используется интерактивный режим (микро)программного конструирования, так как область применения специализированных формальных методов представления и извлечения сужается до более простых программных секций.
- Ориентированные на максимально достижимый коэффициент распараллеливания вычислений алгоритмы с однократным присваиванием не учитывают ограничений целевой аппаратной платформы, так как предполагают организацию вычислений по типу "одна операция присваивания - один процессор требуемой структурно-функциональной сложности".
На практике даже вновь создаваемая целевая аппаратная платформа ограничена массо-габаритами и потребляемой мощностью и неспособна поддержать аппаратно каждый оператор присваивания и стоящую за ним вычислительную, коммутационную или управляющую функцию. В результате ее приходится использовать итеративно, что порождает синонимы одних и тех же переменных, устранить которые можно только на более высоком уровне организации вычислений.
Евгений Акимов