Опубликован: 23.05.2008 | Доступ: свободный | Студентов: 1565 / 389 | Оценка: 4.80 / 4.10 | Длительность: 15:29:00
Специальности: Программист
Теги:
Лекция 11:
Распределенное хранение информации
Аннотация: Распределенные базы данных, их отличие от централизованных баз. Фрагментация – горизонтальная и вертикальная. Репликация. Синхронные и асинхронные репликации. Протокол двухфазной фиксации транзакций. Схемы владения данными в распределенной БД
Ключевые слова: информация, база данных, БД, разделяемые данные, Локальные БД, связь, Интернет, предметной области, пользователь, группа пользователей, активный, обмен данными, распределенные базы данных, системы управления распределенными базами данных, DATE, базы данных, оптимизация запросов, реконфигурация системы, СУБД, структура организации, сущность предметной области, степень отношения, тип записи, принцип локальности, запрос удаления, фиксация транзакции, множество состояний, star
Источники информации часто, как говорилось ранее, находятся в различных точках физического пространства. Если информация из этих источников не используется сразу, а потребность в ней возникает лишь через некоторое время, возникает задача хранения информации, которая решается на основе аппарата баз данных. База данных является, таким образом, промежуточным звеном между источником и пользователем (потребителем) информации.
Если база данных находится в непосредственной окрестности источника и потребителя информации, то мы называем такую БД локальной. Если же БД находится от источника и/или потребителя на значительном расстоянии, требующем специальных технических средств передачи информации, то такую БД называют удаленной.
В том случае, если имеется несколько источников информации и баз данных, находящихся в удаленных друг от друга точках пространства, а также несколько пользователей, которым необходима информация из более чем одной БД, говорят о распределенной базе данных.
Точнее, под распределенной БД понимается набор логически связанных между собой разделяемых данных, которые распределены в физическом пространстве.
Распределенную БД можно представить как совокупность локальных БД (сайтов), связь между которыми обеспечена компьютерными сетями (в т.ч. Интернет). Данные во всех БД относятся к одной предметной области и, отчасти, функционально связаны между собой. С каждой из локальных баз связан пользователь или группа пользователей. Пользователь, кроме информации из "своей" БД, использует информацию и из другой (других) БД.
Для приближения информации к пользователю возможен и активный обмен данными между различными локальными БД – создание "зеркал" одних БД в других.
Для управления распределенной базой данных создается программный комплекс – система управления распределенной базой данных (СУРБД).
C. J. Date в 1987 году сформулировал один основной принцип и двенадцать правил, которым, по его мнению, должны следовать распределенные базы данных.
Основной принцип заключается в "прозрачности распределенности". С точки зрения пользователя информации распределенная БД не должна отличаться от локальной БД. Здесь имеется в виду пользователь, формулирующий запросы к базе данных и получающий результаты на своем экране (или принтере). Технология его работы не должна зависеть от того, в какой конкретной базе (на каком сайте) находятся нужные ему данные: в его локальной базе, в удаленной базе, все необходимые данные в одной и той же базе или в различных базах данных.
Первое правило требует автономности локальных баз данных, из которых состоит распределенная БД. Все локальные (принадлежащие именно этому сайту) данные и процессы должны контролироваться только этим сайтом.
Второе правило гласит, что в системе не должно быть критичного сайта, без которого система не может работать. Управление должно быть рассредоточенным, не должно быть некоего "центрального сайта", управляющего транзакциями, оптимизацией запросов, глобальным системным каталогом.
Третье правило – непрерывность работы. Реконфигурация системы (добавление и удаление локальных сайтов) не должна требовать остановки работы распределенной БД.
Четвертое, пятое и шестое правила декларируют независимость работы пользователя от расположения его сайта в общей системе, от фрагментации (разделения некоторого отношения на части, находящиеся на разных сайтах), от репликации (наличия копий фрагментов на тех или иных сайтах).
Седьмое правило касается распределенных запросов. Если выполнение запроса данных требует поиска данных не в одной локальной БД, а в нескольких локальных БД, то к этому не должно быть никаких препятствий.
Восьмое правило. Система должна поддерживать выполнение транзакций с сохранением их основных свойств: атомарности, согласованности, изолированности и продолжительности.
Правила девять – двенадцать декларируют независимость работы распределенной БД от аппаратного обеспечения, операционной системы, сетевой архитектуры и от типов СУБД, управляющих локальными базами. Последнее подразумевает, что локальные БД могут быть построены на основе различных моделей данных и с использованием различных типов СУБД, а СУРБД должна работать "поверх" этих СУБД.
Распределенному хранению информации свойственны те же недостатки, которыми обладают распределенные системы вообще: повышенная сложность и проблемы с защитой информации, иногда, увеличение стоимости за счет более сложного и дорогого программного обеспечения.
Но сохраняются и все достоинства: изоморфность структуре организации, повышение надежности системы в целом и, возможно, уменьшение стоимости за счет отсутствия критического " мощного центрального узла".
В то же время при разработке распределенных БД возникают специфические проблемы, отражающие их назначение как систем хранения информации.
Фрагментация
Реляционные базы данных хранят отношения – таблицы, состоящие из строк и столбцов. Строка отношения называется кортежем и представляет собой запись (record в смысле языка программирования, например, Pascal) о какой-либо сущности предметной области.
| Таб.№ | Фамилия | Имя | Отчество | Год рождения |
|---|---|---|---|---|
| А5 | Соловьев | Александр | Александрович | 1980 |
| Д16 | Фомин | Василий | Иванович | 1976 |
| Е4 | Зубова | Оксана | Петровна | 1980 |
| Б11 | Булатов | Александр | Иванович | 1984 |
Запись состоит из определенных полей. В одну таблицу сводятся записи о сущностях, имеющие одинаковую структуру (одинаковые по смыслу поля). Столбец отношения, т.е. имя поля и значения этого поля для разных сущностей называется атрибутом. При этом количество атрибутов (столбцов) называется степенью отношения, а количество кортежей (строк) – кардинальностью отношения.
Значения элементов в столбце принадлежат одной и той же области определения, называемой доменом. Например, домен для последнего столбца на рис. множество целых неотрицательных чисел. Если же иметь в виду, что в данное отношение включены работники некоторой организации, которым наверняка не более 100 лет, то домен можно определить как множество целых чисел из интервала [текущий год – 100, текущий год – 14]. Последнее число определяет то, что малолетние дети тоже не могут быть работниками. Каждому домену может быть присвоено имя (в программировании известны такие имена доменов как int, integer, real, float, char и др.).
Реляционной схемой называется имя отношения, за которым следует множество пар имен атрибутов и доменов. В программировании схеме соответствует определение типа записи. В целом же реляционная база данных – это набор нормализованных отношений.
В распределенной базе данных отношение может быть разделено на части, называемые фрагментами. Разделять отношение можно, "разрезая" таблицу по горизонтали, т.е. разделяя ее на подмножества кортежей, либо, "разрезая" по вертикали на подмножества атрибутов. В первом случае получаются горизонтальные фрагменты, во втором – вертикальные фрагменты. Возможна и смешанная фрагментация.
Фрагменты размещаются в различных локальных базах данных.
Причиной фрагментации является следование принципу локальности ссылок, в соответствии с которым данные, насколько это возможно, должны храниться как можно ближе к местам их использования и/или к местам их возникновения. Поскольку источники данных и пользователи привязаны к сайтам, находящимся в различных точках физического пространства, а реляционные схемы, которыми они пользуются, могут быть одинаковы, возникает естественная фрагментация.
Если по различным сайтам распределена информация о различных сущностях предметной области, то возникает горизонтальная фрагментация. Если об одних и тех же сущностях на разных сайтах имеется информация разного рода (известны значения разных атрибутов), то возникает вертикальная фрагментация.
Фрагментация может возникать и в связи с конфиденциальностью информации. Например, некоторые атрибуты кортежей могут быть доступны только с определенного сайта и храниться на этом сайте. Скажем, атрибут, отражающий состояние здоровья работника, доступен только в медицинской части организации. Получаем вертикальную фрагментацию.
Фрагментация обладает очевидными недостатками, для преодоления которых нужно прибегать к специальным мерам.
Первый недостаток заключается в усложнении поддержки целостности данных, второй – в снижении производительности приложений, использующих данные, находящиеся в различных фрагментах.
Репликация
Под репликацией понимается создание копий некоторых фрагментов отношений и одновременное хранение нескольких копий на разных сайтах (в разных локальных БД). Репликация используется для того, чтобы "приблизить" данные с "чужого" сайта к месту их использования. Распределенные запросы позволяют пользователю, находящемуся на сайте i, выполнять приложения с данными, находящимися как на сайте i, так и на сайтах j, k, l, … Однако, каждый такой запрос удаленных данных требует очень большого (по сравнению с местным запросом) времени. Если предполагается выполнение большого количества удаленных запросов, то более выгодным оказывается предварительно переместить (скопировать) необходимые фрагменты локальных баз данных с сайтов j, k, l, … на сайт i. Подобное решение используется и при разработке архитектуры аппаратной части компьютеров. Там оно называется кэшированием.
Репликация способствует и повышению надежности хранения данных, поскольку одни и те же данные хранятся в разных местах. Репликация особенно важна для тех сайтов, которые работают в режиме повышенной нагрузки, с большим количеством входящих запросов. Она позволяет снизить нагрузку на эти сайты за счет возможного распараллеливания.
Репликация приводит и к определенным трудностям. Локальные БД постоянно обновляются. В них поступают новые данные, старые данные могут исключаться. Это приводит к тому, что 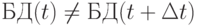 через некоторый период времени
через некоторый период времени  Следовательно, копия БД(t) становится не актуальной, и ее использование может привести к ошибочным результатам запросов.
Следовательно, копия БД(t) становится не актуальной, и ее использование может привести к ошибочным результатам запросов.
Выход может состоять в том, чтобы одновременно с локальной базой данных обновлять и все копии этой БД или ее фрагментов.
Применяются синхронные и асинхронные репликации.
Наилучшей с точки зрения актуальности копий является синхронная репликация. При этом все обновления (исходной базы и копий) производятся как часть одной транзакции обновления, т.е. практически одновременно. Во всяком случае, обновление исходной базы не считается завершенным, пока не произведены изменения в копиях.
При асинхронной репликации изменения проводятся сначала в исходной БД, а вслед за этим, возможно, через значительный период времени – в копиях, т.е. какое-то время данные остаются не согласованными.
Для проведения синхронной репликации можно использовать следующий алгоритм (протокол) двухфазной фиксации транзакций.
Исполнители алгоритма:
- Менеджер сайта – владельца исходной БД (обозначим его M).
- Менеджеры сайтов – хранителей копий фрагментов БД, mj. Множество этих менеджеров обозначим S.
Состояния исполнителей:
Множество состояний менеджера M имеет вид QM = {инициализация, ожидание, обновление, завершено}.
Множества состояний менеджеров mj имеют одинаковый вид Qm = {инициализация, готов, не готов, выполнено}. Но каждый менеджер имеет свой экземпляр этого множества.
Операции, выполняемые менеджерами.
Менеджер M выполняет следующий набор операций:
- start – начать транзакцию;
- send – послать сообщения менеджерам mj ;
- write – записать информацию в свой журнал;
Менеджеры mj выполняют следующий набор операций:
- send – послать сообщения менеджеру M ;
- write – записать информацию в свой журнал;
- put – поместить результаты транзакции в свою копию БД.
Для нашей задачи структуру связей между исполнителями алгоритма можно описать как звезду star(M, S) с центральной вершиной M и множеством периферийных вершин S.
Протокол двухфазной фиксации транзакций состоит из взаимодействующих путем передачи сообщений алгоритмов (рутин) отдельных исполнителей. Здесь приведен упрощенный вариант протокола.
routine M
initial
состояние сайта := "инициализация"
endi
event
if message.code = "включить данные в БД" then
begin
start; write("начало транзакции");
L := 0;
out "приготовиться к изменениям";
состояние сайта := "ожидание";
schedule (TimeOut, T)
end
else if message.code = "готов" then
begin
Include(L, message.id);
if L = S then
begin
L := 0; out "общее обновление";
состояние сайта := "обновление"
end
end
else if message.code = "выполнено" then
begin
Include(L, message.id);
if L = S then
begin
write("транзакция завершена");
состояние сайта := "завершено"
end
end
else if message.code = "не готов" then
begin
write("не готов менеджер копии");
out "общий возврат";
end
else if message.code = "не выполнено" then
begin
write("не выполнил менеджер копии");
out "общий возврат";
end
else if message.code = "отказ принят" then
begin
Include(L, message.id);
if L = S then
begin
write("отказы подтверждены");
состояние сайта := "завершено"
end
end
endc
ende;
event TimeOut;
write("время истекло");
состояние сайта := "завершено";
out "общий возврат";
ende.
11.1.
Ольга Космодемьянская
|
Я прошла курс "Распределенные системы и алгоритмы". Сдала экзамен экстерном и получила диплом. Вопрос: можно ли после завершения теста посмотреть все вопросы, которые были на экзамене и все варианты ответов? Мне это необходимо для отчета преподавателю в моем ВУЗе. Заранее спасибо! |