Тверской государственный университет
Опубликован: 03.10.2011 | Доступ: свободный | Студентов: 3284 / 60 | Оценка: 4.33 / 3.83 | Длительность: 19:48:00
ISBN: 978-5-9963-0573-5
Тема: Программирование
Специальности: Программист, Системный архитектор
Теги:
Лекция 4:
Основы структуры программ
3.6. Абстрактные синтаксические деревья
Для больших программных текстов более подходит другая структура, отражающая синтаксис. Она основана на понятии "дерева", часто используемого для отображения организационной структуры компании. Это понятие ассоциируется с настоящими деревьями, их ветвями и листьями. Правда, у наших деревьев, в отличие от настоящих, корень дерева располагается вверху и дерево "растет" сверху вниз или слева направо. Дерево имеет корень, ветви которого идут к другим узлам, а те, в свою очередь, могут иметь ветви, или быть листом дерева. Деревья служат для представления иерархических структур, как показано ниже:
Рисунок представляет абстрактное синтаксическое дерево. Оно абстрактно, поскольку не включает элементы, играющие роль разделителей, такие как do и end. Мы можем построить конкретное синтаксическое дерево, включающее такие элементы.
Дерево включает узлы и ветви (вершины и дуги). Каждая ветвь связывает один узел с другим. У данного узла может быть несколько выходящих ветвей, но в каждый узел ведет максимум одна ветвь. Узел, у которого нет входящей в него ветви, называется корнем. Узлы без выходящих ветвей называются листьями. Узел, не являющийся ни корнем, ни листом, называется внутренним узлом.
Непустое дерево имеет в точности один корень (структура, представленная нулем, одним или несколькими раздельными деревьями, имеющая произвольное число корней, называется лесом).
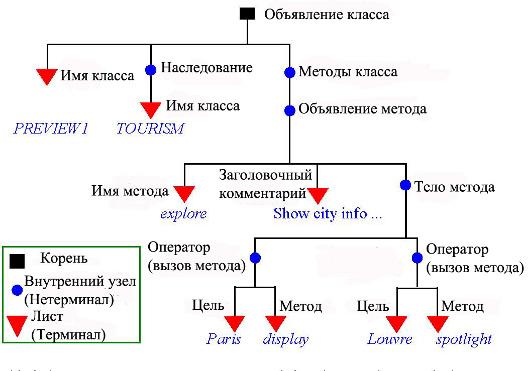
Деревья являются важными структурами в информатике, нам часто придется с ними встречаться в разных контекстах. Здесь мы рассматриваем их как деревья, задающие структуру синтаксиса элемента программы – класса. Она представлена вложенными образцами с тремя видами узлов.
- Корень, представляющий общую структуру, – самый внешний прямоугольник на предыдущем рисунке.
- Внутренние узлы, которые представляют подструктуры, содержащие вложенные образцы – например, вызов метода содержит цель и имя метода.
- Листья, представляющие образцы, которые не содержат последующих вложений, такие как имена классов и методов.
Листья абстрактного синтаксического дерева называются также терминалами, а корень и внутренние узлы – нетерминалами.
Каждый образец относится к специальному виду: верхний узел задает класс, другие представляют имя класса, предложение "наследования", множество объявлений методов. Каждый такой вид образца является грамматической категорией. На рисунке дерева для каждого узла приведено имя категории. Категория может быть как терминальной, так и нетерминальной, что зависит от образцов, представляющих категорию. Рисунок показывает, что "Объявление метода" является нетерминальной категорией, а имя метода – терминальной.
Категория определяет общее синтаксическое понятие. Синтаксис языка программирования определяется множеством категорий и их структурой.
3.7. Лексемы и лексическая структура
Базисными составляющими синтаксической структуры являются терминалы, ключевые слова, специальные символы, такие как точка в вызове метода. Эти базисные элементы называются лексемами (tokens).
Лексемы подобны словам и символам обычного языка. Предложение "Ах, ох – это восклицания!" содержит четыре слова и три символа.
Виды лексем
- Терминалы соответствуют, как мы видели, листьям абстрактного синтаксического дерева, каждое из которых несет некоторую семантическую информацию. Они включают имена, такие как Paris или display, называемые идентификаторами и выбираемые каждым программистом для именования семантических элементов, например, объектов (Paris) и методов (display). Другими примерами являются знаки операций, такие как + и <=, появляющиеся в выражениях, и литеральные константы, обозначающие значения с самообъявлением, например, целое 34. Синтаксис литеральных констант строится так, чтобы по их записи однозначно определялся их тип.
- Ограничители играют чисто синтаксическую роль и не несут никакой семантики. Они включают 65 ключевых слов, таких как class, inherit, feature, и специальные символы, например, точку и двоеточие. Они не появляются в абстрактном синтаксическом дереве, но появятся как листья при построении конкретного синтаксического дерева.
Уровни описания языка
Форма лексем определяет лексическую структуру языка. Синтаксический уровень является надстройкой – более высоким уровнем по отношению к лексическому, а семантический уровень выше синтаксического.
- Лексические правила определяют, как создаются лексемы из символов.
- Синтаксические правила определяют, как создаются образцы из лексем, удовлетворяющих лексическим правилам.
- Семантические правила определяют эффект программ, удовлетворяющих синтаксическим правилам.
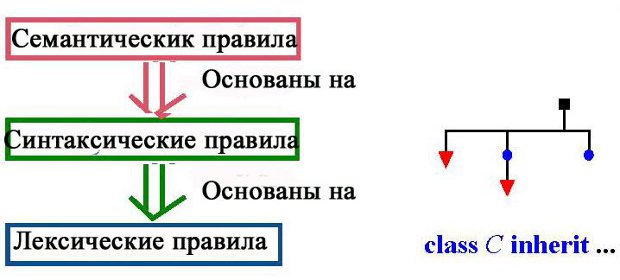
Важной особенностью этой иерархии является то, что свойства любого уровня определены только при условии выполнения ограничений на предыдущих уровнях. Синтаксис определен только для лексически корректных текстов, а семантика существует только для синтаксически корректных программ.
Мы встретимся с еще одним специальным уровнем, лежащим между синтаксисом и семантикой: обоснованием (validity), на котором рассматриваются правила, не относящиеся к синтаксису, например, ограничения типа.
Идентификаторы
На данный момент нам необходимо только одно лексическое правило для идентификаторов.
Синтаксис: идентификаторы
Идентификатор начинается с буквы, за которой следует ноль или более символов, каждый из которых может быть:
- буквой;
- цифрой (0-9);
- символом подчеркивания "_".
Примером идентификатора, содержащего цифры, является Route1
Действует одно исключение: нельзя использовать в роли идентификаторов ключевые слова, зарезервированные для специальных целей (на данный момент нам известно лишь несколько ключевых слов, но, если ошибочно мы попытаемся использовать в роли идентификатора ключевое слово, появится сообщение об ошибке).
Почувствуй стиль
Выбирая идентификаторы
Для повышения читабельности программ выбирайте идентификаторы, четко идентифицирующие предполагаемую роль, за исключением специальных случаев, которые вскоре рассмотрим. Используйте полные имена, а не аббревиатуры: Route1, а не R1 или Rte1.
Нет налога на нажатие клавиш. Те несколько секунд, которые вы, возможно, сэкономите, опустив несколько символов, ничего не стоят в сравнении с тем временем, когда вам или кому-либо другому понадобится понять, что же делается в вашей программе.
В идентификаторах, обозначающих сложные понятия, используйте подчеркивание для разделения последовательности слов, как в My_route или bus_station. Это относится и к именам классов, записываемых в верхнем регистре: PUBLIC_TRANSPORT. Не переусердствуйте: для большинства идентификаторов достаточно одного слова или двух слов, соединенных подчеркиванием. Ясность не означает многословие.
В некоторых программах, хотя для программ на Eiffel это не так, можно встретиться с многословными идентификаторами, в которых каждое следующее слово начинается с заглавной буквы: myRoute, PublicTransport. Это соглашение называется верблюжьим стилем (camel style) из-за возникающего горба. Лучше не следовать этому стилю, поскольку "онНамногоХужеЧитается", чем стиль с подчеркиванием, "остающийся_совершенно_ясным_даже_для _длинных_идентификаторов".
Уровни описания языка
Лексическая структура состоит из последовательности лексем. Для разделения соседствующих лексем можно использовать "белый пробел" (break), который может быть:
- пробелом;
- символом табуляции (задающим последовательность пробелов, которая позволяет перейти к фиксированной позиции в строке);
- символом перехода на новую строку.
Белые пробелы служат только для разделения лексем. Для синтаксиса и семантики нет разницы, как вы разделяете лексемы. Разрешается использовать один или несколько пробелов, переходы на новую строку или табуляцию. Такая гибкая структура, известная как "свободный формат", позволяет вам создать раскладку текста программы, отражающую структуру программы, что улучшает читабельность программы, как это сделано в примерах курса.
Ваша программа хранится в файле, который содержит последовательность символов, таких как буквы, цифры, знаки табуляции и другие специальные символы. Для большинства используемых сегодня файловых форматов для перехода на новую строку применяется один специальный символ "новая строка". Возможно, вы встречались и с символом "перевода каретки" (Carriage Return). Это название пришло из прошлого, когда тексты печатались на пишущей машинке, каретка смещалась в процессе печати строки и для перехода на новую строку необходимо было предварительно вернуть каретку в начальную позицию. В операционной системе Windows переход на новую строку кодируется последовательностью двух символов – возврата каретки и новой строки.
Белый пробел обычно не требуется между идентификатором и символом: можно писать a+b без всяких пробелов, поскольку не возникает двусмысленности. Однако правила стиля требуют использования белых пробелов для улучшения ясности текста: a + b.
3.8. Ключевые концепции, изученные в этой лекции
- Для записи программ используются языки программирования.
- Программы имеют лексическую структуру, определяющую форму базисных элементов. Лексемы разделяются "белыми" пробелами – табуляцией, возвратом строки, пробелом.
- Программы имеют синтаксическую структуру, которая определяет иерархическую декомпозицию на элементы (образцы), построенные из лексем.
- Программы имеют семантику, определяющую эффект времени выполнения каждого образца и всей программы в целом.
- Синтаксическая структура обычно включает вложенность и может быть задана в виде дерева, известного как абстрактное синтаксическое дерево.
Новый словарь
3-У. Упражнения
3-У.1. Словарь
Дайте точные определения терминам словаря.
3-У.2. Карта концепций
Добавьте новые термины в карту концепций, спроектированную в предыдущей лекции.
3-У.3. Синтаксис и семантика
Для каждого из следующих предложений укажите, характеризуют ли они синтаксис, семантику, то и другое, ни то, ни другое (объясните решение).
- При вызове метода целевой объект должен отделяться точкой от имени метода.
- При вызове метода x.f нет необходимости помещать пробелы перед или после точки, хотя они являются допустимыми.
- Каждый вызов метода применяет метод к определенному объекту – цели вызова.
- Если у метода есть аргументы, то они должны заключаться в круглые скобки.
- Два или более аргумента заданного типа разделяются запятыми.
- Операторы, разделенные символом "точка с запятой", будут выполняться один после другого.
- Eiffel и Smalltalk являются объектно-ориентированными языками.