Повышение производительности запроса
Использование покрывающих индексов
Не всегда нужно, чтобы при использовании некластеризованных индексов SQL Server на втором этапе извлекал всю строку. Эта ситуация возникает, когда некластеризованный индекс включает все данные таблицы, которые нужно SQL Server для выполнения операции. Когда это происходит, мы называем индекс покрывающим, потому что этот индекс покрывает весь запрос. Покрывающие индексы могут существенно увеличить производительность запроса; в этом легко убедиться на двух планах запросов из предыдущего примера. В таких запросах стоимость операторов, которые извлекают нужные строки данных, составляет 97% всей стоимости запроса. Другими словами, запрос без этой операции будет выполнен в 32 раза быстрее. Давайте рассмотрим, как работают покрывающие индексы.
Применяем покрывающие индексы
- Запустите SQL Server Management Studio, Откройте окно New Query (Создать запрос) и измените контекст базы данных на Adventure Works.
- Идея покрывающих индексов заключается в том, что они содержат все данные, необходимые для выполнения запросов. Если мы посмотрим на первый из следующих запросов, который уже использовался в предыдущем примере, то увидим, что SQL Server нужны столбцы SalesOrderID, CarrierTrackingNumber и ProductID.
Некластеризованный индекс NCLIX_OrderDetails_ProductID, который мы создали ранее, включает столбец ProductID, поскольку он построен на этом столбце, а также столбец SalesOrderID, поскольку этот столбец является ключевым столбцом кластеризованного индекса. Поэтому SalesOrderID является указателем, который SQL Server использует в некластеризованном индексе. Следовательно, серверу SQL Server, чтобы получить CarrierTrackingNumber, нужно возвратить строки данных, выполнив поиск (метод seek) только по кластеризованному индексу. Во втором запросе столбца CarrierTrackingNumber нет в списке SELECT. Введите и выполните инструкцию, включив действительный план выполнения, чтобы увидеть разницу. Код этого примера имеется в файлах примеров под именем Using Covered Indexes.sql.
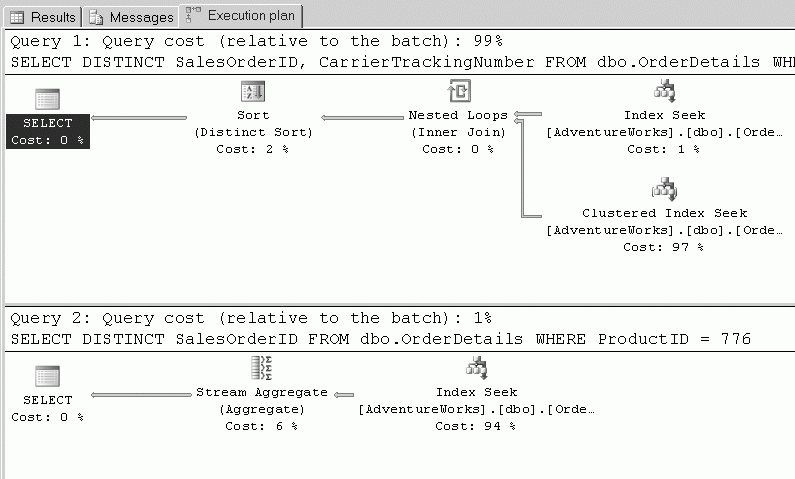
SET STATISTICS IO ON -не покрывающий SELECT DISTINCT SalesOrderID, CarrierTrackingNumber FROM dbo.OrderDetails WHERE ProductID = 776 -покрывающий SELECT DISTINCT SalesOrderID FROM dbo.OrderDetails WHERE ProductID = 776 SET STATISTICS IO OFF
На рисунке, показанном ниже, видно, что серверу SQL Server для выполнения второго запроса нужно обратиться к кластеризованному индексу, потому что индекс покрывает запрос, если столбец CarrierTrackingNumber не выбран. Поскольку доступ к кластеризованному индексу для каждой строки очень дорого стоит, второй запрос составляет только 1% от общей стоимости пакета. Посмотрев на вкладку Messages (Сообщения), мы видим, что для того,. чтобы покрыть запрос, SQL Server нужно выполнить только 2 считывания страницы (вместо 709 считываний, необходимых для первого запроса).
Вы убедились, что покрывающий индекс может дать большой выигрыш в скорости выполнения. Конечно, невозможно удалить столбцы из запроса, если они нужны в результате. Но по общему правилу следует извлекать только те столбцы, которые вам действительно нужны, чтобы сделать более вероятным применение покрывающего индекса. Не следует использовать в инструкции SELECT символ звездочки (*) только потому, что так проще составить запрос.
- Предположим, что столбец CarrierTrackingNumber нужен в запросе, но из соображений производительности следует использовать покрывающий индекс. В SQL Server 2005 можно включить этот столбец в некластеризованный индекс. Включенные столбцы сохраняются в ключах индекса на уровне листовых вершин некластеризованного индекса, что устраняет необходимость извлекать их из кластеризованного индекса. Чтобы включить столбец CarrierTrackingNumber в некластеризованный индекс, введите и выполните следующую инструкцию для удаления (DROP) индекса и повторного создания ( CREATE ) индекса с включенным столбцом.
DROP INDEX dbo.OrderDetails.NCLIX_OrderDetails_ProductID CREATE INDEX NCLIX_OrderDetails_ProductID ON dbo.OrderDetails(ProductID) INCLUDE (CarrierTrackingNumber)
- Выполните первый неохваченный запрос, чтобы посмотреть, будет ли он охвачен теперь.
SET STATISTICS IO ON SELECT DISTINCT SalesOrderID, CarrierTrackingNumber FROM dbo.OrderDetails WHERE ProductID = 776 SET STATISTICS IO OFF
Взглянув на план выполнения, вы увидите, что доступ к кластеризованному индексу больше не нужен. На вкладке сообщений видно, что для выполнения этого запроса теперь требуется только 5 считываний страниц, тогда как раньше требовалось 709.
 Примечание. Включенные столбцы вызывают перегрузку сервера SQL Server при изменении данных, потому что SQL Server приходится изменять каждый индекс и еще потому, что для их хранения требуется больше места в файлах данных. Следовательно, включение столбцов в некластеризованные индексы - это хороший способ повышения производительности запросов, но не следует создавать индексы с включением столбцов для всех запросов в приложении. Эту функцию следует использовать исключительно для ускорения выполнения проблемных запросов.
Примечание. Включенные столбцы вызывают перегрузку сервера SQL Server при изменении данных, потому что SQL Server приходится изменять каждый индекс и еще потому, что для их хранения требуется больше места в файлах данных. Следовательно, включение столбцов в некластеризованные индексы - это хороший способ повышения производительности запросов, но не следует создавать индексы с включением столбцов для всех запросов в приложении. Эту функцию следует использовать исключительно для ускорения выполнения проблемных запросов.
Индексы в вычисляемых столбцах
В таблице dbo.OrderDetails у нас есть вычисляемый столбец LineTotal, который представляет значение LineTotal для строки и вычисляется по следующей формуле:
(isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0)))
При каждом доступе к этому столбцу SQL Server вычисляет значения на основе значений оригинальных строк, на которые ссылается формула. Этот процесс не представляет собой проблемы до тех пор, пока столбец LineTotal используется в предложении SELECT, но если использовать LineTotal в предикате поиска предложения WHERE или в агрегатных функциях, например, MAX или MIN, такая проблема может возникнуть. Если вычисляемые столбцы используются для поиска, SQL Server должен вычислять значения для каждой строки в таблице, и только потом искать в результатах нужные строки. Это очень неэффективный процесс, потому что здесь всегда требуется просмотр таблицы или полный просмотр кластеризованного индекса. Для этих видов запросов можно создать индексы в вычисляемых столбцах. Когда в вычисляемом столбце создан индекс, SQL Server вычисляет результат заранее и создает по нему индекс.
Примечание. Существуют некоторые ограничения на создание индексов в вычисляемых столбцах. Главное из них заключается в том, что вычисляемые столбцы должны быть детерминированными и прецизионными. Дополнительную информацию об этих ограничениях можно найти в Электронной документации SQL Server 2005 в теме "Создание индексов в вычисляемых столбцах".Создаем и используем индексы в вычисляемых столбцах
- Запустите SQL Server Management Studio. Откройте окно New Query (Создать запрос) и измените контекст базы данных на Adventure Works.
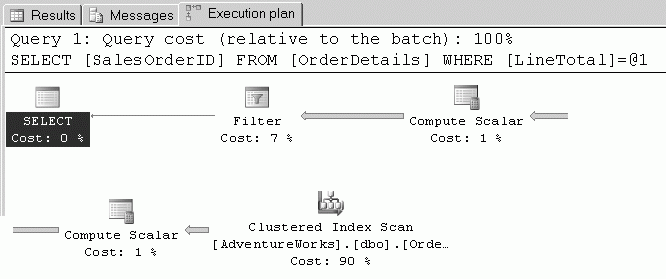
- Представьте себе, что вы хотите возвратить все значения SalesOrderID s, для которых LineTotal имеет определенную величину. Введите следующий запрос и нажмите (Ctrl+L), чтобы отобразить предполагаемый план выполнения для случая, когда в вычисляемом столбце не существует опорного индекса. Как видите, SQL Server должен выполнить просмотр кластеризованного индекса, вычислить значения в столбце и отфильтровать эти значения до нужных строк. Код этого примера можно найти среди файлов примеров под именем IndexesOnComputedColumns.sql.
SELECT SalesOrderID FROM OrderDetails WHERE LineTotal = 27893.619
- Введите и выполните следующую инструкцию CREATE INDEX, чтобы создать индекс в вычисляемом столбце:
CREATE NONCLUSTERED INDEX NCL_OrderDetail_LineTotal ON dbo.OrderDetails(LineTotal)
- Выделите первый запрос и нажмите (Ctrl+L), чтобы отобразить новый план выполнения запроса с индексом в вычисляемом столбце. Как показано ниже, SQL Server теперь использует вновь созданный индекс для извлечения данных, что повышает скорость выполнения запроса по сравнению с предыдущим случаем.
SELECT SalesOrderID FROM OrderDetails WHERE LineTotal = 27893.619
- Закройте окно среды SQL Server Management Studio.